







文章目录
一、前言
今天是第10天,我们将使用LSTM完成股票开盘价格的预测,最后的R2可达到0.74,相对传统的RNN的0.72提高了两个百分点。
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
来自专栏:【深度学习100例】
往期精彩内容:
- 深度学习100例-卷积神经网络(LeNet-5)深度学习里的“Hello Word” | 第22天
- 深度学习100例-卷积神经网络(CNN)实现mnist手写数字识别 | 第1天
- 深度学习100例-卷积神经网络(CNN)服装图像分类 | 第3天
- 深度学习100例-卷积神经网络(CNN)花朵识别 | 第4天
- 深度学习100例-卷积神经网络(CNN)天气识别 | 第5天
- 深度学习100例-卷积神经网络(VGG-16)识别海贼王草帽一伙 | 第6天
- 深度学习100例-卷积神经网络(ResNet-50)鸟类识别 | 第8天
- 深度学习100例-循环神经网络(RNN)股票预测 | 第9天
如果你还是一名小白,可以看看我这个专门为你写的专栏:《小白入门深度学习》,帮助零基础的你入门深度学习。
二、LSTM的是什么
神经网络程序的基本流程
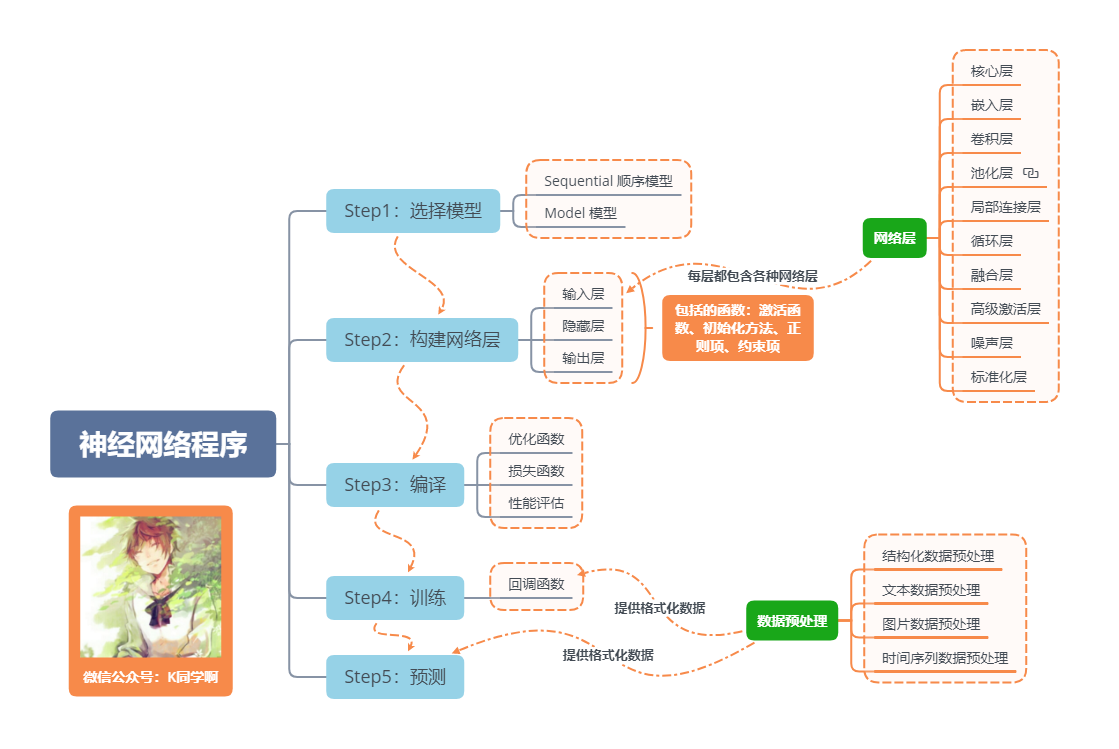
一句话介绍LSTM,它是RNN的进阶版,如果说RNN的最大限度是理解一句话,那么LSTM的最大限度则是理解一段话,详细介绍如下:
LSTM,全称为长短期记忆网络(Long Short Term Memory networks),是一种特殊的RNN,能够学习到长期依赖关系。LSTM由Hochreiter & Schmidhuber (1997)提出,许多研究者进行了一系列的工作对其改进并使之发扬光大。LSTM在许多问题上效果非常好,现在被广泛使用。
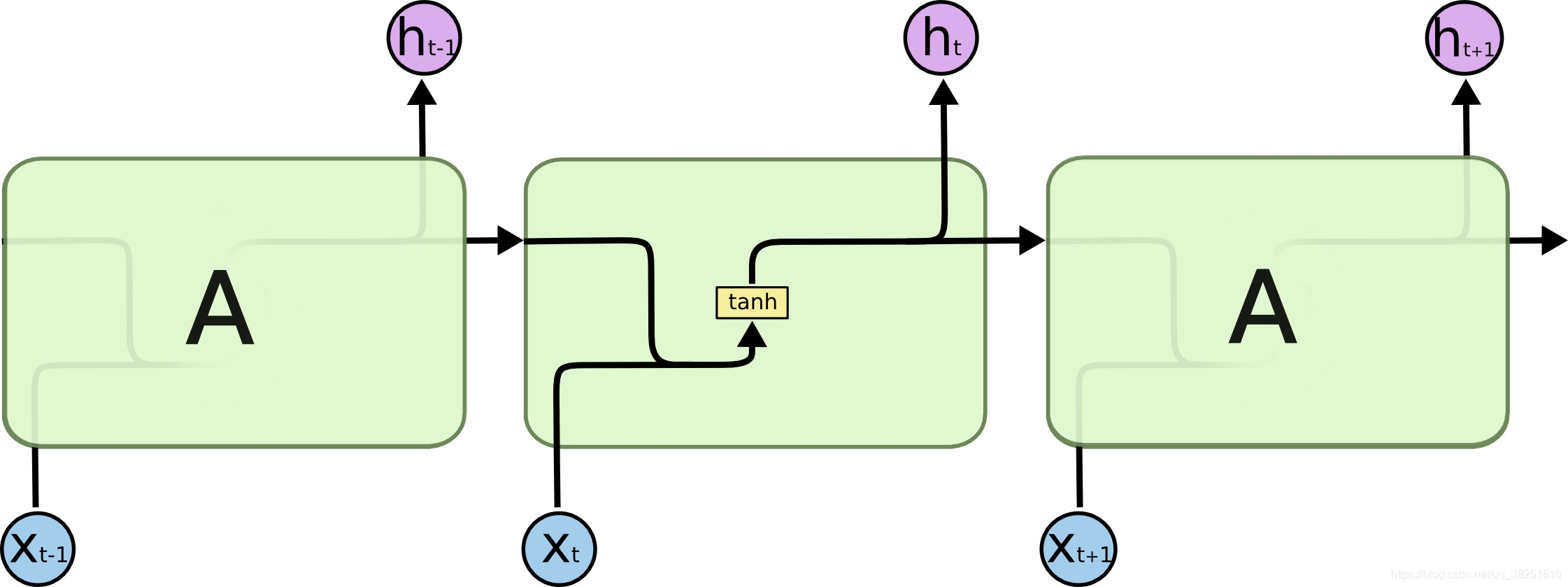
所有的循环神经网络都有着重复的神经网络模块形成链的形式。在普通的RNN中,重复模块结构非常简单,其结构如下:
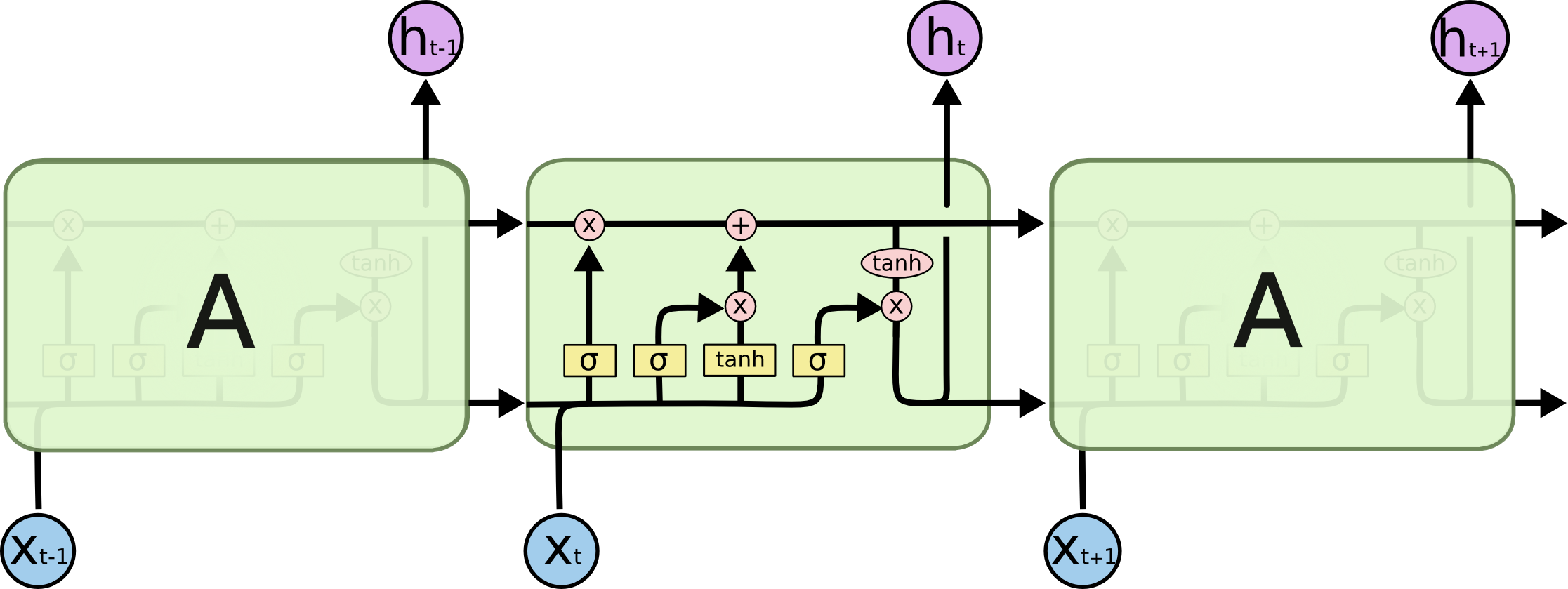
LSTM避免了长期依赖的问题。可以记住长期信息!LSTM内部有较为复杂的结构。能通过门控状态来选择调整传输的信息,记住需要长时间记忆的信息,忘记不重要的信息,其结构如下:
三、准备工作
1.设置GPU
如果使用的是CPU可以注释掉这部分的代码。
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
2.设置相关参数
import pandas as pd
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
from numpy import array
from sklearn import metrics
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense,LSTM,Bidirectional
# 确保结果尽可能重现
from numpy.random import seed
seed(1)
tf.random.set_seed(1)
# 设置相关参数
n_timestamp = 40 # 时间戳
n_epochs = 20 # 训练轮数
# ====================================
# 选择模型:
# 1: 单层 LSTM
# 2: 多层 LSTM
# 3: 双向 LSTM
# ====================================
model_type  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









