






摘要:在实际应用中,由于不同数据集之间可能存在较大的差异以及缺乏有标记的训练样本,跨多个数据集的行人重识别( Person Re-identification,Re-ID )是一项具有挑战性但又非常重要的任务。本文提出了一种新颖的无监督域适应框架,将有标记的源域(数据集)的判别性表示迁移到无标记的目标域(数据集)。给定骨干网中任意一幅图像的特征图,提出一种新颖的域自适应注意力模型( DAAM ),将特征图同时分离为领域共享特征( DSH )图和域特定( DSP )特征图。前者是可迁移的,用于帮助目标域中的Re - ID任务,而后者是建模的,以减轻因领域发散而导致的负迁移。然后,在网络中引入一个DSH分支和一个DSP分支,分别学习这两个特征图。此外,我们提出将领域适应任务建模为一个具有新颖领域相似度损失的单类分类问题,并提出了一种新颖的行人重识别损失,通过估计弱标签和加权交叉熵损失来充分利用未标记的目标数据。
本文的主要技术贡献主要体现在以下三个方面:
- 提出了一种新的领域自适应注意力模型,将图像的特征图自动分离为领域共享特征图和特定领域的特征图。
- 提出了一种新的问题描述方式,将领域自适应任务转化为单类分类任务,并引入了领域相似性损失。-
- 提出了一种新的基于聚类过程和加权交叉熵损失的无监督行人重识别损失
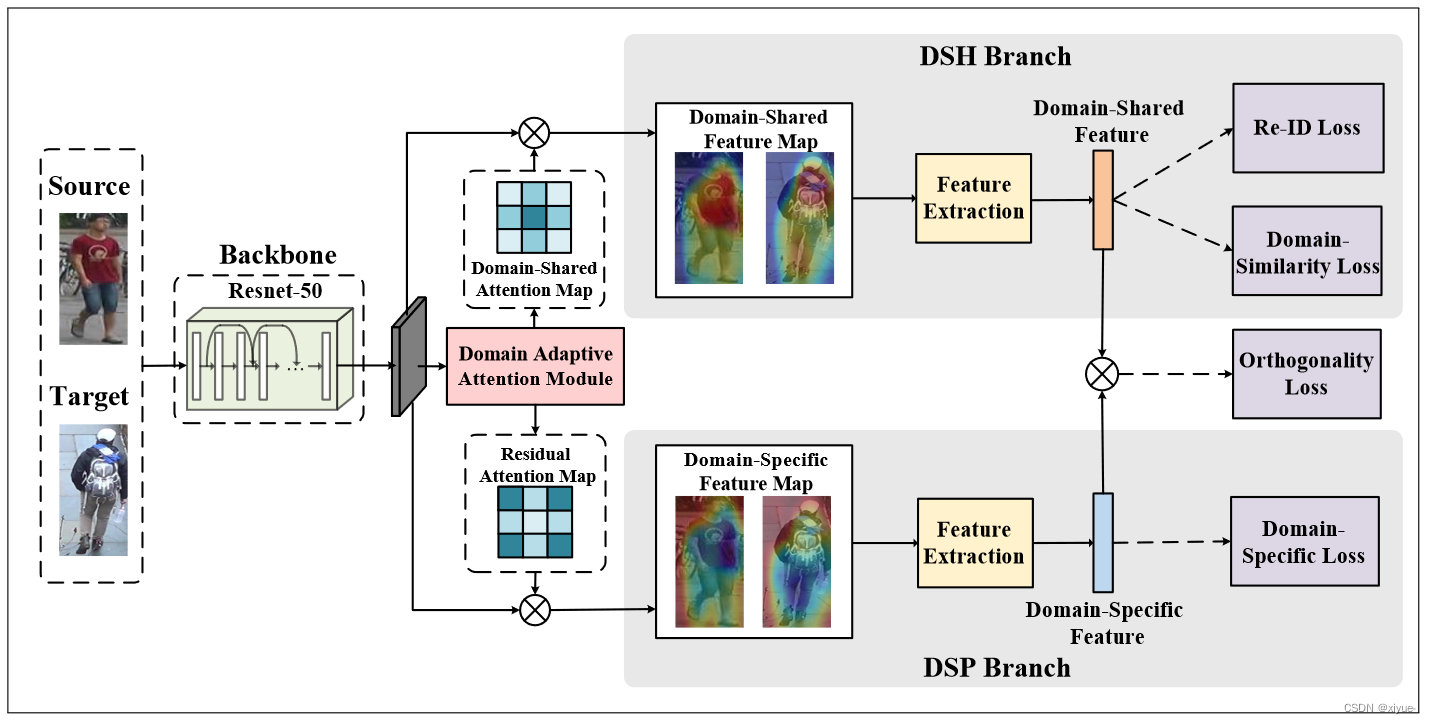
图3.所提方法的框架。域自适应注意力模块将特征图同时分为域共享 (DSH) 和域特定特征图。然后,引入DSH分支和DSP分支,分别学习这两个特征图。DSH分支采用Re-ID丢失和域相似性丢失,使DSH特征对不同的人具有区分性,并可转移到不同的域。相反,利用域特异性损耗使DSP分支捕获域可区分信息,以避免分散DSH特征的注意力。最后,引入软正交约束,使这两部分互补可分离。
损失函数:
1.相似域损失(Domain Similarity Loss):
具体而言,将256×1FC层和 sigmoid 激活函数依次用于fxsh![]() ,以预测图像 x 是否属于新名义域的概率po(x)
,以预测图像 x 是否属于新名义域的概率po(x) ![]() ,域相似度损失为:
,域相似度损失为:
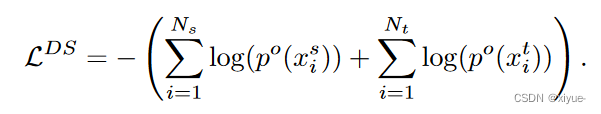
2. 人员重新识别损失(Person Re-ID Loss):
一个 256 × Nids![]() 个 FC层和一个 softmax 激活函数在 fxsh
个 FC层和一个 softmax 激活函数在 fxsh![]() 之后依次执行,以输出图像 x 来自人 y 的概率 {pid(y∣x)}y=1Nids
之后依次执行,以输出图像 x 来自人 y 的概率 {pid(y∣x)}y=1Nids![]() 。然后该交叉熵损失计算为:
。然后该交叉熵损失计算为:
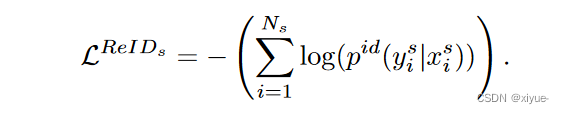
其中 {pid(y∣x)}k=1K![]() 是通过依次执行 256×KFC层和 softmax 函数来计算的fxsh
是通过依次执行 256×KFC层和 softmax 函数来计算的fxsh![]()
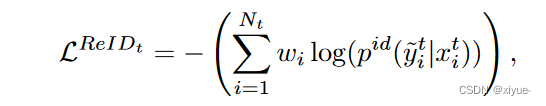
引入由256 × 2FC层和softmax函数组成的域分类器,用于预测图像x分别来自源域或目标域的概率(ps(x)![]() 和pt(x))
和pt(x))![]() 。
。
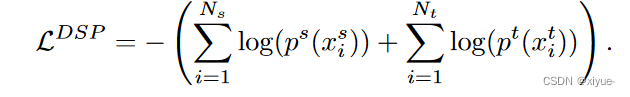
3. 软正交约束损失写成如下:
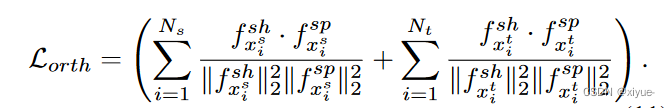
4.总损失函数定义为:
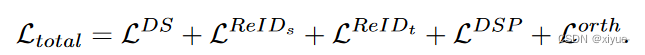
学习过程:
在学习过程中,我们首先仅使用LReIDs![]() 以监督方式在标记的源数据集上预训练网络。然后,利用预训练模型提取目标数据的{fxsh}x∈Dt
以监督方式在标记的源数据集上预训练网络。然后,利用预训练模型提取目标数据的{fxsh}x∈Dt![]() ,通过对{fxsh}x∈Dt
,通过对{fxsh}x∈Dt![]() 进行聚类方法估计目标数据的弱标签{yx}x∈Dt
进行聚类方法估计目标数据的弱标签{yx}x∈Dt![]() ,用{fxsh}x∈Dt
,用{fxsh}x∈Dt![]() 计算方程(8)中的样本权重。其次,通过最小化源数据集和目标数据集的Ltotal
计算方程(8)中的样本权重。其次,通过最小化源数据集和目标数据集的Ltotal![]() 来更新整个网络,并提取新的{fxsh}x∈Dt
来更新整个网络,并提取新的{fxsh}x∈Dt![]() 。然后,通过新的{fxsh}x∈Dt
。然后,通过新的{fxsh}x∈Dt![]() 更新弱标签和样本权重,我们通过更新的弱标签和样本权重重新训练网络以进入下一次迭代。当满足停止条件时,迭代终止,在我们的实验中,迭代次数通常< 10 次。总结了所提出的学习方法。
更新弱标签和样本权重,我们通过更新的弱标签和样本权重重新训练网络以进入下一次迭代。当满足停止条件时,迭代终止,在我们的实验中,迭代次数通常< 10 次。总结了所提出的学习方法。
总结:
在该文中,我们提出了一种用于ReID任务的新型无监督跨域迁移学习网络架构。它与现有方法有很大不同,因为它可以通过联合建模域共享和域特定特征,将知识从标记数据集转移到未标记的数据集。在Market-1501和DukeMTMC-reID数据集上进行了大量实验,证明了所提模型的有效性和鲁棒性。
本文内容来自于论文:Domain Adaptive Attention Learning for Unsupervised Cross-Domain Person Re-Identification















 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









