






【学习笔记】光流(Optical Flow)的基本知识与光流估计方法
1. 简介
1.1 光流(Optical Flow)的基本概念
光流(Optical Flow)是指描述在图像序列中物体表面上的像素移动的模式。在计算机视觉和图像处理领域,光流是一种用于估计相邻帧之间像素之间位移的技术。简而言之,光流是描述相邻图像帧之间像素运动的模式,它通过跟踪图像中的特征点或像素来估计运动的速度和方向。 或者说是在像素级别上的位移描述,即每一个像素点从第一帧到第二帧的具体偏移量。
1.2 补充说明
光流法的基本假设:(1)亮度恒定不变,即同一目标在不同帧间的运动时亮度不会发生改变;(2)相邻帧之间的位移要比较小,即时间上不会引起目标的剧烈位置变化。
基于假设的形式化表达:形式化表达即如下,其中I代表具体的像素值(光强度),t为具体的时刻,Δt一般即为相邻帧的时间,(u,v)则为像素的具体偏移量,可以理解成前一帧图像中的(i,j)像素在Δt的时间间隔下(下一帧),移动了(u,v)。
I
(
i
,
j
,
t
)
=
I
(
i
+
u
,
j
+
v
,
t
+
Δ
t
)
I(i,j,t) = I(i+u,j+v,t+\Delta t)
I(i,j,t)=I(i+u,j+v,t+Δt)
光流的方向:图像帧A→B,则flow的方向为B->A。(不确定,查阅了各种资料后得到的解释,但这部分方向上的定义不影响实际的分析与代码编写)
光流的warp:若存在两帧frame1和frame2,不考虑batch的情况下,其shape均为[3,H,W],对应的flow的shape为[2,H,W],两个通道分别表示水平、竖直方向上的位移,该flow满足以下关系式子。
f
r
a
m
e
1
[
:
,
i
,
j
]
=
f
r
a
m
e
2
[
:
,
i
+
u
,
j
+
v
]
u
=
f
l
o
w
[
0
,
i
,
j
]
,
v
=
f
l
o
w
[
1
,
i
,
j
]
frame1[:,i,j] = frame2[:,i+u,j+v] \\ u=flow[0,i,j],v=flow[1,i,j]
frame1[:,i,j]=frame2[:,i+u,j+v]u=flow[0,i,j],v=flow[1,i,j] 那么在已知frame1和flow的情况下,可以通过依次查询flow并将像素进行偏移得到frame2,该过程则为warp。在大多数代码场景下,还会涉及到backwarp操作(有些文章不严格区分warp和backwarp),即在已知frame2和flow的情况下,得到frame1,一部分原因还包括backwarp的操作可以通过torch.nn.functional.grid_sample采样函数实现(见后文),这样的话,我们可以在已知frame2到frame1的flow以及frame1的前提下轻松地求得frame2。(Tips:部分文章提及使用frame1到frame2的-flow求frame2,使用的还是基于grid_sample函数的backwarp方法,个人认为并不正确,因为frame2的像素点和具体在frame1的采样点的映射关系需要通过flow得以确定,画个图就可以说明。)
1.3 常见应用
视频压缩、视频插帧、物体运动分析(车流方向)、特征计算的优化、视频稳像、视觉效果等。
2. 一些常用操作
2.1 光流文件存取
flow的常见存储文件格式为.flo,网络上已有现成且广泛使用的flo文件读取代码,如下。通过分析代码可以知道该文件大致的存储结构,包括标识符、高宽数据、具体位移数据。通过open函数进行二进制形式打开即可,使用numpy中的fromfile函数进行依次读取。
# 读取flow文件,返回对应的numpy数组
def load_flow(path):
with open(path,'rb') as fl:
flag = np.fromfile(fl,np.float32,count=1) # 先读取第一个数据
assert (202021.25 == flag) # 使用assert语句判定flo文件的合法性
width = np.fromfile(fl, np.int32, count=1)[0] # 读取宽、高信息
height = np.fromfile(fl, np.int32, count=1)[0]
data = np.fromfile(fl, np.float32, count=2 * width * height) # 读取剩余的位移数据
return np.resize(data, (height, width, 2))
对于flo文件的保存,则按照读取的逆方法即可,代码如下。
flag = np.array([202021.25], np.float32)
def sava_flow(filename, flo):
flo = flo[0].permute(1, 2, 0).cpu().numpy() #默认输入shape为[1,2,H,W]
u = flo[:, :, 0] # 水平移动信息
v = flo[:, :, 1] # 竖直移动信息
height, width = u.shape
f = open(filename, 'wb')
f.write(flag) #写入flag
np.array(width).astype(np.int32).tofile(f) #写入宽、高信息
np.array(height).astype(np.int32).tofile(f)
tmp = np.zeros((height, width * 2))
tmp[:, np.arange(width) * 2] = u # 按顺序保存位移信息
tmp[:, np.arange(width) * 2 + 1] = v
tmp.astype(np.float32).tofile(f)
f.close()
2.2 光流可视化
将运动信息进行具体的可视化。其实就是对不同位移方向和大小进行颜色赋值,例如绿色代表往右上角进行移动,绿色越深表示偏移程度越大。
例如可以达到以下的效果。(实际位移方向与颜色之间的映射关系可能不同,下图中左上角的椅子往右上角移动了,颜色为深紫色。)

网上常用的可视化代码如下,可以直接当成已知模块使用。
# 将flow进行可视化
def flow_to_image(flow, max_flow=256):
# 确保max_flow的最小值为1
if max_flow is not None:
max_flow = max(max_flow, 1.)
else:
max_flow = np.max(flow)
# 定值,含义未深究,可能是用于得到不同的饱和度
n = 8
# 提取水平、垂直运动信息
u, v = flow[:, :, 0], flow[:, :, 1]
# 计算每个像素点的光流大小,即为模长(位移大小)
mag = np.sqrt(np.square(u) + np.square(v))
# 计算每个像素点的光流方向,即速度的方向角度(得到的弧度)
angle = np.arctan2(v, u)
# 将角度值映射到0到1的范围内,除以2*pi,加1并余1即可约束范围(色调信息)
im_h = np.mod(angle / (2 * np.pi) + 1, 1)
# 大概是:计算每个像素点的饱和度,通过光流大小和max_flow的比值进行缩放,并确保饱和度在0到1的范围内
im_s = np.clip(mag * n / max_flow, a_min=0, a_max=1)
# 大概是:计算每个像素点的亮度,亮度为n减去饱和度,并确保亮度在0到1的范围内
im_v = np.clip(n - im_s, a_min=0, a_max=1)
# 将色调、饱和度和亮度转换为RGB颜色空间的图像
im = hsv_to_rgb(np.stack([im_h, im_s, im_v], 2))
# 在0到255的范围内表示图像的像素值
return (im * 255).astype(np.uint8)
2.3 backwarp操作实现
对于正向warp,其含义比较简单,即将每一个像素点数值放到对应的偏移位置即可,注意非整点的处理。
这里重点介绍一下使用torch.nn.functional.grid_sample的backwarp操作,由于backwarp操作一般在网络内部执行,这里写的是torch框架下的代码。
对于grid_sample函数,网上资料较多,不做赘述,简单来说就是输入一个图像和一个网格grid,根据网格grid中的位置信息在图像中找到(采样)对应的像素点进行存储,看后续代码应该更好理解。
# 这里把它封装成了一个nn模块,将backwarp操作写到了正向传播过程中,输入frame2与flow,得到对应的frame1
class BackWarpFlow(nn.Module):
# 类静态变量,其实可以写成全局变量。由于后面的操作有需要处理指定规格的网格,有时候无需重复处理以减少时间开销,这里先做一个存储
Warp_Grid = {}
def __init__(self):
super(BackWarpFlow, self).__init__()
def forward(self, img, flow):
# 将运算加载到GPU上,如果传入的张量已在GPU上加载则可以不用操作
img, flow = img.cuda(), flow.cuda()
# 若该规格的flow未被处理过(未生成过对应规格的网格)则先处理出一个网格
if str(flow.shape) not in BackWarpFlow.Warp_Grid:
# 使用linspace生成一个从-1.0到1.0的等间隔的张量(与flow的宽等长),并调整规格为[1,1,1,W]
# 使用repeat函数在shape[2]方向上重复shape[2]次,即H次,得到张量的规格为[1,1,H,W]
u = torch.linspace(-1.0, 1.0, flow.shape[3]).view(1, 1, 1, -1).repeat(1, 1, flow.shape[2], 1)
# 同理另一层
v = torch.linspace(-1.0, 1.0, flow.shape[2]).view(1, 1, -1, 1).repeat(1, 1, 1, flow.shape[3])
# 在第1个维度上拼接得到的网格规格为[1,2,H,W],与flow相对应,且每一个像素位置上的值是均匀的,与其位置相对应。存储到字典中
BackWarpFlow.Warp_Grid[str(flow.shape)] = torch.cat([u, v], 1).cuda()
# 取出flow中两个方向上的偏移,将其根据规格进行规范化处理,重新拼接
tenFlow = torch.cat([flow[:, 0:1, :, :] * (2.0 / (img.shape[3] - 1.0)),
flow[:, 1:2, :, :] * (2.0 / (img.shape[2] - 1.0))], 1)
# 调用grid_sample进行采样,前面提到Warp_Grid中的网格值是与位置一一对应的,加上flow后,每个网格上的值就相当于进行了位移,将该网格作为采样网格即可实现frame2还原到frame1。
#(理解成,(i,j)地方的像素应当去(i+u,j+v)的地方采样,(i,j)即在Warp_Grid中体现,与位置对应,(u,v)即在tenFlow体现)
# permute调整维度以适应grid_sample函数,该函数要求通道数这一维在最后
# 可能有非整点的情况出现,采用双线性插值。
return torch.nn.functional.grid_sample(input=img,
grid=(BackWarpFlow.Warp_Grid[str(tenFlow.shape)] + tenFlow).permute(0,2,3,1),
mode='bilinear',
padding_mode='border',
align_corners=True)
2.4 光流的评价(Loss说明)
最主要的评价指标为Endpoint error (EPE) loss,即端点误差损失。EPE损失是通过计算预测的光流场与真实的光流场之间的平均欧氏距离来衡量光流估计的精度。同时也可以作为损失函数进行相关光流估计网络的训练。该部分代码实现方式较多,这里呈现最简单的实现方法。
class EPELoss(nn.Module):
def __init__(self):
super(EPELoss, self).__init__()
def forward(self, flow_pred, flow_target):
# 平均欧氏距离
dist = (flow_target - flow_pred).pow(2).sum().sqrt()
return dist.mean()
3. 光流估计方法
前人有许多基于数理统计、泰勒展开等数学方法,内容较多难以涵盖,主要介绍归纳几种常见有效的基于深度学习的光流估计方法(当然是经过论文阅读和学习的方法,没有学习到的方法若后续有所学习,则会补上笔记)。大部分方法本文只能给出整体的实现思路,具体的开源代码分析耗时较长,后续再进行整理编辑。同时,对于每种方法的创新点和亮点,不同读者可能有不同的理解看法,本文视角可能相对局限。
3.1 FlowNet-基于CNNs构建的含关联层的端到端训练光流网络
3.1.1 论文及其链接
论文:ICCV2015, FlowNet: Learning Optical Flow with Convolutional Networks
链接:FlowNet: Learning Optical Flow With Convolutional Networks (thecvf.com)
3.1.2 文章摘要
卷积神经网络(CNNs)最近在各种计算机视觉任务中取得了很大成功,尤其是与识别相关的任务。光流估计并不是CNNs成功的任务之一。在本文中,我们构建了能够将光流估计问题作为监督学习任务解决的CNNs。我们提出并比较了两种架构:一种通用架构和另一种包括在不同图像位置相关特征向量的层。由于现有的地面真实数据集不足以训练CNN,我们生成了一个大型的合成飞行椅子(Flying Chairs)数据集。我们展示了在这种不真实的数据上训练的网络仍然很好地推广到现有数据集,如Sintel和KITTI,在5到10fps的帧速率下达到了竞争性的准确度。
3.1.3 文章亮点
- 提出了使用卷积神经网络来进行光流估计的方法,例如一种通用架构,说明了使用CNNs方法进行光流估计的可行性;
- 提出了像素关联层(correlation layer)的概念,再像素级别描述各像素之间的关联性,使用网络自行学习两张图像(或其特征)之间的关联性,以实现图像在不同位置之间的匹配;
- 在多个尺度上不断细化光流(Refinement),对低分辨率的粗糙进行上采样并逐步学习细化;
- 制作了Flying Chairs数据集,提供了一种含噪声背景情况下的物体运动信息(Flow)的数据集。
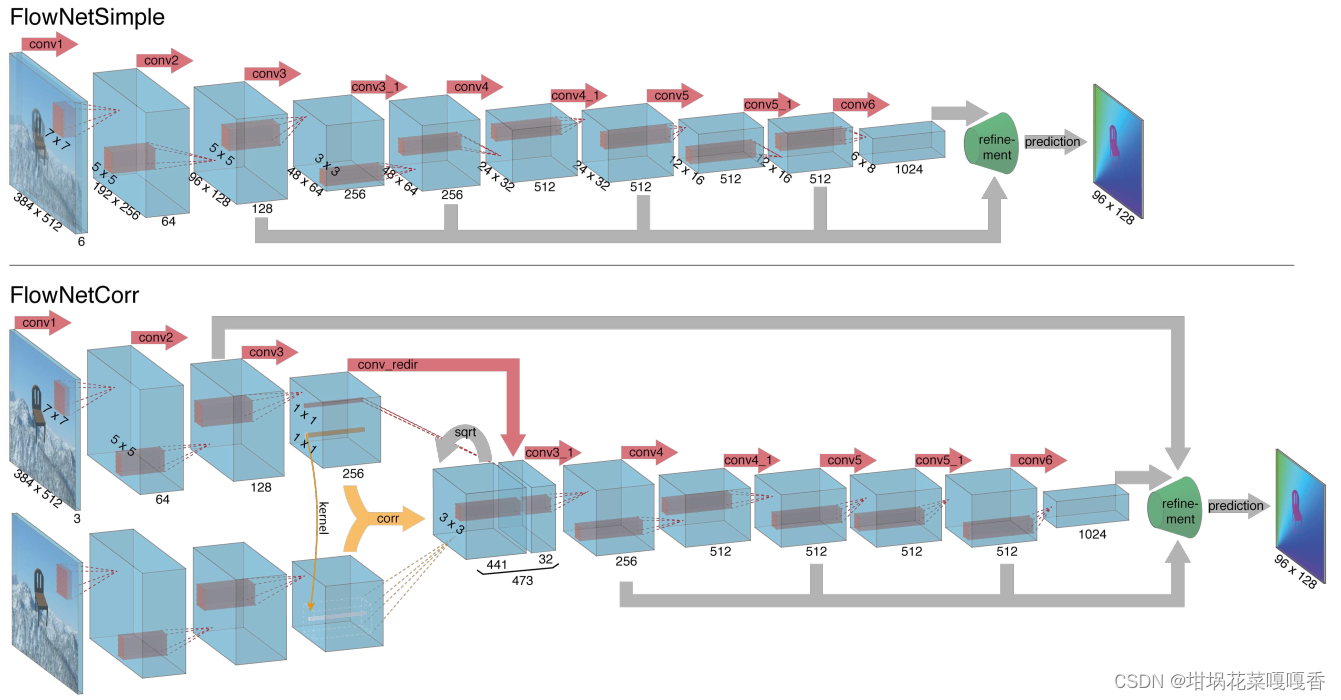
3.1.4 网络结构
文章中包含了两种网络结构,一种为简单版本的FlowNetSimple,另一种是基于像素关联层的FlowNetCorr,结构分别如下。
Refinement模块
两类网络均包含了refinement细化模块,该模块以多尺度的图像特征为输入,得到细化的光流估计(提高光流的输出分辨率),结构如下。(但从效果来说,又比双线性插值好多少呢)
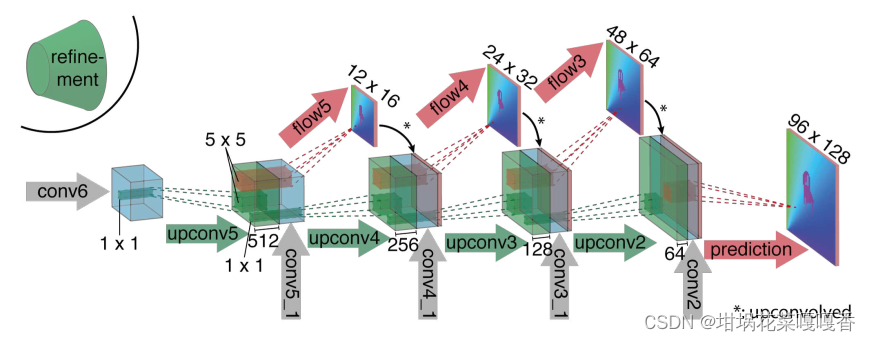
可以看到,灰色部分即为编码器(特征提取部分)所得到的多尺度特征。该细化模块进行了多个尺度的粗糙光流细化,具体地,相当于将以下三部分内容进行拼接:上一层特征经过卷积与上卷积后的结果(绿色)、上一层输出的粗糙flow的上采样结果(红色)、编码器过程中对应尺度的特征(灰色),作为当前层的特征,送入一个光流预测网络即可获得当前层输出的光流。
FlowNetSimple
简单地将两张图像进行拼接(在通道维度上进行拼接),并使用卷积神经网络进行多尺度的特征提取,最后送入细化模块进行光流的细化。该网络结构是由网络自行决定如何从图像中进行运动信息的提取。对输出Flow进行监督达到光流估计的目的。
FlowNetCorr
根据网络结构可知对两帧图像分别进行特征的采集,随后对特征进行关联性计算,得到一个特征相关性矩阵(暂且这么叫吧)。
首先文章中给出了两个特征图中任意两个像素之间的关联性定义,如下表达式。
c
(
x
1
,
x
2
)
=
∑
o
∈
[
−
k
,
k
]
×
[
−
k
,
k
]
⟨
f
1
(
x
1
+
o
)
,
f
2
(
x
2
+
o
)
⟩
c\left(\mathbf{x}_{1}, \mathbf{x}_{2}\right)=\sum_{\mathbf{o} \in[-k, k] \times[-k, k]}\left\langle\mathbf{f}_{1}\left(\mathbf{x}_{1}+\mathbf{o}\right), \mathbf{f}_{2}\left(\mathbf{x}_{2}+\mathbf{o}\right)\right\rangle
c(x1,x2)=o∈[−k,k]×[−k,k]∑⟨f1(x1+o),f2(x2+o)⟩ 上式含义为:以x1这个点为中心,2k+1为边长的正方形区域,与x2为中心的区域之间的关联性,这里引入一个k作为区域范围,以说明一个个patch块之间的关联性(其实就是考虑到了周边的像素点的特征)。其中x1和x2分别表示来自于两个特征图的像素位置,分别都是二元组;f1表示第一个特征图,f2表示第二个特征图,由于特征图是多通道的(如前面的网络结构图中显示的两个计算相关性的特征图,均有256层特征),因此每一个像素位置都可以取到多通道的特征数值(例如在第一个特征图的(i,j)位置,可以取到一个256维的向量feature[: , : , i , j]),将两个区域块对应位置的特征向量进行内积运算,得到一个相关值c。
但每个特征图都有h×w个像素,两张特征图中两两求关联性则会产生h×h×w×w个相关值,这个数量太大了,因此文章中提到对于每个位置的像素仅考虑一个限定范围D之内的像素的相关性,即不考虑处理距离太远的像素之间的相关项,这样便将值相关性数据的数理降低为h×w×D×D。即可以理解为:对于第一张图的每一个位置的像素特征,都对应着和第二张图D×D个相关性值。这也是图中441这个数值的来源,这里的D应取为21,即考虑以某一像素为中心,边长为21的范围内的像素的相关性。
此外,观察网络结构图可以发现,文章还将该相关项矩阵与第一张图的再采样的特征图(以尺寸为1的卷积核获取了32层特征)进行了拼接操作,这一步文章中并未详细说明(可能也是我没读仔细),感性理解上可能是,后续的网络学习需要同时带上第一帧图像的一些特征信息,进行特征融合。
通过相关性矩阵的处理,网络能够学习到像素级别上的像素相关性信息,从而更好地捕获像素级别的运动信息,在学习到抽象的相关性特征的同时不丢失浅层的图像信息。
3.2 SPyNet-基于空间金字塔与残差光流训练的光流更新网络
3.2.1 论文及其链接
论文:CVPR2017, Optical Flow Estimation using a Spatial Pyramid Network
链接:Optical Flow Estimation Using a Spatial Pyramid Network (thecvf.com)
3.2.2 文章摘要
我们通过将经典的空间金字塔形式与深度学习相结合来学习计算光流。这通过在每个金字塔级别将一对图像中的一个图像根据当前的光流估计进行warp,并计算对光流的更新来以粗到细的方式估计大运动。与在每个金字塔级别进行标准目标函数最小化的方法不同,我们针对每个级别训练一个深度网络来计算光流的更新。与最近的FlowNet方法不同,网络不需要处理大运动;这些大运动由金字塔来处理。这有几个优点。首先,我们的空间金字塔网络(SPyNet)在模型参数方面比FlowNet简单得多,小96%。这使得它更高效,更适用于嵌入式应用。其次,由于每个金字塔级别的光流很小(<1像素),因此将卷积方法应用于一对变形图像是合适的。第三,与FlowNet不同,学习到的卷积滤波器与经典的时空滤波器相似,这提供了对方法及其改进方法的见解。我们的结果比大多数标准基准测试上的FlowNet更精确,这表明了将经典的光流方法与深度学习相结合的新方向。
3.2.3 文章亮点
- 采用训练光流残差的方式,对光流进行逐步细化;
- 每一个尺度下均训练了一个深度网络用于光流残差的获取,并有多尺度下的光流细化过程;
- 将传统的空间金字塔与深度学习方法进行结合,同时参数量较小。
3.2.4 网络结构
SPyNet的网络结构如下,其中仅举例展示了三层金字塔结构,具体的金字塔层数可以根据实际情况进行修改。
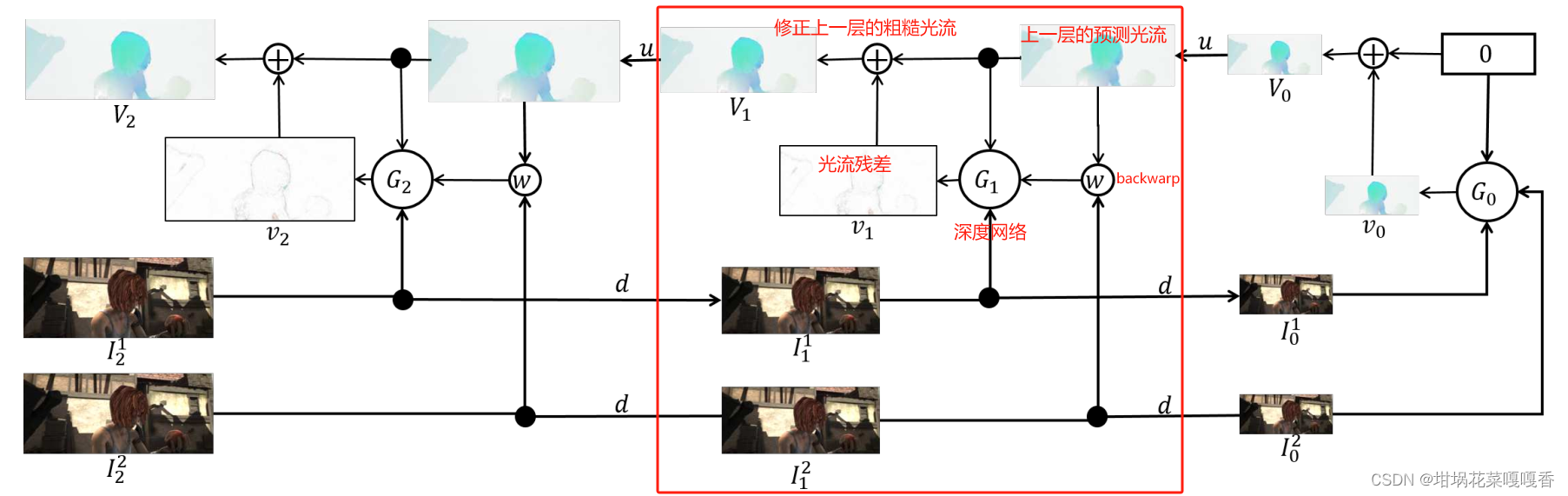
其中可以明显看到每一层的网络结构大致相同,故这里取其中一层的结构进行说明,如红框所示,首先需要有上一层网络产出的预测光流(需要通过u上采样达到目标分辨率,或者双线性插值)。对于深度网络G,输入深度网络的有三部分内容:上一层的预测光流,frame1,经过上一层预测光流backwarp的frame2;而输出深度网络的则为光流残差,需要与上一层的预测光流进行相加以实现这一尺度下的光流细化。
在最开始的情况下,直接暴力地设置初始光流为0,通过多尺度的空间特征与光流细化后得到目标尺度的光流。对于具体的公式表达,文章说明的比较详细,但最终表达的意思与网络结构图一致。
模型训练
根据文章描述,是对每一层的深度网络G进行依次训练,并不是一次性的端到端训练,其中Loss的定义如下图,即在前面的所有层的网络完成训练后,认定可以产出较为精准的光流,该层深度网络训练得到光流残差 v k v_k vk后,与当前尺度下的光流标签 V ^ k \hat V_k V^k和上一层预测光流的差 v ^ k \hat v_k v^k进行Loss计算,使用EPELoss。
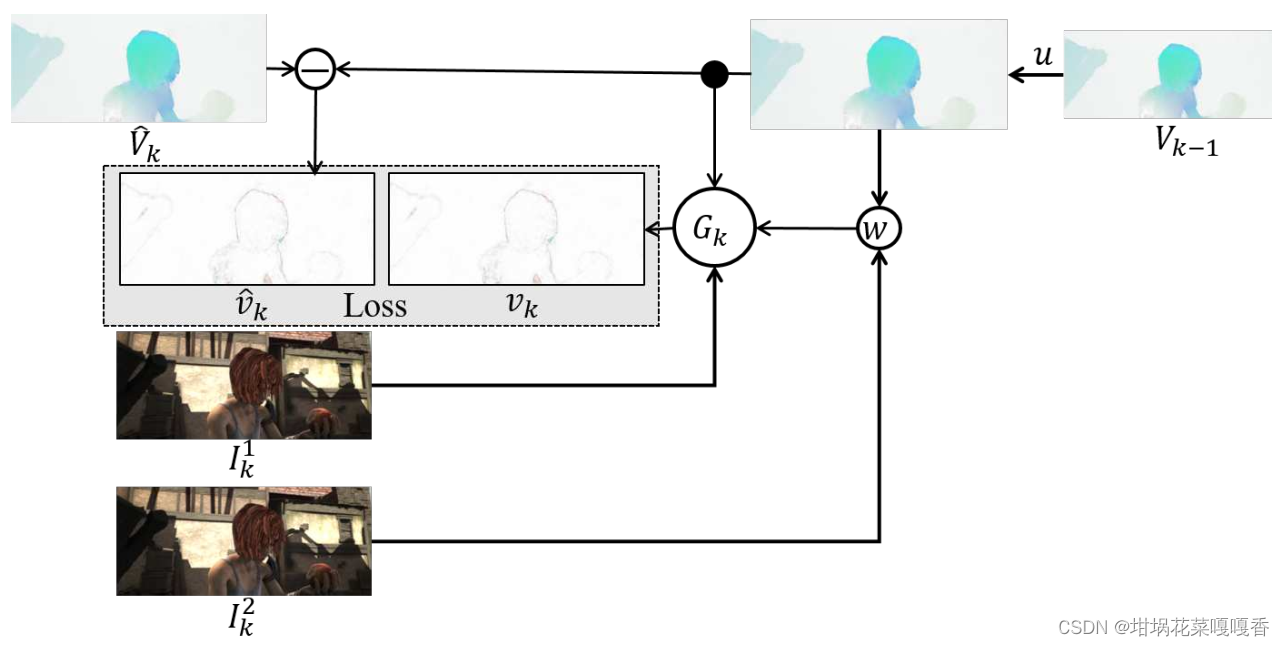
但为什么不能直接对加上光流残差修正后的光流进行监督呢?含义似乎是一样的。
这样分层训练的方式简化了模型的训练,相比于端到端的训练方法来说更省时间或容易收敛。(不知道能不能对多层光流同时进行监督?)
3.2.5 代码分析
开源代码中大部分训练代码给的为lua代码,但也给出了使用Pytorch框架编写的网络结构,为更好地理解网络结构,对代码进行分析(lua没学过)。
去除一些辅助代码,这里只看核心的网络架构。取自开源的Pytorch代码(https://github.com/sniklaus/pytorch-spynet),进行注释编写分析。
class Network(torch.nn.Module):
def __init__(self):
super().__init__()
# 为更好地训练模型,编写了一个图像归一化处理的过程代码
class Preprocess(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, tenInput):
# 翻转通道,为什么呢?
tenInput = tenInput.flip([1])
# 减去数据集的均值并除以标准差以实现图像的归一化
tenInput = tenInput - torch.tensor(data=[0.485, 0.456, 0.406], dtype=tenInput.dtype, device=tenInput.device).view(1, 3, 1, 1)
tenInput = tenInput * torch.tensor(data=[1.0 / 0.229, 1.0 / 0.224, 1.0 / 0.225], dtype=tenInput.dtype, device=tenInput.device).view(1, 3, 1, 1)
return tenInput
# 每层的光流残差训练的深度网络
class Basic(torch.nn.Module):
def __init__(self, intLevel):
super().__init__()
# 与论文实验部分说明一致,采用五个卷积层加ReLU激活函数
self.netBasic = torch.nn.Sequential(
# 说明为什么输入通道为8。
# 前面提及送入网络的三部分内容为:上一层的预测光流(2通道),frame1(3通道),经过上一层预测光流backwarp的frame2(3通道)
# 直接拼接融合即为8通道
torch.nn.Conv2d(in_channels=8, out_channels=32, kernel_size=7, stride=1, padding=3),
torch.nn.ReLU(inplace=False),
torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=7, stride=1, padding=3),
torch.nn.ReLU(inplace=False),
torch.nn.Conv2d(in_channels=64, out_channels=32, kernel_size=7, stride=1, padding=3),
torch.nn.ReLU(inplace=False),
torch.nn.Conv2d(in_channels=32, out_channels=16, kernel_size=7, stride=1, padding=3),
torch.nn.ReLU(inplace=False),
torch.nn.Conv2d(in_channels=16, out_channels=2, kernel_size=7, stride=1, padding=3)
)
def forward(self, tenInput):
return self.netBasic(tenInput)
self.netPreprocess = Preprocess()
# 每一层都有一个深度网络用于训练当前尺度的光流残差
self.netBasic = torch.nn.ModuleList([ Basic(intLevel) for intLevel in range(6) ])
def forward(self, tenOne, tenTwo):
tenFlow = []
# 用于存储不同尺度下的图像金字塔 开始就是原尺度
tenOne = [ self.netPreprocess(tenOne) ]
tenTwo = [ self.netPreprocess(tenTwo) ]
# 额外处理五层
for intLevel in range(5):
# 取金字塔顶部(最小的)图像,若宽高大于32则可以继续下采样
if tenOne[0].shape[2] > 32 or tenOne[0].shape[3] > 32:
# 使用均值池化获取低分辨率的图像, insert到list的第0位,则金字塔中的尺度是自小向大的
tenOne.insert(0, torch.nn.functional.avg_pool2d(input=tenOne[0], kernel_size=2, stride=2, count_include_pad=False))
tenTwo.insert(0, torch.nn.functional.avg_pool2d(input=tenTwo[0], kernel_size=2, stride=2, count_include_pad=False))
# 开始光流为0,shape除以2是因为每一层的操作都有一个光流上采样过程,为了同步编码,第0层也进行一个上采样,因此设置小一点的初始光流
tenFlow = tenOne[0].new_zeros([ tenOne[0].shape[0], 2, int(math.floor(tenOne[0].shape[2] / 2.0)), int(math.floor(tenOne[0].shape[3] / 2.0)) ])
# 遍历每一层
for intLevel in range(len(tenOne)):
# 对光流进行上采样,方式为双线性插值,缩放比为2,
tenUpsampled = torch.nn.functional.interpolate(input=tenFlow, scale_factor=2, mode='bilinear', align_corners=True) * 2.0
# 对上采样的光流尺寸进行修正,处理可能存在的尺寸不匹配问题,需要与金字塔图片的尺度进行匹配。
if tenUpsampled.shape[2] != tenOne[intLevel].shape[2]: tenUpsampled = torch.nn.functional.pad(input=tenUpsampled, pad=[ 0, 0, 0, 1 ], mode='replicate')
if tenUpsampled.shape[3] != tenOne[intLevel].shape[3]: tenUpsampled = torch.nn.functional.pad(input=tenUpsampled, pad=[ 0, 1, 0, 0 ], mode='replicate')
# 将前面提及的三部分送入深度网络训练,得到光流残差最后加上上采样后的前一层的预测光流
# tenOne[intLevel] 第一帧
# backwarp(tenInput=tenTwo[intLevel], tenFlow=tenUpsampled) 通过当前光流backwarp后的第二帧
# tenUpsampled 当前预测光流
tenFlow = self.netBasic[intLevel](torch.cat([ tenOne[intLevel], backwarp(tenInput=tenTwo[intLevel], tenFlow=tenUpsampled), tenUpsampled ], 1)) + tenUpsampled
return tenFlow
3.3 RAFT-基于多尺度4D相关体查找与GRU的迭代光流更新网络
3.3.1 论文及其链接
论文:ECCV2020, Recurrent All-Pairs Field Transforms for Optical Flow
链接:ecva.net/papers/eccv_2020/papers_ECCV/papers/123470392.pdf
3.3.2 文章摘要
我们介绍了循环全对场变换(RAFT),这是一种用于光流的新型深度网络架构。RAFT提取每个像素的特征,为所有像素对构建多尺度4D相关性体,并通过一个循环单元迭代地更新流场,该单元在相关性体上执行查找操作。RAFT实现了最先进的性能。在KITTI数据集上,RAFT实现了5.10%的F1-all误差,比最佳发布结果(6.10%)减少了16%的误差。在Sintel(最终通行证)上,RAFT的端点误差为2.855像素,比最佳发布结果(4.098像素)减少了30%的误差。此外,RAFT在推理时间、训练速度和参数数量方面具有高效率,具有强大的跨数据集泛化能力。
3.3.3 文章亮点
- 采用多尺度的4D相关体,即相关体金字塔,通过预处理该金字塔结合后续的查表操作,可以描述一个flow所带来的映射像素的多尺度相关性
- 采用GRU对光流进行不断的修正与更新。
3.3.4 网络结构
RAFT的整体结构如下,后文进行分模块分析。
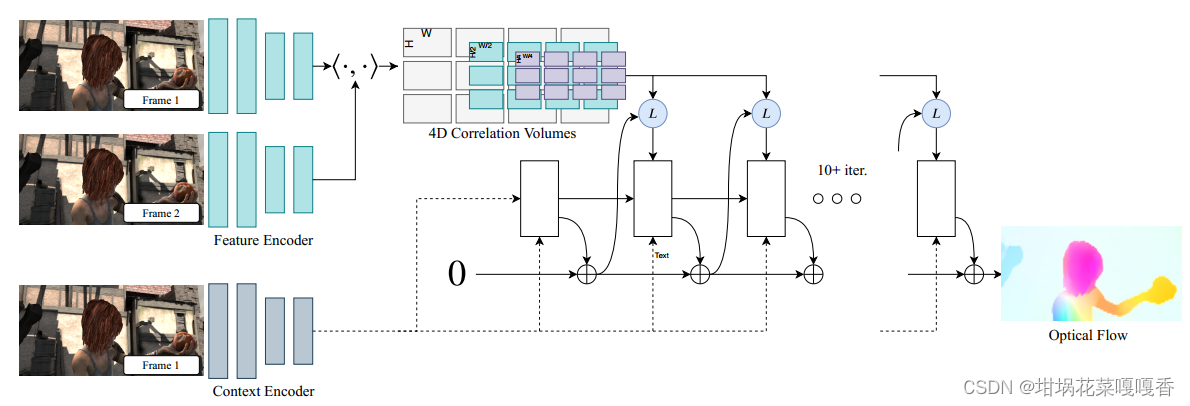
特征提取网络
即上图中的Feature Encoder和Context Encoder,分别进行图像特征和语义特征的提取。其中Feature Encoder导出低分辨率的密集特征图。(对于特征提取无非是卷积操作,这里也不深究特征提取到什么程度了,到后面看看对特征图进行怎样的处理)
4D相关体(4D Correlation Volumes)计算
看结构图可以看到一个点积的符号,联想到对特征向量的点积操作,这里和FlowNet中的关联矩阵计算很类似,只是这里只考虑两个像素之间的特征相关性,并没有选定某一个范围进行区域相关性计算。公式如下,本质上就是将两个像素(比如第一张图的(i,j)和第二张图的(k,l))对应的特征进行点积得到一个特征值,那么像素两两进行相关性计算即可得到一个4维(H×W×H×W)的相关矩阵,通称为4D相关体,表示
I
1
I_1
I1每一个像素点与每一个
I
2
I_2
I2像素点的相关度。
C
i
j
k
l
=
∑
h
g
θ
(
I
1
)
i
j
h
⋅
g
θ
(
I
2
)
k
l
h
C_{ijkl}=\sum_{h}g_{\theta}(\mathbf{I_1})_{ijh}·g_{\theta}(\mathbf{I_2})_{klh}
Cijkl=h∑gθ(I1)ijh⋅gθ(I2)klh 相关性金字塔(Correlation Pyramid)
但实际上,frame1(前文说是 I 1 I_1 I1)的像素不可能与frame2的每一个像素都有关联(可能还有其它更深层的考虑),作者再4D相关体的后两个维度上进行下采样,得到了4层的相关体,其中尺寸从大到小分别为H×W×H×W、H×W×H/2×W/2、H×W×H/4×W/4、H×W×H/8×W/8,这里也在一定程度上隐含了像素和某一个区域的相关性。如下图所示。

查表Lookup
这一部分论文写的相对难以理解,不过可以去读源码辅助理解。
由于RAFT主要进行的是光流的迭代更新,对于每一次产出的光流,可以表示为(
f
1
,
f
2
\mathbf{f}^{1},\mathbf{f}^{2}
f1,f2),对于frame1中的一个像素点
x
(
u
,
v
)
\mathbf{x}(u,v)
x(u,v),通过光流找到frame2中的对应点
x
′
(
u
+
f
1
(
u
)
,
v
+
f
2
(
v
)
)
\mathbf{x'}(u+\mathbf{f}^{1}(u),v+\mathbf{f}^{2}(v))
x′(u+f1(u),v+f2(v)),在
x
′
\mathbf{x'}
x′的基础上,作者定义了一个领域网格
N
r
(
x
′
)
N_r(\mathbf{x'})
Nr(x′),表达式如下:
N
r
(
x
′
)
=
{
x
′
+
d
x
∣
d
x
∈
Z
2
,
∣
∣
d
x
∣
∣
1
≤
r
}
\mathbf{N_r(x')} = \{ \mathbf{x'}+\mathbf{dx}\ |\ \mathbf{dx}\in \mathbb{Z}^2, ||\mathbf{dx}||_1 \le r \}
Nr(x′)={x′+dx ∣ dx∈Z2,∣∣dx∣∣1≤r} 相当于这个领域网格就是以当前预测光流的映射关系下,找到对应像素点的一个领域范围内,并在这个领域范围内去查找相关性金字塔,将查询得到的值进行组合得到一个新的向量,该向量就是Lookup的输出结果。(不太标准地概括这种思路:对于任意一个flow,在4D相关体上查询frame1的像素在该flow的作用下的映射像素之间的多尺度关联性,关联性越高那么显然这个flow的映射更贴近真实情况,这样便给与网络一种描述flow准确度的手段)
相当于这个领域网格就是以当前预测光流的映射关系下,找到对应像素点的一个领域范围内,并在这个领域范围内去查找相关性金字塔,将查询得到的值进行组合得到一个新的向量,该向量就是Lookup的输出结果。(不太标准地概括这种思路:对于任意一个flow,在4D相关体上查询frame1的像素在该flow的作用下的映射像素之间的多尺度关联性,关联性越高那么显然这个flow的映射更贴近真实情况,这样便给与网络一种描述flow准确度的手段)
举个例子,比如r为9,那么对于每一个frame1的像素点,都可以在4D相关性金字塔的每一层中查询到81个相关性值,即为与邻域范围内所有像素点的相关性,而4层相关体则可以查询到4×81个相关性值(对于低像素的相关体,使用双线性采样器找到对应的位置即可),那么对于所有H×W个像素点,最终可以查询到规格[H,W,324]的向量。
对于上式,r如果较大,那么能够获取到的关联性数据就多,能够获取较大运动范围内的关联信息,反之则运动更为精细。
光流迭代更新(GRU)
GRU的大体结构和式子不作赘述,直接看以下网络结构,用于修正光流的产生。
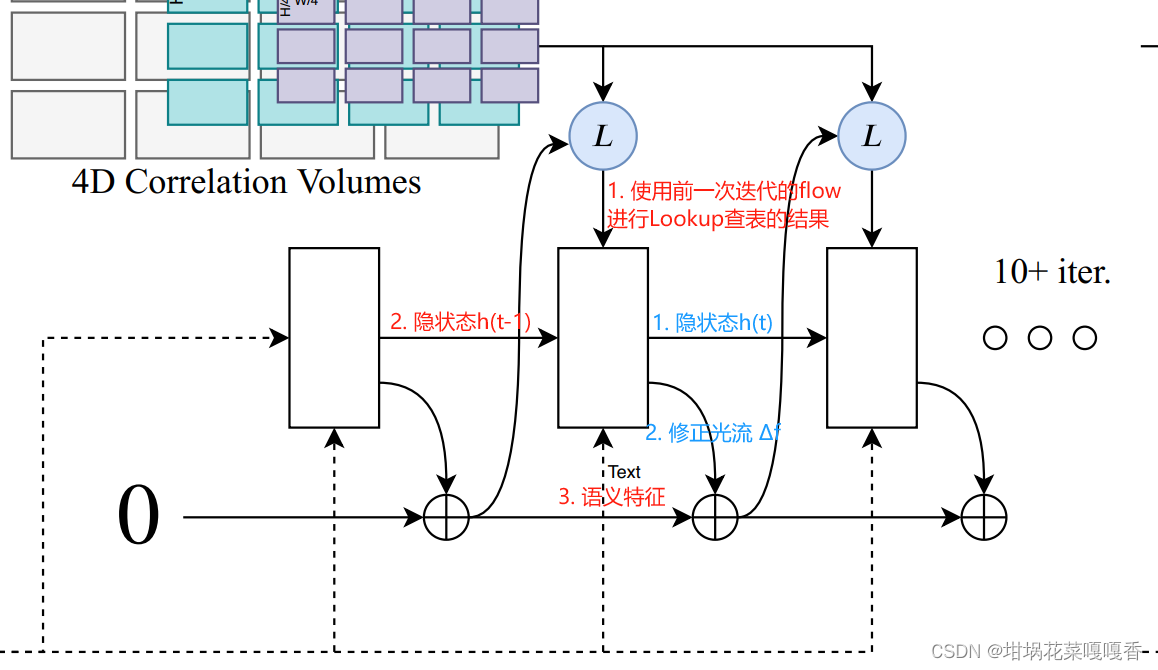
对于每一次迭代,GRU单元的输入(图中红色)包含:经过Lookup查表后的关联向量、隐状态、语义特征context feature;输出(图中蓝色)包含:更新后的隐状态,修正光流Δf,用于对上一次迭代的粗糙光流进行修正。
特别的是,训练过程中,作者并非直接取最后一次迭代的光流与实际光流计算Loss,而是对每一次迭代的光流都进行了Loss计算以监督。
这个思路与SPyNet略有点相似(也只是一点,在于使用深度网络训练残差光流,对光流进行细化),只是RAFT在全分辨率下不断进行光流的修正,能够实现每次迭代的监督,而SPyNet则是在多尺度下进行光流的细化。
【以下的内容等待进一步深入学习与笔记的细化】
3.4 GMA-基于全局运动信息
3.4.1 论文及其链接
论文:ICCV2021, Learning to Estimate Hidden Motions with Global Motion Aggregation
链接:Learning To Estimate Hidden Motions With Global Motion Aggregation (thecvf.com)
3.5 KPA-基于局部注意力
3.5.1 论文及其链接
论文:CVPR2022,Learning Optical Flow with Kernel Patch Attention
链接:Learning Optical Flow With Kernel Patch Attention (thecvf.com)
3.6 DIP-基于patchmatch降低4D相关体的计算
3.6.1 论文及其链接
论文:CVPR2022, DIP: Deep Inverse Patchmatch for High-Resolution Optical Flow
链接:DIP: Deep Inverse Patchmatch for High-Resolution Optical Flow (thecvf.com)
4. 光流的应用研究
由于最近在学习视频的语义分割,目前仅简单地看了几种光流法在视频语义分割上的应用。
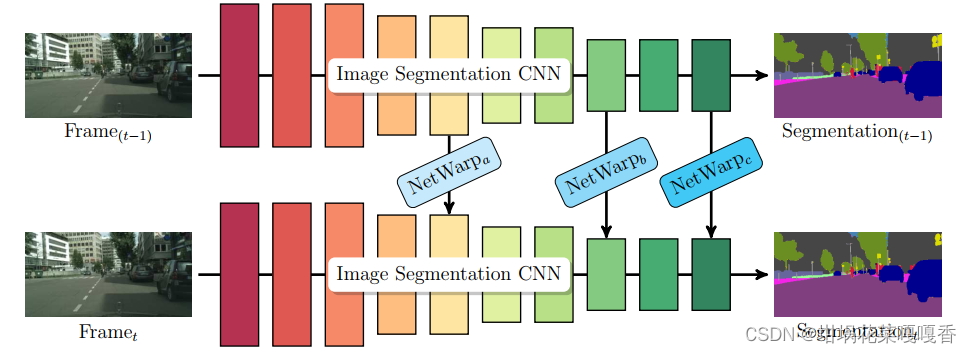
4.1 ICCV2017:Semantic Video CNNs through Representation Warping
使用offline的flow计算方法对前一帧的feature进行warp,但warp的是CNN过程中的层特征。提高精度。
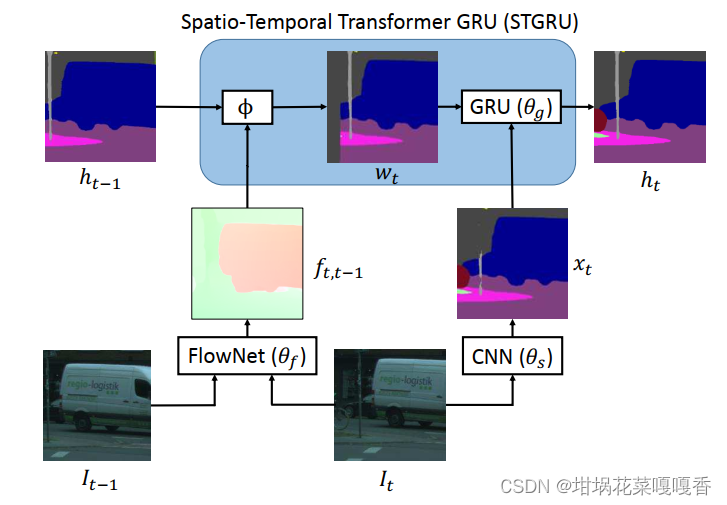
4.2 CVPR2018:Semantic Video Segmentation by Gated Recurrent Flow Propagation
将前一帧的mask进行warp,与当前帧直接计算的mask共同送入GRU,以实现前一帧mask对当前帧mask的弥补。提高精度。
4.3 CVPR2017:Deep Feature Flow for Video Recognition
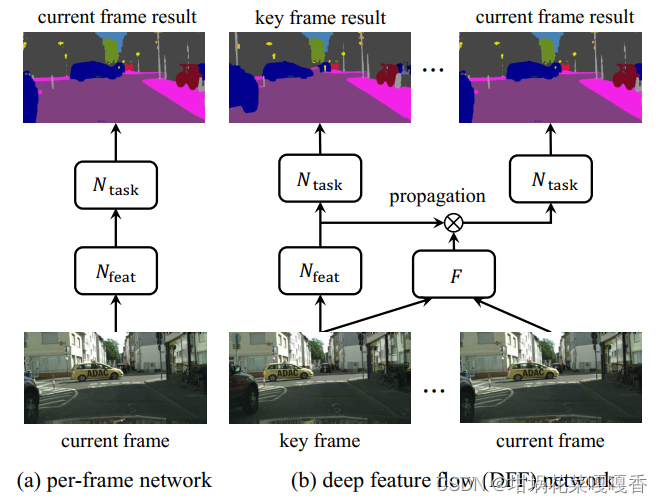
将前一帧(key frame)的feature通过flow作为当前帧的feature,减少重复的特征计算。
参考资料
optical flow光流方向问题 - 知乎 (zhihu.com)
光流、warp和grid_sample()_pytorch warp-CSDN博客
提取光流文件(.flo)为u,v二通道图像(作为网络输入)_光流flo 文件-CSDN博客
端点误差损失Endpoint error (EPE) loss - 知乎 (zhihu.com)
【光流评估】《Optical Flow Estimation using a Spatial Pyramid Network》2016 Tubingen, Germany-CSDN博客

















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









