







刷机需谨慎,小心变砖。请提前备份重要数据,此文仅做参考
前言
我的小米平板5买来快吃灰两年半了,最近听说可以给pad5刷一个小米澎湃OS+Windows11的双系统。于是,我也打算给我的pad整个双系统玩玩。
查询了相关资料后,发现需要先解锁BL锁。(出厂即为澎湃OS系统的不用看了)出厂为miui升级为hyperOS的可以采用这种方法解锁BL锁
一、准备
硬件
一台小米平板5,6+256G版本
一根USB转Type-C数据连接线
一台笔记本电脑
软件
1.小米解锁工具
2. php安装包
3.脚本及配置文件
二、BL锁解锁步骤
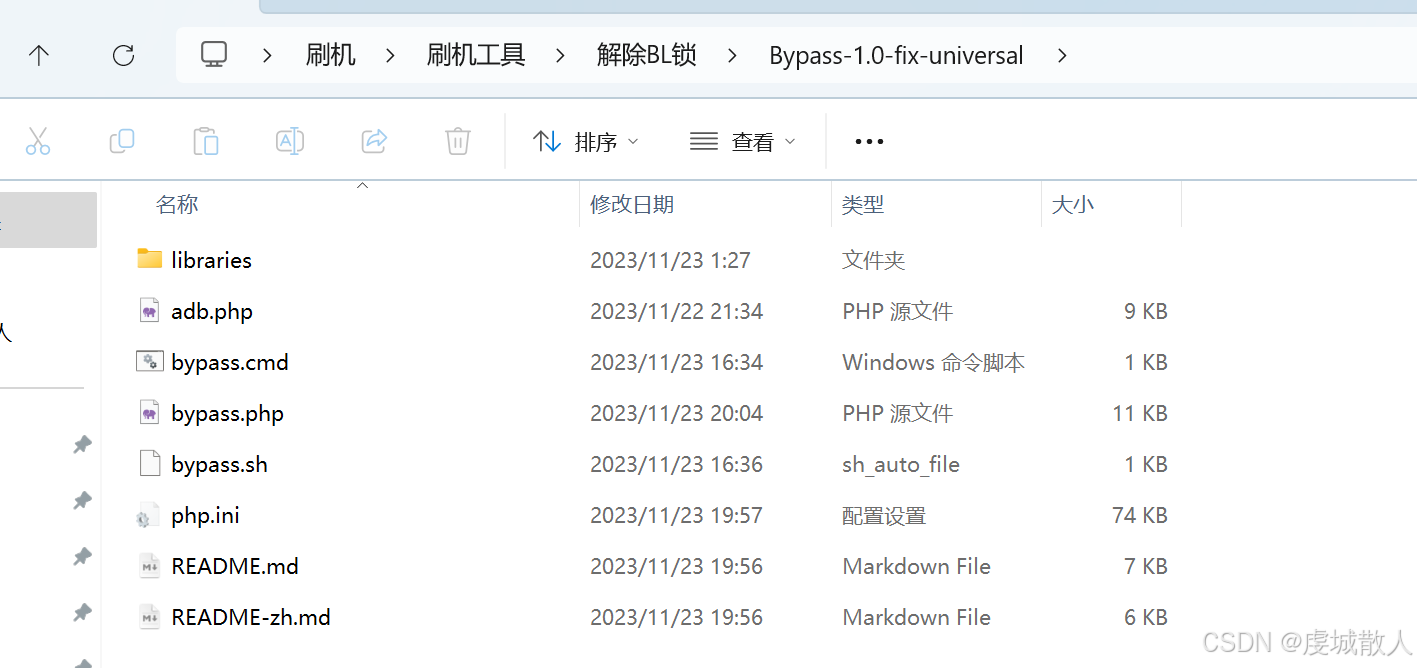
1.将脚本及配置中的文件复制粘贴到php解压包中
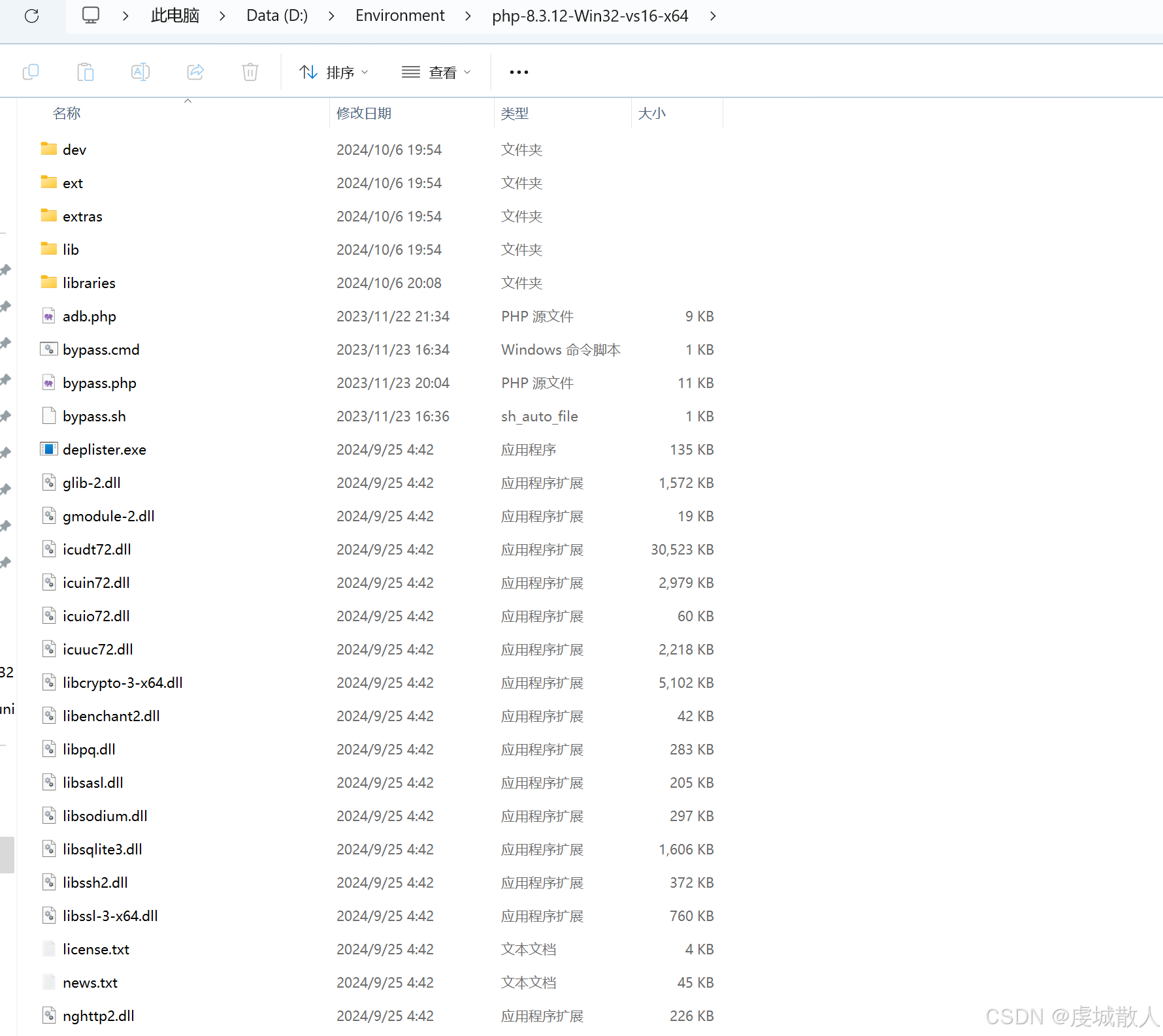
2.修改php文件夹下php.ini文件夹
注意:如果不加上路径,脚本可能找不到扩展包,而导致程序运行错误

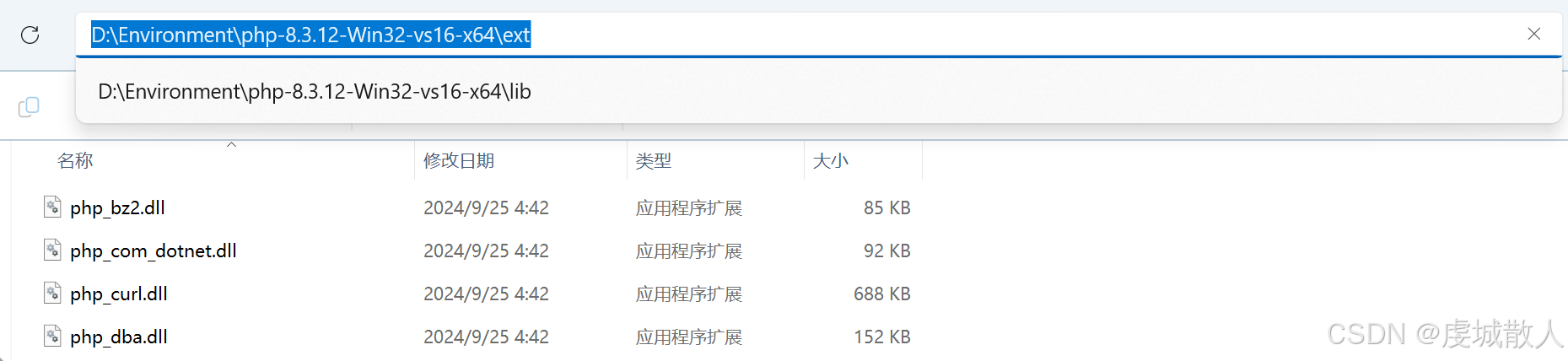
将php.ini文件下的on windows前的分号去掉,并在extension_dir上添加上扩展包的路径
3.平板开启设备开发者模式
打开usb调试,OEM解锁,进入设备解锁状态,usb线连接平板和电脑
4.点击php文件夹下的bypass.cmd
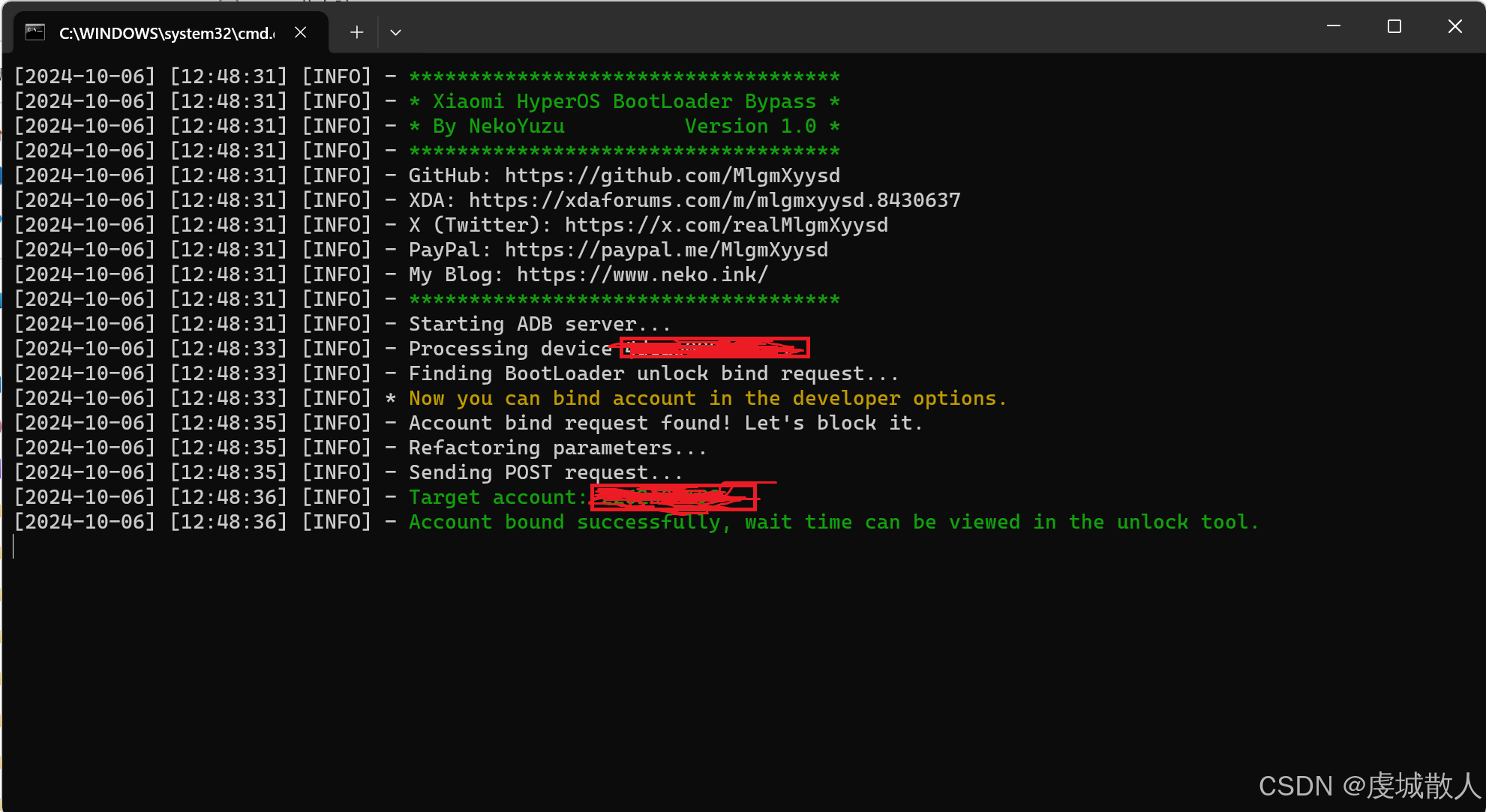
平板双击《绑定账号和设备》,显示解锁不了很正常,只要命令行显示绿色解锁成功就行。
如果在命令行显示报错,请详细阅读Bypass-1.0-fix-universal文件夹下的README.md。
5.打开平板fastboot模式
第一,将平板关机;
第二,同时按住音量减键和开关机键;
第三,看到LOGO后松手。
6.打开小米刷机工具
第一,双击miflash_unlock_7.6.727.43文件夹下的miflash_unlock.exe;
第二,扫码登录;
第三,连接平板;如果没有连接平板,可能缺乏驱动。双击MiUsbDriver.exe安装。
安装好后,依旧没有显示连接,拔数据线重连。
第四,确认解锁。
7.等待168个小时,也就是7天
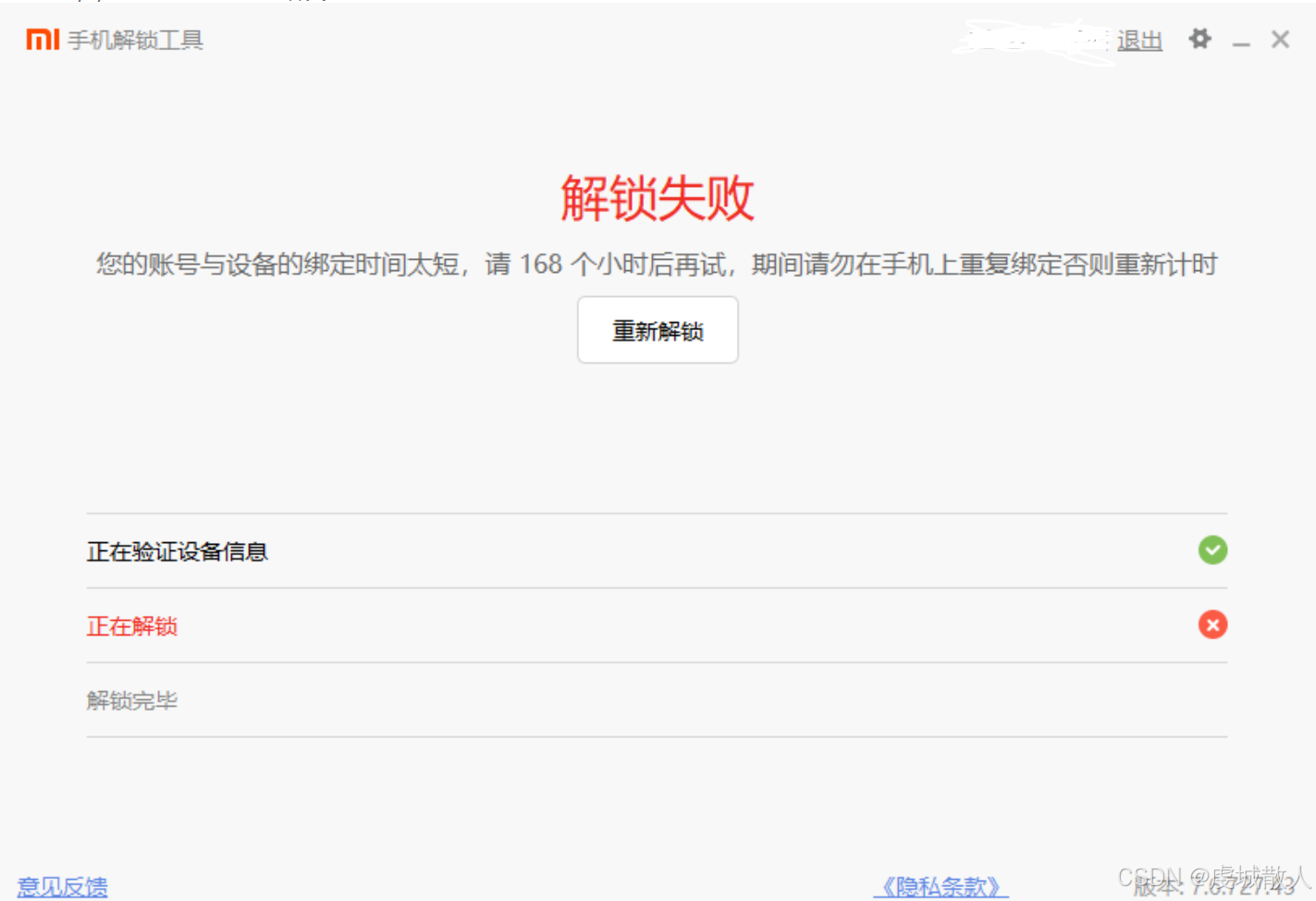
三、解锁成功
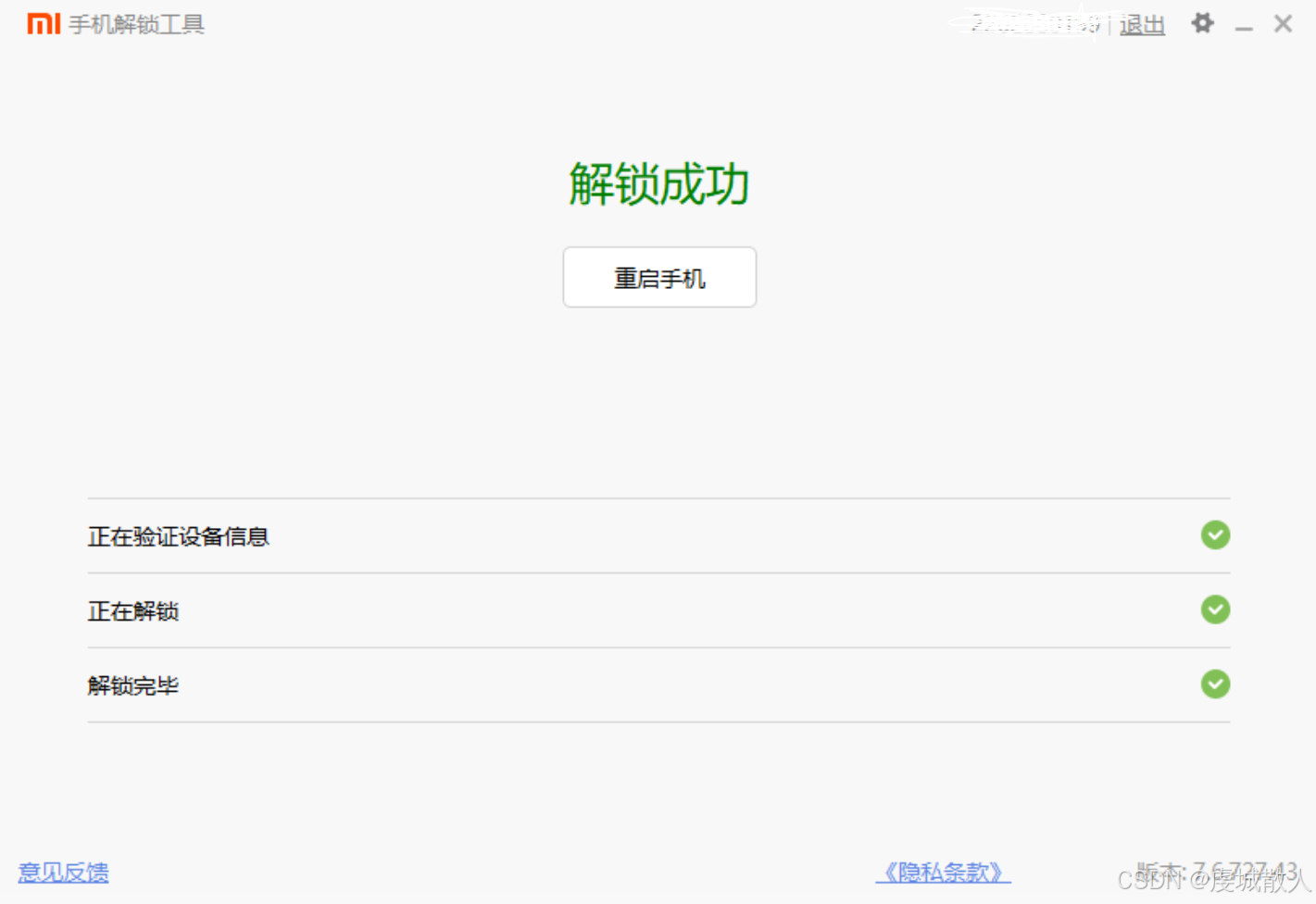
168个小时之后,重新登录解锁,好的解锁成功。可以进行后续的刷机工作了。

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









