






经典的MLLM可以抽象为三个模块,即Modality Encoder、LLM 和连接它们的模态接口Connector。与人类相似,图像/音频等模态编码器是接收和预处理光/声信号的眼睛/耳朵,而LLM就像人类大脑,能够理解和推理处理后的信号。
在两者之间,模态接口用于对齐不同的模态。一些MLLM还包括Generator,用于输出非文本模态。本文主要介绍Modality Encoder
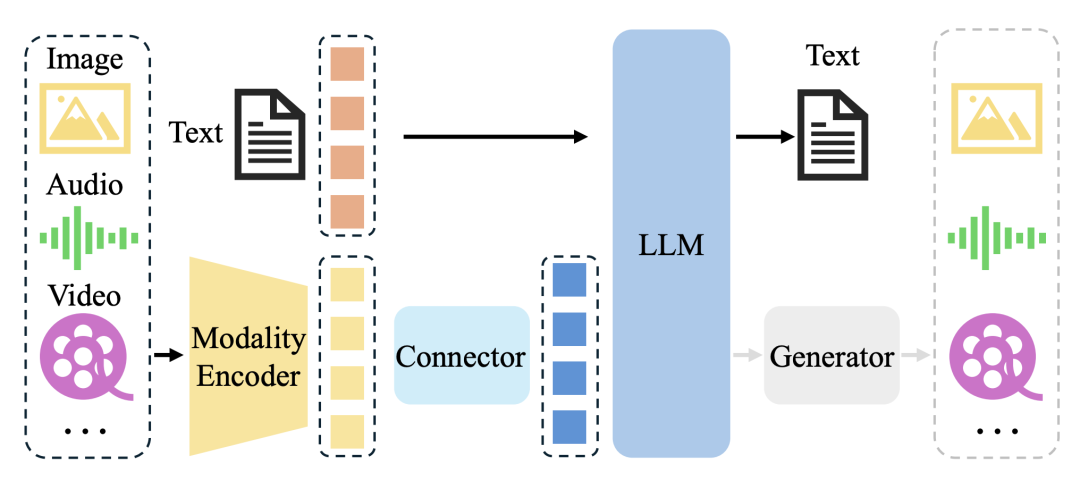
【经典MLLM架构】

一、Modality Encoder 简介
多模态编码器将原始信息(如图像或音频)压缩为更紧凑的表示形式。一种常见的方法是使用与其他模态对齐的预训练编码器,而不是从头开始训练。本文主要介绍 Modality Encoder。包括 Visual Encoder、Non-Visual Encoder、Unified Multimodal Encoder。
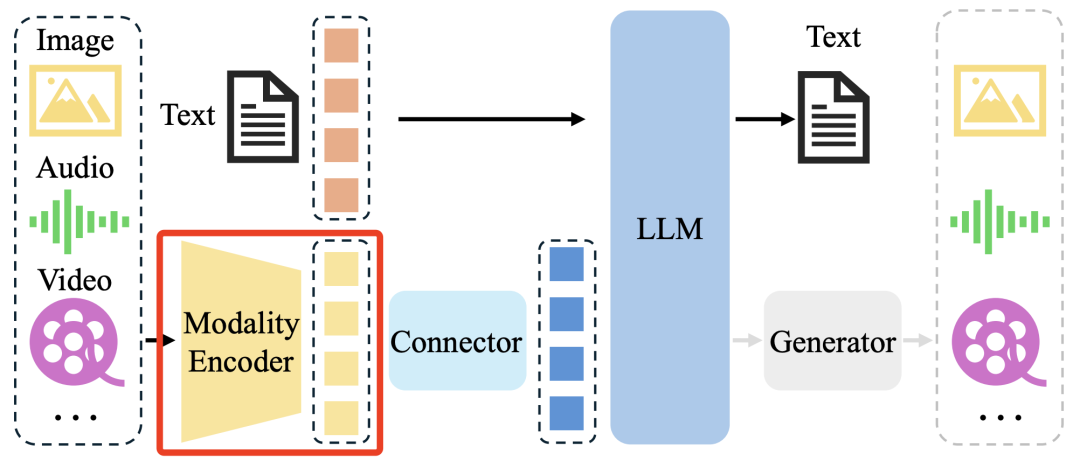
二、Visual Encoder
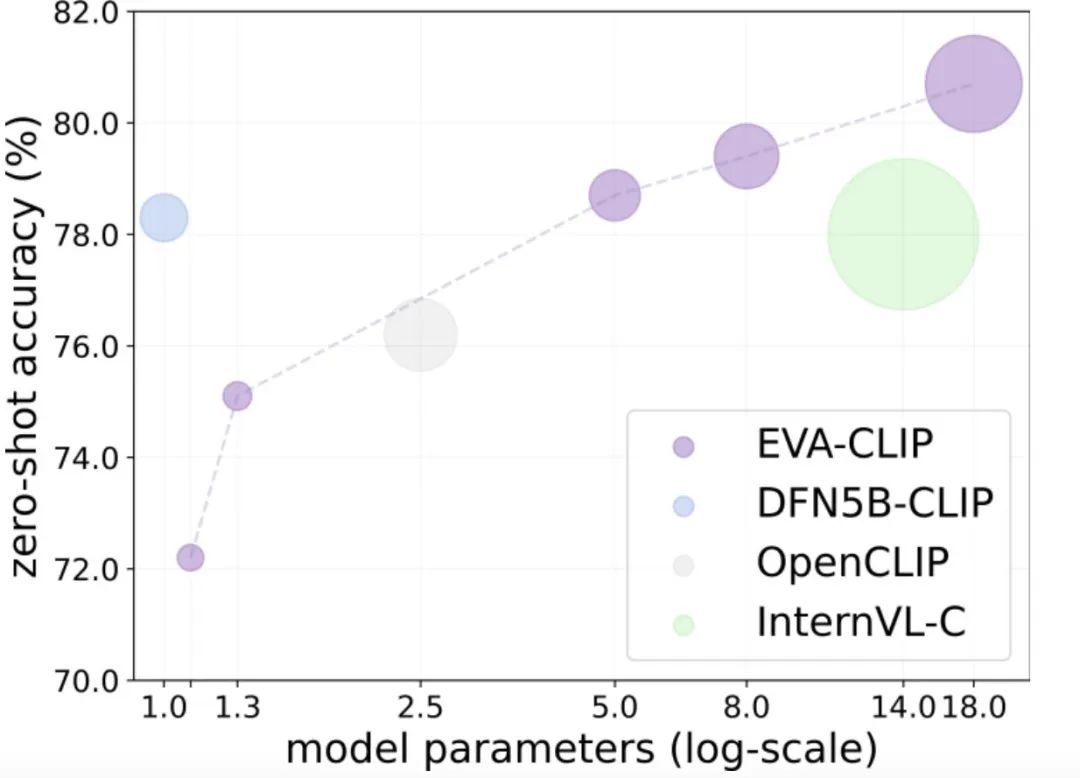
CLIP-VIT: 作为Vision-Language Model最流行的选择,提供了图像-文本的表征对齐,参数量和数据量的 scale 比较好
SigLip: 逐渐开始流行,源于它的参数量更小,性能更强
局限性: 当前存在的预训练的ViTs,局限性是输入的是固定的低分辨率(224*224, 336*336)图像,对于OCR、追求图像细节的VQA等任务来说,高分辨率的感知是必要的。

如何处理高分辨率图像的输入呢?本文将介绍以下三种方案。
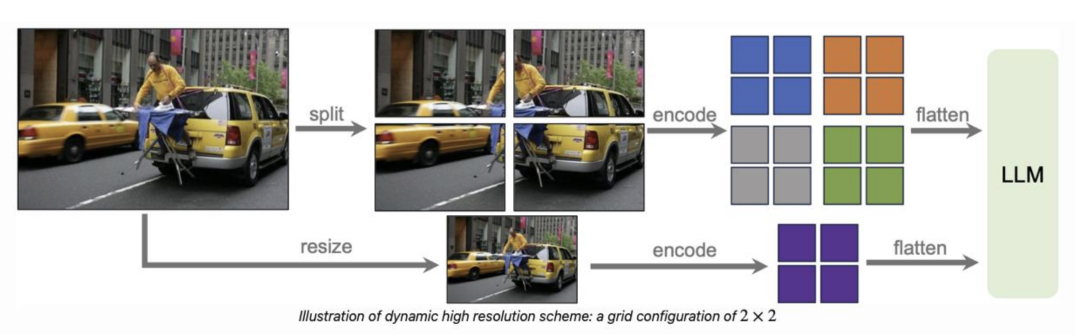
2.1 方案一:Image Slice-Based
基于图像切片的方案:将输入的高分辨率图像分割成多块,分别进行encoder
代表模型: GPT-4V, LLaVA-NeXT, MiniCPM-V 2.0/2.5, LLaVA-UHD, mPLUGDocOwl 1.5, SPHINX, InternLM-XComposer2-4KHD, Monke
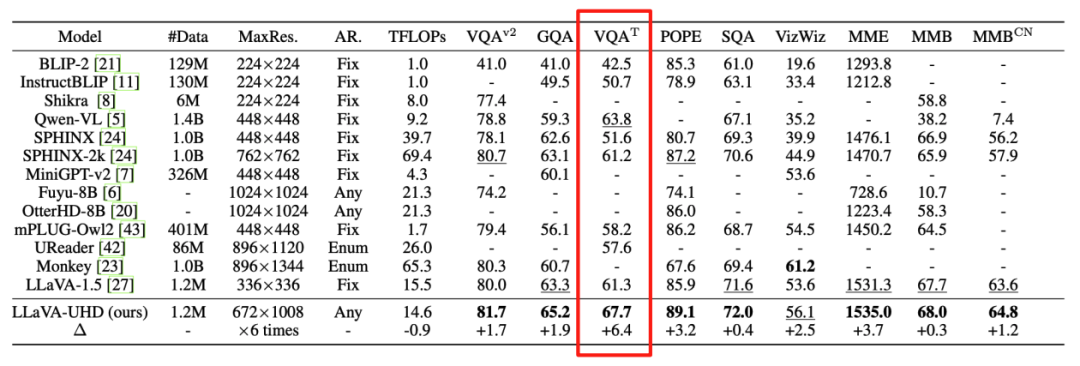
下图为 llava-next 方案,采用改方案,对于 OCR 任务指标具有明显提升
2.2 方案二:Dual Branch Encoders
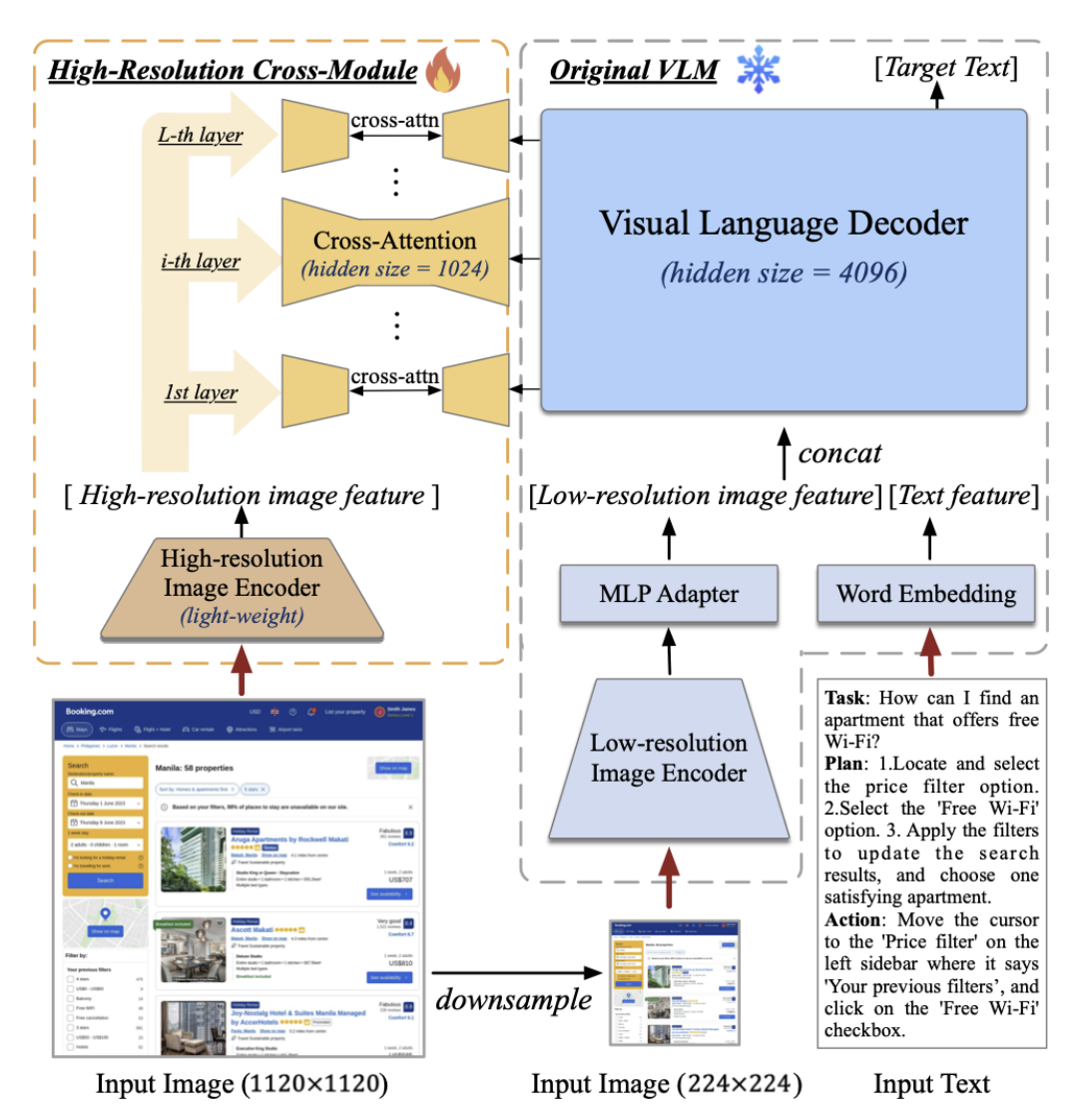
该方案采用两个分支分别进行图像编码,一个分支是hight-resolution image encoder,另一个分支是low-resolution image encoder,代表模型:CogAgent、Mini-Gemini、DeepSeek-VL、LLaVA-HR。
2.3 方案三:VIT-Free
采用linear projection 直接将image patch映射为tokens,摆脱了vit的表示形式,但是该方案训练成本更高,并且会产生较长的视觉tokens,代表模型:Fuyu, OtterHD。
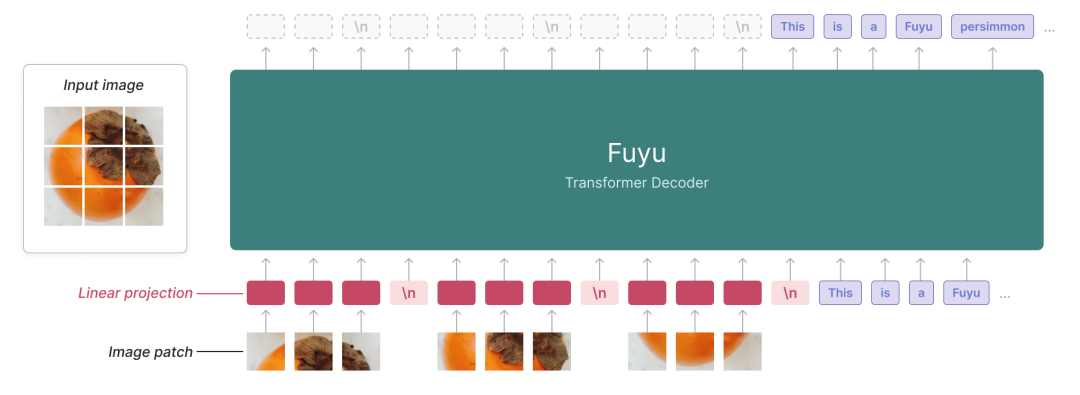 【Fuyu模型架构图】
【Fuyu模型架构图】
三、Non-Visual Encoder
非视觉编码器包括音频编码器、3D编码器等
1)Audio:Ahisper、AudioCLIP、HuBERT、BEATs
2)3D Point:Point-BERT
四、Unified Multimodal Encoder
Unified Multimodal Encoder支持对多模态数据的统一编码,如图像、文本、音频、深度、热和惯性测量单元(IMU)数据进行编码。配备强大的编码器,可以响应多种模态的输入。
1)ImageBind: 将所有模态嵌入到图像的联合表示空间中。好的模态对齐表示有助于LLM理解
 【ImageBind: One Embedding Space To Bind Them All. 2023】
【ImageBind: One Embedding Space To Bind Them All. 2023】
2)LanguageBind: 将所有模态嵌入语言的联合表示空间。好的模态对齐表示有助于LLM理解
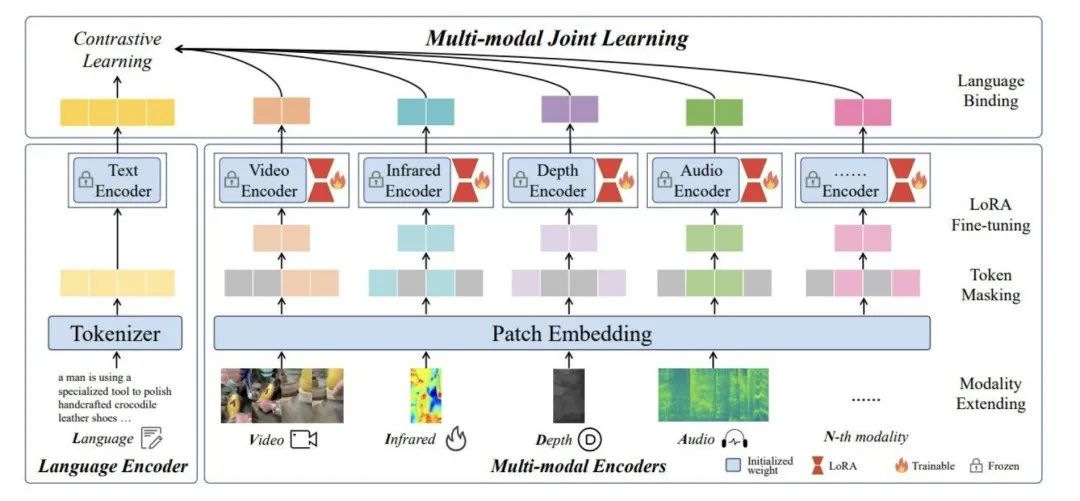 【LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment. 2023】
【LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment. 2023】
五、如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【
保证100%免费】
















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









