






 文章介绍了一种新的无监督领域自适应行人重识别方法,利用相机驱动的课程学习框架,通过相机标签分步转移知识,引入CD损失解决相机偏差问题,实现在标准基准上的有效性提升。
文章介绍了一种新的无监督领域自适应行人重识别方法,利用相机驱动的课程学习框架,通过相机标签分步转移知识,引入CD损失解决相机偏差问题,实现在标准基准上的有效性提升。
摘要:提出了一种新的无监督域自适应行人重识别方法( reID ),该方法将在已标记的源域上训练的模型推广到未标记的目标域。我们引入了一个相机驱动的课程学习( CaCL )框架,该框架利用人物图像的相机标签来逐步将知识从源领域转移到目标领域。为此,我们根据相机标签将目标域数据集划分为多个子集,并使用单个子集(也就是说,由单个摄像机捕获的图像)初步训练我们的模型。然后,我们根据由相机驱动的调度规则获得的课程序列,逐步开发更多的子集用于训练。调度器考虑每个子集与源域数据集之间的最大均值差异( MMD ),使得距离源域较近的子集在课程中被较早地利用。对于每个课程序列,我们以监督的方式生成目标域中人物图像的伪标签来训练reID模型。我们观察到伪标签高度偏向于相机,这表明从同一相机获得的人物图像很可能具有相同的伪标签,即使对于不同的ID。为了解决相机偏差问题,我们还引入了相机多样性( Camera-diversity,CD )损失,鼓励具有相同伪标签,但在不同相机之间捕获的行人图像,以更多地参与判别性特征学习,提供对相机间变化鲁棒的行人表示。在标准测试集上的实验结果,包括真实到真实和合成到真实的场景,证明了我们的框架的有效性。
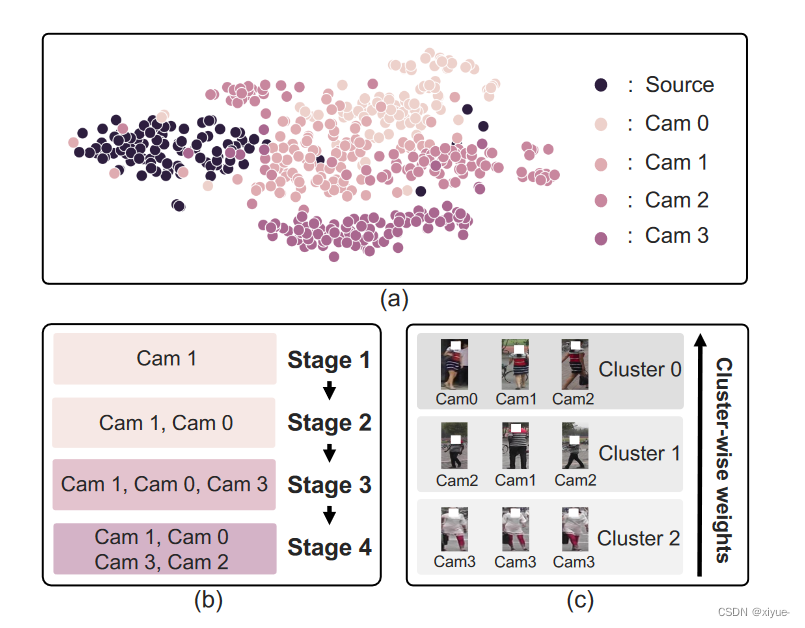
Fig 1:我们在( a )中可视化了从Market1501 [ 55 ]和MSMT17 [ 45 ]中提取的人物图像特征的t - SNE图,使用在MSMT17上训练的reID模型,其中MSMT17和Market1501分别是源域和目标域。目标域中来自不同摄像头的样本通过不同的颜色进行区分。在单个域上训练的模型为其他域提供了高度偏向于人物图像相机标签的特征。我们提出建立一个相机驱动的课程,如( b )所示,并使用单个相机捕获的图像初步训练我们的模型,然后逐步利用使用多个相机捕获的更多图像。为了进一步缓解相机偏差问题,我们计算聚类权重,如( c )中,以鼓励包含从不同相机获得的图像的聚类在自适应过程中更多地参与。
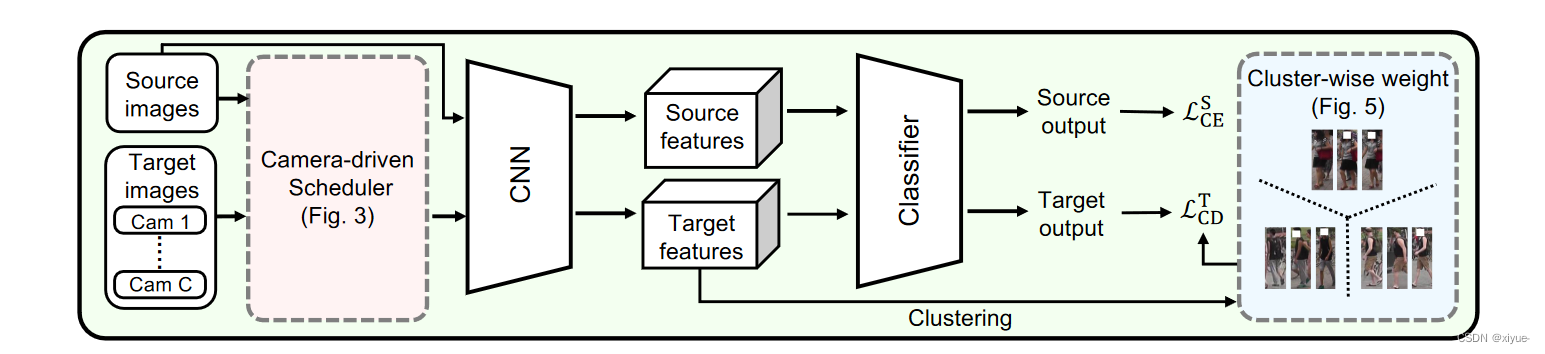
Fig 2: 我们在图2中提供了我们的UDA reID框架的概述。我们首先利用行人图像的相机标签将目标数据集划分为多个子集。相机驱动的调度器将目标子集和源图像作为输入,建立课程序列。在每个课程序列中,我们采用自训练方案,并在聚类和微调之间交替进行。具体来说,我们在从目标图像中提取的人物特征上应用聚类算法来生成伪ID标签,并进一步使用源图像和目标图像的联合集来微调我们的模型。我们结合了目标图像的CD损失,以考虑每个集群中相机标签的多样性。在测试时,我们计算查询和画廊人员表示之间的 L2 距离,以执行跨摄像机匹配。请注意,相机标签仅在训练期间使用。
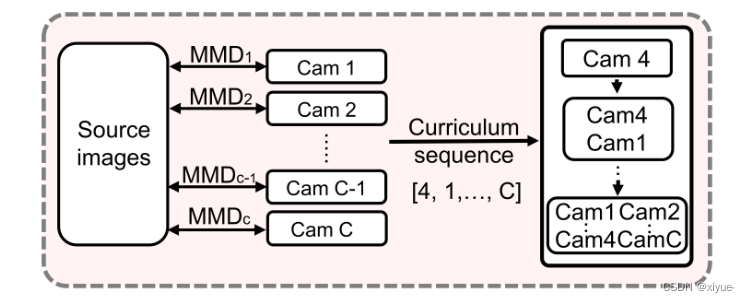
Fig 3: 相机驱动调度器的光照。我们计算源域和所有目标子集之间的成对MMD,建立课程序列。我们首先使用单个子集训练我们的模型,然后通过在序列中添加子集来逐步扩展训练集。
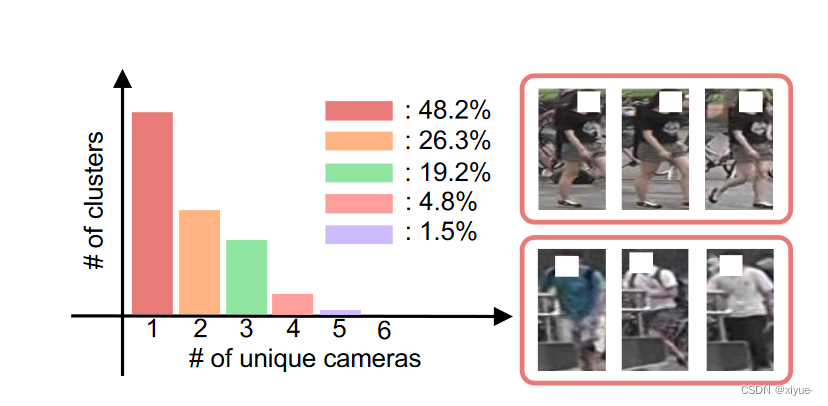
Fig 4: 左边:簇的数量分布,独特的摄像头数量。我们使用在MSMT17 [ 45 ]上训练的reID模型在Market1501 [ 55 ]上得到了结果。由于在单个域上训练的行人重识别模型无法在其他域上泛化,大多数聚类只包含单个摄像头捕获的行人图像。右:同一簇内人物图像的实例。我们可以看到行人图像并没有表现出多样化的类内变化( top ),而且聚类结果容易受到干扰线索的影响
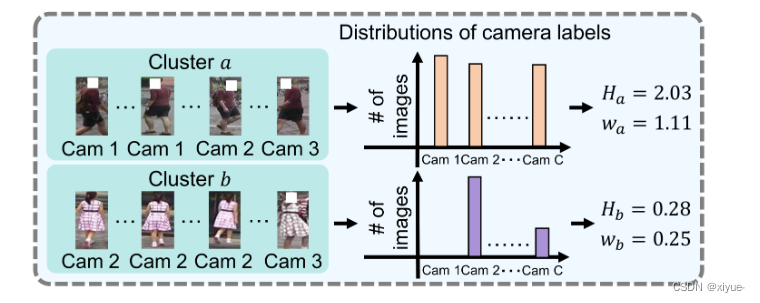
Fig 5: 图示为计算聚类权重因子的详细过程。我们计算每个簇的相机分布的熵,然后为具有高熵值的簇分配大的权重。
摄像头驱动的调度器CaCl:
我们使用MMD [ 16 ]来实现这个想法,该方法计算不同域之间的分布差异。具体来说,我们通过将样本映射到与高斯核相关的函数φ ( · )的再生核希尔伯特空间H中,来计算源数据集DS和目标子集DT c之间的成对MMD,具体如下:
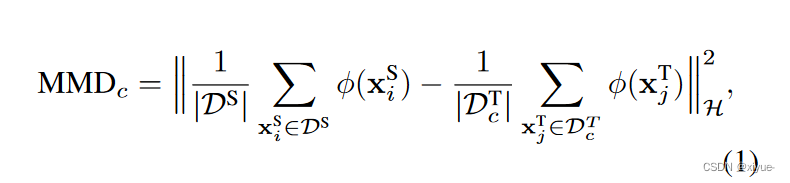
其中xiS和xjT分别表示DS和DT c中的第i个和第j个样本,| · |表示集合中样本的总数.我们通过对成对的MMD进行升序排序来建立课程序列,即在MMD方面与源域更接近的子集被更早地利用。
我们引入聚类权重wl,以增强用于训练reID模型的交叉熵和三元组项。具体地,给定一个分配到第l个簇的人物图像xiT,我们定义CD交叉熵项如下
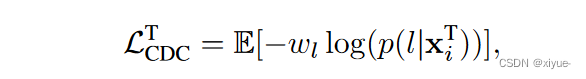
其中p ( l | xiT )是xiT被分类到第l个伪ID标签的softmax概率。CD三元组术语LT CDT也有类似的定义。值得注意的是,对于第一个课程序列,输入的目标图像是从单个相机拍摄的,我们省略了权重因子,并使用香草交叉熵和三元组损失进行训练。
为了为未标记的目标域生成伪ID标签,先前的方法在目标图像的行人表示上应用了聚类算法。然而,我们观察到,对于目标图像的聚类结果高度偏向于相机标签。我们在图4中表明,大多数簇(高达48.2 %)是平凡的,包含使用单个相机获得的图像。直接使用标准交叉熵和三元组[损失对有偏伪ID标签进行训练可能是次优的,因为平凡的聚类可以主导适应过程。注意到这一点对于进行跨摄像头图像检索的reID来说尤为重要。为了缓解这个问题,我们提出抛弃琐碎的聚类,同时鼓励来自不同相机的图像簇更多地参与特征学习。为此,我们对每个聚类的相机分布的熵进行度量,如下所示:

我们使用传统的交叉熵和三元组损失使用源图像的真实ID标签预训练一个reID模型。我们用相机驱动的调度器建立课程,然后进行聚类,以获得目标图像的伪ID标签。在微调过程中,我们联合利用源域和目标域,遵循。我们对源图像采用交叉熵损失( LS CE ),对目标图像采用CD项( LT CD ),其中CD损失由CD交叉熵和CD三元组项组成。在每个微调阶段,我们优化一个reID网络,总体目标如下:
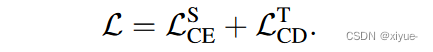
贡献:
我们的主要贡献可以概括如下:( 1 )我们提出了一种新颖的UDA reID课程学习框架,该框架利用了人物图像的相机标签。据我们所知,这是第一个纳入UDA reID的课程学习方案。我们还给出了相机驱动的调度器,用于确定目标域中多个子集的课程顺序。( 2 )我们提出了CD损失来学习具有辨别力的行人表示,特别是对相机间的变化具有鲁棒性,即使在使用偏向相机标签的伪标签训练时也是如此。( 3 )我们在UDA reID的标准基准上设定了新的技术状态,包括真实到真实和合成到真实的场景,并证明了我们的框架的有效性。
本文内容来自于论文:Camera-Driven Representation Learning for Unsupervised Domain Adaptive Person Re-identification















 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









