






在机器学习迅速发展的今天,一个基本挑战是使深度学习模型运行更加高效。模型量化是一种策略,它允许减少内存需求和计算需求,使得在资源受限的硬件上部署这些模型成为可能,并且更加高效。在这篇博客中,我们将深入探讨PyTorch模型量化的世界。
首先,我们将使用PyTorch设计和训练一个定制的深度学习架构。一旦我们的模型训练完成并准备好,我们将详细介绍应用三种不同的量化技术:静态量化、动态量化和量化感知训练。这些技术各有其独特的优势和潜在限制,对模型的性能和效率有不同的贡献。我们的目标不仅仅是了解如何量化PyTorch模型,还要了解为什么要量化。我们将看到每种策略如何影响模型的大小、速度和准确性。让我们开始吧!
一、深入量化
模型量化是减少模型权重和偏置的数值精度的过程。这一过程至关重要,因为它减少了模型大小并加快了推理速度,使得实时应用成为可能。精度的降低通常是从浮点数到整数,后者需要的内存和计算能力更少。
在深度神经网络中,量化是一个关键的优化技术,主要用于减少模型大小、提高计算效率、增强能源效率,并确保硬件兼容性。通过截断参数(权重和偏置)的数值精度,量化可以大幅减少模型的内存占用,使其更易于存储和部署。这种做法还提高了计算速度,对于实时应用至关重要。此外,它可以减少能源消耗,这对于手机或物联网设备等边缘设备来说是一个关键问题。最后,某些硬件加速器针对低精度计算进行了优化,使量化成为最大化这些优化的关键。尽管由于精度降低可能会损失一些准确性,但有多种技术用于管理这一点。
设置模型
我们将使用一个简单但有效的架构来对MNIST数据集进行分类,这是一个包含手写数字灰度图像的流行数据集。选择这个简单的深度学习模型是为了突出模型量化的力量和效果,而不是更复杂架构的复杂性。这个架构将包括Conv2d、BatchNorm2d、MaxPool2d、Linear和ReLU块。
import warnings
warnings.filterwarnings("ignore")
import os
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
架构:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(2, 2) # 初始化在这里
self.fc1 = nn.Linear(7*7*64, 512)
self.relu3 = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.maxpool(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.maxpool(x)
x = x.reshape(x.shape[0], -1)
x = self.fc1(x)
x = self.relu3(x)
x = self.fc2(x)
return x
数据集和数据加载器:
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=16, pin_memory=True)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False, num_workers=16, pin_memory=True)
我将使用我的ClassifierTrainer类来训练模型。这个类包含训练模型、保存模型和绘制准确率和损失图的方法。我们将在这里使用的所有辅助方法和类都可以在我的GitHub仓库中找到。
from train_helpers import ClassifierTrainer,save_plots
unqant_model = Net() # 未量化模型。
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(unqant_model.parameters(), lr=0.01)
trainer = ClassifierTrainer(
model= unqant_model,
optimizer=optimizer,
criterion=criterion,
train_loader=trainloader,
val_loader=testloader,
num_epochs=4,
cuda=False
)
trainer.train()
save_plots(
train_acc=trainer.train_accs,
train_loss=trainer.train_losses,
valid_acc=trainer.val_accs,
valid_loss=trainer.val_losses,
)
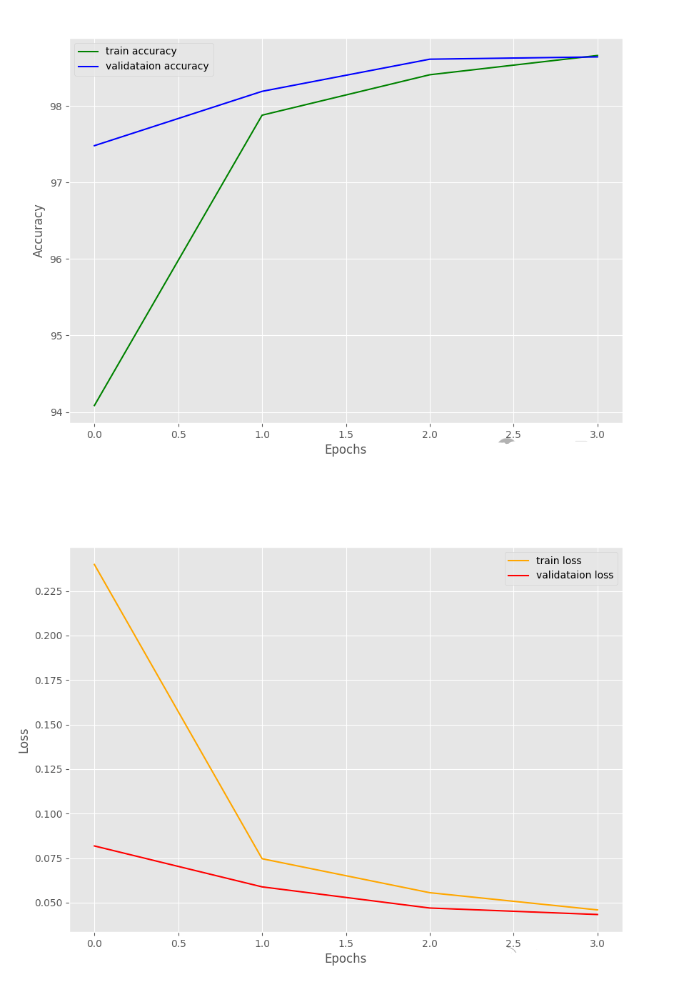
Epoch : 1/4: 100%|██████████| 938/938 [00:17<00:00, 55.13it/s, Accuracy=94.085, Loss=0.008]
验证准确率:97.48%,损失:0.08185123530910558
最佳验证损失:0.08185123530910558
保存第一周期的最佳模型
Epoch : 2/4: 100%|██████████| 938/938 [00:15<00:00, 59.86it/s, Accuracy=97.878, Loss=0.0259]
验证准确率:98.19%,损失:0.0588834396460402
最佳验证损失:0.0588834396460402
保存第二周期的最佳模型
Epoch : 3/4: 100%|██████████| 938/938 [00:15<00:00, 59.80it/s, Accuracy=98.407, Loss=0.0345]
验证准确率:98.61%,损失:0.04700030308571988
最佳验证损失:0.04700030308571988
保存第三周期的最佳模型
Epoch : 4/4: 100%|██████████| 938/938 [00:15<00:00, 59.63it/s, Accuracy=98.658, Loss=0.0237]
验证准确率:98.64%,损失:0.043366746839516274
最佳验证损失:0.043366746839516274
保存第四周期的最佳模型
二、模型量化类型
现在,随着我们的模型被训练,让我们更深入地了解量化。PyTorch提供了三种不同的量化方法,每种方法在确定将fp32转换为int8的bins时有所不同。
这三种PyTorch量化策略在调整量化算法和决定用于将浮点32向量转换为int8的不同bins方面各有其独特的方法。因此,每种方法都有其自己的优势和潜在限制。
- 静态量化
- 动态量化
- 量化感知训练
静态量化/后训练静态量化
静态量化,也称为后训练量化,是最常见的量化形式。它在模型训练完成后应用。在这里,模型的权重和激活都被量化为较低的精度。静态量化的规模和零点是在使用代表性数据集进行推理之前计算的,与动态量化不同,后者是在推理期间收集的。
由于量化过程在训练后离线发生,因此量化权重和激活没有运行时开销。量化模型通常与为低精度计算设计的硬件加速器兼容,从而实现更快的推理。
然而,从高精度权重和激活转换为较低精度可能会导致模型准确性略有下降。此外,您需要代表性数据进行静态量化的校准步骤。选择一个与模型在生产中将看到的数据非常相似的数据集至关重要。
静态量化步骤:
步骤1. 使用model.eval()将模型设置为评估模式。这很重要,因为某些层(如dropout和batchnorm)在训练和评估期间的行为不同。
import copy
unqant_model_copy = copy.deepcopy(unqant_model)
unqant_model_copy.eval()
Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=3136, out_features=512, bias=True)
(relu3): ReLU(inplace=True)
(fc2): Linear(in_features=512, out_features=10, bias=True)
)
步骤2. 定义模型架构中可以为量化目的而融合在一起的层列表。 执行量化时,某些操作组可以被替换为等效但更计算效率高的单个操作。例如,卷积后跟批量归一化,然后是ReLU操作(Conv -> BatchNorm -> ReLU)可以被替换为单个融合的ConvBnReLU操作。我们将使用torch.quantization.fuse_modules将一系列模块融合为单个模块。 这有几个优点:
-
性能提升:通过将多个操作融合为一个,融合操作可能比单独操作更快,因为函数调用更少,数据移动更少。
-
内存效率:融合操作减少了对中间结果的需求。这可以显著减少内存使用,特别是对于大型模型和输入。
-
简化模型图:融合操作的过程可以简化模型图,使其更容易理解和优化。
我们的模型架构包含2个(Conv -> BatchNorm -> ReLU)块。我们可以将这些块组合成一个ConvBnReLU块。
fused_layers = [['conv1', 'bn1', 'relu1'], ['conv2', 'bn2', 'relu2']]
fused_model = torch.quantization.fuse_modules(unqant_model_copy, fused_layers, inplace=True)
步骤3. 接下来,我们将使用QuantizedModel包装器类来包装我们的模型。
class QuantizedModel(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model_fp32 = model
self.quant = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.model_fp32(x)
x = self.dequant(x)
return x
这段代码的本质是向模型添加量化和反量化存根,它们将作为在量化过程中在模型图中插入实际量化和反量化函数的“锚点”。quant_layer将fp32中的数字转换为int8,以便conv和relu将以int8格式运行,然后dequant_layer将执行int8到fp32的转换。
步骤4. 使用torch.quantization.get_default_qconfig函数设置量化配置。T
# 从
# https://pytorch.org/docs/stable/quantization-support.html
# 选择量化方案
quantization_config = torch.quantization.get_default_qconfig("fbgemm")
quantized_model.qconfig = quantization_config
# 打印量化配置
print(quantized_model.qconfig)
“fbgemm”是一个高性能的8位量化后端,用于CPU。它目前是部署在服务器上时量化的推荐后端。PyTorch模型的qconfig属性用于指定模型应该如何量化。通过将quantization_config分配给quantized_model.qconfig,您正在指定模型应根据“fbgemm”后端的默认配置进行量化。
步骤5. 使用torch.quantization.prepare()函数准备模型进行量化。模型是就地准备的。
torch.quantization.prepare(quantized_model, inplace=True)
步骤6. 使用测试数据集校准模型。运行模型的几个示例以校准量化过程。
def calibrate_model(model, loader, device=torch.device("cpu")):
model.to(device)
model.eval()
for inputs, labels in loader:
inputs = inputs.to(device)
labels = labels.to(device)
_ = model(inputs)
# 使用训练数据进行校准。
calibrate_model(model=quantized_model, loader=trainloader, device="cpu")
在量化过程中,浮点值被映射到整数值。对于权重来说,范围是已知的,因为它们是静态的,并且在训练后不会改变。然而,激活可能会根据输入到网络的值而变化。校准通常通过传递数据子集通过模型并收集输出来执行,这有助于估计这个范围。
步骤7. 使用torch.quantization.convert()将准备好的模型转换为量化模型。转换也是就地完成的。
quantized_model = torch.quantization.convert(quantized_model, inplace=True)
quantized_model.eval()
模型比较
静态量化过程现已完成。我们终于可以比较我们的量化模型和未量化模型了。 我写了一个简单的辅助类来比较两个模型。ModelCompare类将接受两个模型,并比较它们的尺寸、准确性和N次迭代上的平均推理时间。
from utils import ModelCompare
model_compare = ModelCompare(
model1=quantized_model,
model1_info="Quantized Model",
model2=unqant_model,
model2_info="Uquantize model",
cuda=False
)
print("="*50)
model_compare.compare_size()
print("="*50)
model_compare.compare_accuracy(dataloder=testloader)
print("="*50)
model_compare.compare_inference_time(N=2 , dataloder=testloader)
结果:
模型量化模型大小(Mb):1.648963
模型未量化模型大小(Mb):6.526259
量化模型小了74.73%。
量化模型准确率:98.5
未量化模型准确率:98.53
量化模型在2次迭代上的平均推理时间:0.6589450836181641
未量化模型在2次迭代上的平均推理时间:0.7821568250656128
量化模型快了15.75%。
动态量化
动态量化在运行时动态量化模型权重。激活以原始浮点格式存储。
由于权重在运行时动态量化,它允许更大的灵活性。它在处理值范围可能变化的情况时可能是有益的。由于激活保持在其原始格式,准确性损失通常小于静态量化。动态量化不需要校准数据,使其更简单易用。
然而,由于动态量化只量化权重,而不是激活,因此它提供的压缩和加速比静态量化少。由于权重在推理期间即时量化,它可能会引入一些运行时开销。
动态量化非常简单,只需要一个步骤即可量化。让我们加载我们的未量化模型的权重:
# 加载torch状态
state = torch.load("outputs/best_model.pth")
model = Net()
# 加载状态字典
model.load_state_dict(state['model_state_dict'])
将模型设置为eval()模式。
执行动态量化:
from utils import ModelCompare
model_compare = ModelCompare(
model1=quantized_model,
model1_info="Quantized Model",
model2=model,
model2_info="Unquantized Model",
cuda=False
)
将量化模型与未量化模型进行比较:
print("="*50)
model_compare.compare_size()
print("="*50)
model_compare.compare_accuracy(dataloder=testloader)
print("="*50)
model_compare.compare_inference_time(N=2 , dataloder=testloader)
输出:
==================================================
模型量化模型大小(Mb):1.695323
模型未量化模型大小(Mb):6.526259
量化模型小了74.02%。
==================================================
量化模型准确率:98.54
未量化模型准确率:98.53
==================================================
量化模型在2次迭代上的平均推理时间:0.9944213628768921
未量化模型在2次迭代上的平均推理时间:0.9719561338424683
未量化模型快了2.26%。
量化感知训练
静态量化可以为推理生成高效的量化整数模型。然而,尽管进行了仔细的后训练校准,可能仍有时模型的准确性受到不可接受的影响。在这种情况下,仅后训练校准不足以生成量化整数模型。为了考虑量化效应,模型需要以考虑量化的方式进行训练。量化感知训练通过引入假量化模块来解决这个问题,这些模块在转换过程中的特定点模拟整数量化的截断和四舍五入效应,这些点是在从浮点模型转换为量化整数模型时发生的。这些假量化模块还监控权重和激活的规模和零点。一旦完成量化感知训练,就可以使用假量化模块中存储的信息,将浮点模型轻松转换为量化整数模型。
量化感知训练过程借鉴了静态量化的类似步骤。 让我们加载我们的未量化模型的权重:
# 加载torch状态
state = torch.load("outputs/best_model.pth")
quant_network = Net()
# 加载状态字典
quant_network.load_state_dict(state['model_state_dict'])
将模型设置为eval()模式。
步骤1. 检查可以融合的层并融合层。
# 检查可以融合的层。
fused_layers = [['conv1', 'bn1', 'relu1'], ['conv2', 'bn2', 'relu2']]
# 融合层
torch.quantization.fuse_modules(quant_network, fused_layers, inplace=True)
步骤2. 使用QuantizedModel包装融合后的模型。
class QuantizedModel(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model_fp32 = model
self.quant = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.model_fp32(x)
x = self.dequant(x)
return x
# 分别对输入和输出应用torch.quantization.QuantStub()和torch.quantization.QuantStub()。
quant_network = QuantizedModel(quant_network)
步骤3. 设置量化配置
# 从
quantization_config = torch.quantization.get_default_qconfig("fbgemm")
quant_network.qconfig = quantization_config
# 打印量化配置
print(quant_network.qconfig)
步骤4. 为QAT准备模型。
# 为QAT准备
torch.quantization.prepare_qat(quant_network, inplace=True)
步骤5. 现在,使用我们的ClassifierTrainer训练QAT模型。
from train_helpers import ClassifierTrainer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(quant_network.parameters(), lr=0.01)
trainer = ClassifierTrainer(
model= quant_network,
optimizer=optimizer,
criterion=criterion,
train_loader=trainloader,
val_loader=testloader,
cuda=False,
num_epochs=4
)
trainer.train(save_model=False)
Epoch : 1/4: 100%|██████████| 938/938 [00:18<00:00, 51.95it/s, Accuracy=77.492, Loss=0.2025]
验证准确率:92.54%,损失:0.2595426786074023
Epoch : 2/4: 100%|██████████| 938/938 [00:16<00:00, 55.84it/s, Accuracy=93.878, Loss=0.1657]
验证准确率:95.98%,损失:0.14535175562557426
Epoch : 3/4: 100%|██████████| 938/938 [00:16<00:00, 55.95it/s, Accuracy=96.143, Loss=0.0881]
验证准确率:96.3%,损失:0.11678009550680353
Epoch : 4/4: 100%|██████████| 938/938 [00:16<00:00, 55.86it/s, Accuracy=97.043, Loss=0.0618]
验证准确率:97.5%,损失:0.08276212103383106
步骤6. 最后,对模型进行量化。
quant_network.to("cpu")
quantized_model = torch.quantization.convert(quant_network, inplace=True)
模型比较
from utils import ModelCompare
model_compare = ModelCompare(
model1=quantized_model,
model1_info="Quantized Model",
model2=model,
model2_info="UnQuantized Model",
cuda=False
)
print("="*50)
model_compare.compare_size()
print("="*50)
model_compare.compare_accuracy(dataloder=testloader)
print("="*50)
model_compare.compare_inference_time(N=10 , dataloder=testloader)
==================================================
模型量化模型大小(Mb):1.648963
模型未量化模型大小(Mb):6.526259
量化模型小了74.73%。
==================================================
量化模型准确率:97.51
未量化模型准确率:98.53
==================================================
量化模型在10次迭代上的平均推理时间:0.6605435371398926
未量化模型在10次迭代上的平均推理时间:0.6626742124557495
量化模型快了0.32%。
结论
模型量化的更广泛影响不仅限于模型效率和性能。通过减少计算需求、能源消耗和内存需求,我们使高级深度学习模型更加易于获取,特别是在资源有限的硬件上。这反过来为更广泛和多样化的应用铺平了道路。
参考:https://r4j4n.github.io/blogs/posts/quantization/
三、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









