










节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
汇总合集
《大模型面试宝典》(2024版) 发布!
《大模型实战宝典》(2024版) 发布!
本文将从模型背景、模型介绍、模型应用三个方面,带您一文搞懂Swin Transformer:屠榜各大CV任务的视觉Transformer模型。

Swin Transformer
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2040,备注:技术交流+CSDN
用通俗易懂的方式讲解系列
模型背景
在计算机视觉领域,虽然卷积神经网络(CNN)长期以来一直是主导架构,但近年来,随着Transformer在自然语言处理(NLP)领域的显著成功,越来越多的研究开始探索将Transformer应用于视觉任务的可能性。这种转变不仅为计算机视觉带来了新的建模方法,还引发了关于两种架构优缺点的深入讨论。
CNN及其变体
卷积神经网络(Convolutional Neural Network):
CNN是一种包含卷积计算且具有深度结构的前馈神经网络,具有强大的图像和序列数据处理能力,广泛应用于图像识别、计算机视觉等领域。

卷积神经网络(CNN)
CNN变体:
卷积神经网络的变体和改进模型不断涌现,以下是一些主要的CNN变体:
-
AlexNet:这是CNN在计算机视觉领域取得突破性进展的里程碑。它首次在ImageNet大规模图像识别挑战赛上取得了显著成功。
-
VGG Net:这是一个非常深的CNN架构,以其简洁而易于理解的设计而闻名。VGG网络通过堆叠多个3x3的卷积核来增加网络的深度。
-
DenseNet:这是一种更高效的深度卷积网络,其主要特点是通过稠密连接来连接每一层与其他所有层。
-
GoogLeNet(或Inception Networks):GoogLeNet引入了“Inception”模块。这是一种结构更加复杂的卷积网络,其主要特点是通过多种不同尺寸的卷积核来提取图像特征。
-
ResNet(Residual Networks):ResNet通过引入残差连接(Residual Connection)来解决深度神经网络中的梯度消失和退化问题。
每种变体都有其独特的特点和优势,研究者可以根据具体任务和数据集的特点选择合适的模型。
CNN变体

CNN成功的原因:
卷积神经网络在视觉任务中之所以成功,主要归因为以下两点:
-
有效地捕获图像的局部空间结构信息:局部感知的方式与人眼观察图像的方式类似,使得CNN能够专注于图像中的关键细节。
-
通过卷积操作实现特征的层次化提取:利用卷积操作对图像进行特征提取,通过堆叠多个卷积层,能够逐层提取出从低级到高级、从具体到抽象的特征。

自注意力 + CNN
自注意力补充CNN:
自注意力机制,特别是局部自注意力,可以在CNN的基础上提供额外的上下文信息。在CNN的某些层之后或之间添加,以提供额外的注意力权重。这样可以指导CNN模型关注图像中更重要的部分,从而提高模型的性能。
SENet(Squeeze-and-Excitation Networks):
通过在CNN中引入自注意力机制改进模型的性能。SENet的核心思想是为每个卷积层的特征通道分配不同的权重,以强调重要的特征并抑制不重要的特征。

SENet核心模块
CBAM (Convolutional Block Attention Module):
结合了通道注意力和空间注意力,可以同时关注“什么”和“哪里”的问题。在CNN的卷积块后添加CBAM模块,可以帮助模型在空间和通道两个维度上关注重要的特征。

SENet核心模块
基于Transformer的视觉主干网络
Vision Tranformer(ViT):
ViT将Transformer架构从自然语言处理领域引入到计算机视觉中,用于处理图像数据。
ViT的核心思路是将图像视为一系列图像块(“视觉单词”或“tokens”),而不是连续的像素数组。

Vision Transformer
图像块(Image Patches):
-
ViT首先将输入图像切分为多个固定大小的图像块(patches)。
-
这些图像块被线性嵌入到固定大小的向量中,类似于NLP中的单词嵌入。
-
每个图像块都被视为一个独立的“视觉单词”或“tokens”,并用于后续的Transformer层中进行处理。

图像块(Image Patches)
Vision Transformer(ViT)的架构图:
ViT的架构如图所示:

ViT的架构图
Vision Transformer(ViT)的核心模块:

ViT的核心组件分为5部分:Patch Embeddings,Position Embeddings,Classification Token,Linear Projection of Flattened Patches,以及Transformer Encoder。
-
Patch Embeddings:如上图虚线的左半部分,我们将图片分成固定大小的图像块patches(如图左下9×9的图像),将它们线性展开。
-
Position Embeddings:Position embeddings加到图像块中是为了保留位置信息的。
-
Classification Token:为了完成分类任务,除了以上九个图像块,我们还在序列中添加了一个*的块0,叫额外的学习的分类标记Classification Token。
-
Linear Projection of Flattened Patches:图像分割为固定大小的图像块(patches)后,将每个图像块展平(flatten)为一维向量,并通过一个线性变换(即线性投影层或嵌入层)将这些一维向量转换为固定维度的嵌入向量(patch embeddings)。
-
Transformer Encoder:由多个堆叠的层组成,每层包括多头自注意力机制(MSA)和全连接的前馈神经网络(MLP block)。

ViT的Transformer Encoder
Vision Transformer(ViT)的工作流程:
将图像分割为固定大小的图像块(patches),将其转换为Patch Embeddings,添加位置编码信息,通过包含多头自注意力和前馈神经网络的Transformer编码器处理这些嵌入,最后利用分类标记进行图像分类等任务。

模型介绍
Swin Transformer是一种新型的Transformer架构,专为计算机视觉任务而设计。它引入了基于移动窗口的自注意力机制,并采用了层级式的特征表达方式,使得模型在计算复杂度和性能之间取得了平衡。

Swin Transformer
Swin Transformer 模型在论文Swin Transformer: Hierarchical Vision Transformer using Shifted Windows中提出。

Swin Transformer:使用移位窗口的分层视觉Transformer
模型思路
Vision Transformer(ViT)的局限:
Vision Transformer(ViT)作为一种将Transformer从语言领域应用到视觉领域的模型,挑战来自于两个领域的差异:
-
视觉实体的规模变化很大:
在自然语言中,单词的长度和频率都是相对稳定的,但在视觉领域,不同物体的尺寸和比例可能会有很大的变化。
由于ViT将图像切分为固定大小的patches,当物体的尺寸远小于或远大于这些patches时,ViT可能无法有效地提取到有用的特征信息。
-
图像中的像素相对于文本中的单词的分辨率较高:
文本数据通常是一维的,而图像数据则是二维的,并且图像中的像素数量通常远大于文本中的单词数量。
这使得ViT在处理图像时需要处理更多的数据,并需要更多的计算资源,导致模型训练变得更加困难。
Swin Transformer的思路:
Swin Transformer,一个使用移动的窗口计算的分层Transformer。移位窗口方案将自注意计算限制在非重叠的局部窗口上,同时允许跨窗口连接,从而提高了效率。
核心思路:层次化结构和偏移窗口机制。

Swin Transformer
Swin Transformer偏移窗口机制:解决 ViT 局限一,视觉实体的规模变化很大
Swin Transformer计算自注意力时使用的偏移窗口机制,通过窗口划分发生偏移,形成了新的窗口。新窗口中的自注意力计算跨越了先前窗口的边界,从而在这些窗口之间建立了连接。Swin Transformer解决了在视觉实体规模变化很大的情况时,ViT不能有效提取有用的特征信息。

Swin Transformer偏移窗口机制
Swin Transformer层次化结构:解决 ViT 局限二,图像中的像素相对于文本中的单词的分辨率较高
Vision Transformer(ViT)只能生成单一低分辨率的特征映射,全局计算自注意力时复杂度非常高,难以处理高分辨率图像。
而Swin Transformer通过层次化结构,在更深的层中合并图像块(以灰色显示)来构建层次化的特征映射,仅在每个局部窗口(以红色显示)内计算自注意力,大大降低了输入图像大小的计算复杂度,能够高效处理高分辨率图像。

Swin Transformer层次化结构
模型架构
Swin Transformer的架构图:
Swin Transformer架构通过引入层次化结构和偏移窗口机制,实现了在保持计算效率的同时,增强模型对多尺度特征的捕获能力。Swin Transformer的架构如图所示:

Swin Transformer的架构图
Swin Transformer的核心组件:
Swin Transformer 的核心组件包括 Patch Embedding(Patch Partition + Linear Embedding),Swin Transformer Block,以及 Patch Merging。
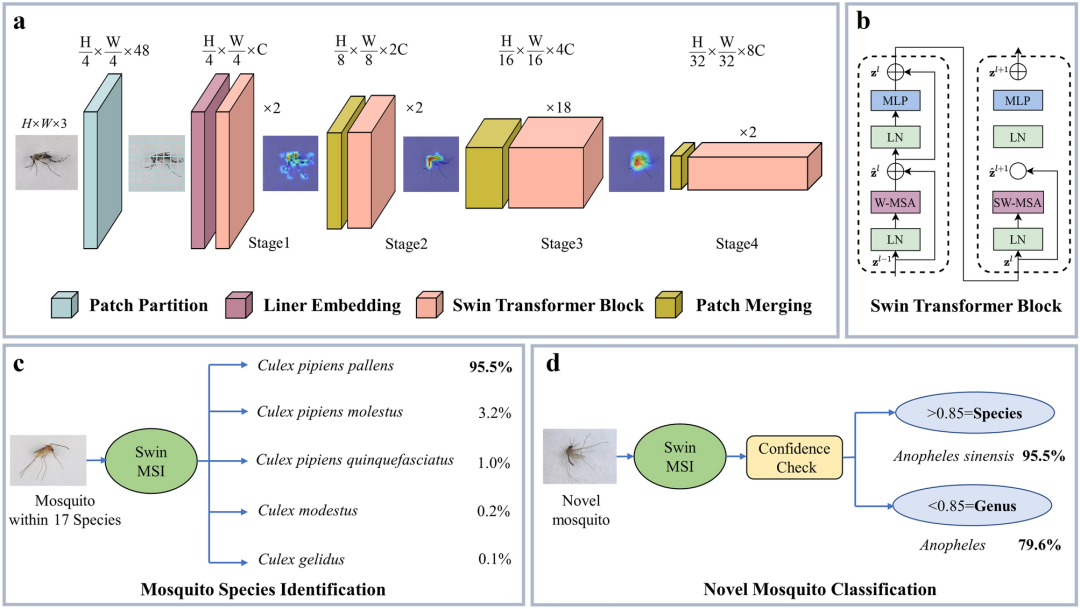
Swin Transformer的核心组件
-
Patch Embedding:Pacth Partition + Linear Embedding,这个过程类似于Vision Transformer(ViT)中的patch embedding步骤。
-
Pacth Partition:Patch分割模块将输入的RGB图像分割成一系列非重叠的图像块(patches)。
-
Linear Embedding:线性嵌入层将每个patch被视为一个token,并通过线性嵌入层将其原始像素值转换为具有固定维度的特征向量。
-
Swin Transformer Block:Swin Transformer块
结合了多头自注意力机制和多层感知机。通过堆叠多个Swin Transformer Block,模型能够逐步提取并转换图像的特征。
-
Patch Merging:块合并层通过将相邻的块(patches)合并成一个更大的块,来缩小特征图的尺寸,并在合并的过程中增加通道数,从而构建出层次化的特征表示。

Swin Transformer的核心组件
Swin Transformer Block:
Swin Transformer是通过将Transformer块中的标准多头自注意力(MSA)模块替换为基于移位窗口的模块来构建的,其他层保持不变。

Swin Transformer Block
W-MSA和SW-MSA这两种机制在Swin Transformer中交替使用,以同时捕获局部和全局的上下文信息,从而提高模型的性能。

W-MSA 和 SW-MSA
-
基于窗口的多头自注意力(Window Multi-head Self-Attention):W-MSA通过将输入的特征图划分为多个固定大小的窗口,并在每个窗口内独立地执行多头自注意力计算,来减小计算量并保持局部依赖性。在W-MSA中,每个窗口内的元素之间会进行自注意力计算,但窗口之间无法进行信息交互。
-
基于移位窗口的多头自注意力(Shifted Windows Multi-head Self-Attention):SW-MSA是对W-MSA的改进,通过引入滑动窗口机制,使相邻窗口之间产生重叠,从而实现了窗口间的信息交互。通过多次滑动和计算,SW-MSA能够捕获到全局的上下文信息,并提高模型的感知能力。
-
多层感知机(MLP):在 SW-MSA 之后,Swin Transformer 块包含一个具有 GELU 非线性的 2 层 MLP。这个 MLP 用于进一步提取和转换图像特征,增加模型的非线性表达能力。
-
LayerNorm(LN)层和残差连接:在每个 MSA 模块和 MLP 之前都应用了一个 LayerNorm 层,用于对输入特征进行归一化操作,加速模型的训练过程。同时,在每个模块之后都应用了一个残差连接,将模块的输入和输出相加,有助于缓解梯度消失问题,提高模型的性能。

Swin Transformer Block
Swin Transformer的工作流程:
Swin Transformer的工作流程主要包括以下几个步骤:
-
Patch Partition:输入的图像首先被分割成若干个小的Patch(补丁),每个Patch被视为一个独立的单元进行处理。这一步类似于卷积神经网络中的卷积操作,目的是将图像信息转化为可处理的特征。
-
Linear Embedding:对Patch进行线性嵌入操作,将其转换为高维度的特征向量。这一步相当于卷积神经网络中的全连接层,用于增加模型的表示能力。
-
Swin Transformer Block:通过堆叠多个Swin Transformer块,模型能够逐步提取并转换图像的特征。
-
Patch Merging:在Swin Transformer中,为了增加模型的感受野和提高特征提取能力,相邻的小Patch被合并成大Patch。这种合并操作类似于池化操作,可以降低特征图的维度,同时保留重要的特征信息。

Swin Transformer的工作流程
模型应用
目标检测
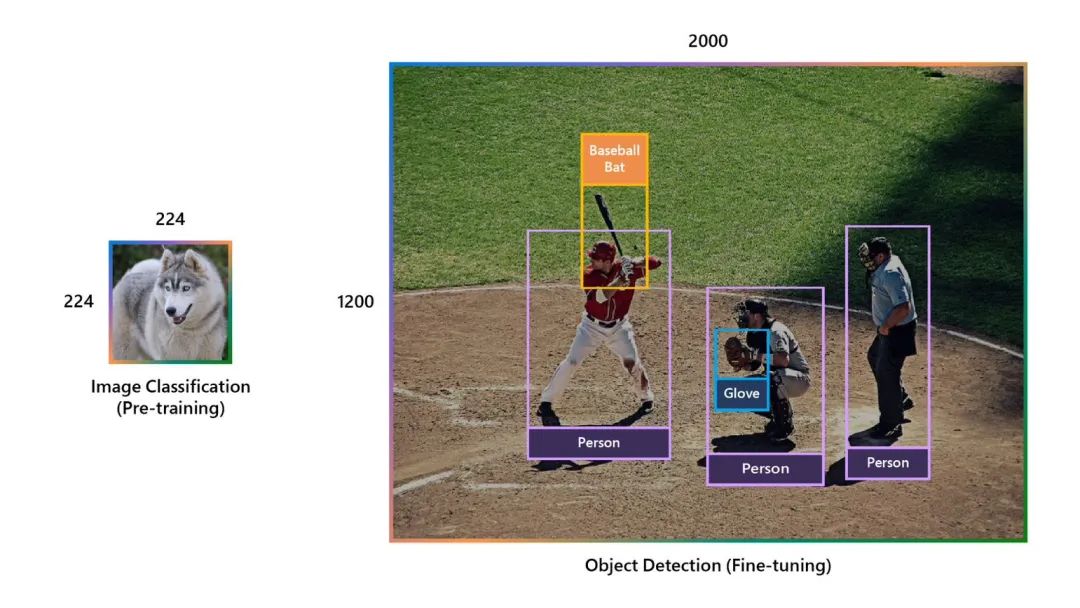
Swin Transformer应用目标检测
Swin Transformer应用在COCO等目标检测数据集:
在COCO等目标检测数据集上,Swin Transformer展示了卓越的性能。它通过引入基于self-attention的shifted window机制和线性的计算复杂度,有效地提高了目标检测的精度和效率。

Swin Transformer应用在COCO等目标检测数据集
Swin Transformer目标检测的三个步骤:
Swin Transformer进行目标检测的三个步骤包括:数据收集以涵盖目标多样性,使用Swin Transformer进行图像特征提取和目标检测,以及利用少样本学习技术提高在有限标注数据下的检测性能。
-
Data Collection(数据收集):首先,需要收集一个包含目标对象的数据集。这个数据集应该包含足够的样本,以涵盖目标对象在不同背景、角度、光照条件下的多样性。
-
Object Detection Using Transformer(使用Transformer进行目标检测):
Swin Transformer将图像分割成patch并转换为特征嵌入。通过编码阶段逐步提取特征并保持分层表示。使用检测头预测目标对象的边界框和类别。优化损失函数以学习从图像中提取目标特征并进行检测的能力。
-
Object Detection Mining Using Few-shot Learning(使用少样本学习进行目标检测挖掘):在有限标注数据下,使用少样本学习技术提高模型性能。技术包括数据增强、迁移学习和元学习等。利用这些技术生成更多训练样本、初始化模型权重或动态调整模型参数。

Swin Transformer目标检测
语义分割

Swin Transformer应用在ADE20K等语义分割数据集:
在ADE20K等语义分割数据集上,Swin Transformer也取得了优异的成果。它能够通过学习跨窗口的信息和处理超分辨率的图片,以关注全局和局部的信息,从而提高语义分割的准确性。

Swin Transformer应用在ADE20K等语义分割数据集
Swin Transformer和ResNet作为Mask R-CNN的骨干网络对比:
在Mask R-CNN的框架下,将Swin Transformer和ResNet作为骨干网络进行比较,可以评估两种模型在特征提取和最终目标检测性能上的差异。

Swin Transformer和ResNet作为Mask R-CNN的骨干网络对比
四个骨干网络均使用 ImageNet-1 K 进行预训练,然后使用 COCO 训练整个模型的参数。考虑到模型大小,进行了更公平的对比实验。 ResNet-50 和 Swin-T 的参数数量接近,ResNet-101 和 Swin-S 的参数数量也接近。
四个骨干网络模型大小

实验结果显示,Swin Transformer由于其独特的结构和特征提取能力,在某些情况下比ResNet具有更高的准确性。

相关论文
-
《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》
-
《A Survey on Visual Transformer》
-
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》
-
《Deep Residual Learning for Image Recognition》
-
《Transformer-based ripeness segmentation for tomatoes》















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









