






由tensorflow搭建一个简单的神经网络
既然上一篇讲了一些tensorflow的基本操作,那就直接拿来用一下吧,搭建一个简单前馈神经网络
Forward propagation
在我理解中,所谓的神经网络 无非是 累加的多层函数,通过数以千万的参数组成的一个参数矩阵,通过不断地叠加函数和参数,来达到拟合的目的。所有的神经网络 基本的流程是一样的,通过大量的数据集,来对函数的参数进行不停地迭代,达到最好的拟合效果。
本文将 使用tensorflow搭建一个简单的前馈神经网络
导入所需要的包
import tensorflow as tf
import cv2 as cv
from tensorflow import keras
from tensorflow.keras import datasets导入数据集
本次实验使用 mnist 的手写数据集 来进行训练和测试
拿到一个shape为[60k,28,28]的图片集 shape为[60k]的标签集
返还两个元组 解压赋值 将元组1 解压赋值给x,y
这里的图片类型为ndarray
(x,y),_ = datasets.mnist.load_data()将数据集转换为tensor类型
x = tf.convert_to_tensor(x,dtype=tf.float32)
y = tf.convert_to_tensor(y,dtype=tf.int32)将数据切分成组 使用tf.data.Dataset.from_tensor_slices((x,y)).batch(n) 函数
将60k份数据分为 128份为一组
train_db = tf.data.Dataset.from_tensor_slices((x,y)).batch(128)
train_iter = iter(train_db)
# 转为迭代器 看一下返回的数据的样子
data = next(train_iter)
print(data[0].shape,data[1].shape)
可以看到 单份数据 现在是 (128,28,28) (128,)的shape
搭建神经网络
下面我们搭建一个简单的三层向前传播神经网络
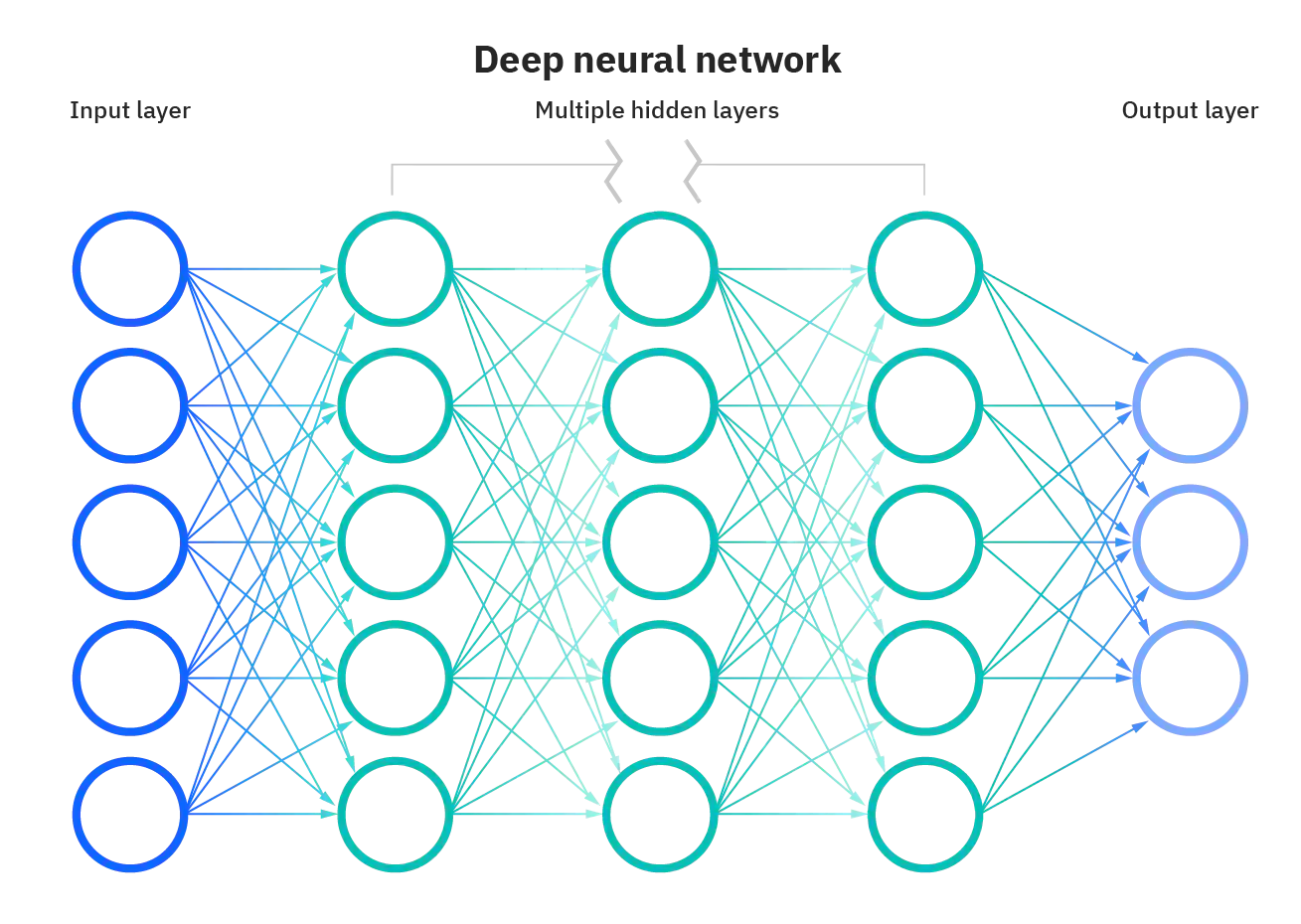
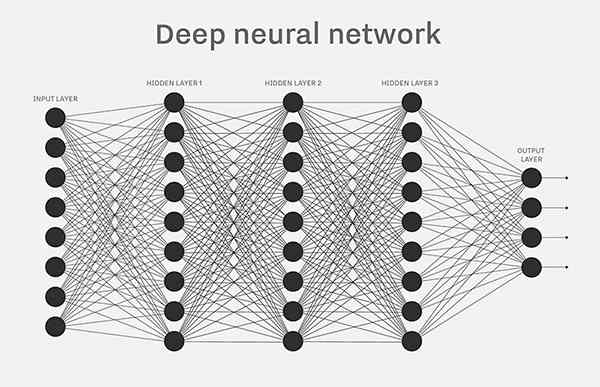
人工神经网络的基本原理见下图:
解析:
第一层是一张图片的(28 * 28)个像素点所对应的灰度值
第二层是自定义层本层的个数由自己来确定;第二层点的值 由第一层来计算
下图为第二层某点的计算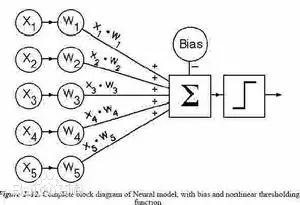
第三层同上
第四层同上
第五层为输出层,转为one-hot编码,及每个点对应的为一个结果 选取权最大的即为结果
本神经网络结构如下:
[b,784] --> [b,256] --> [b,128] --> [b,10]
由于一次性处理多张图片来进行向前传播,所以传入为[b,784]的一个矩阵。b代表一次性处理的图片数
所以由上述可知,我们需要设计w(权重矩阵)来进行计算 权重矩阵中的每一个都相当于一个参数
所以w矩阵的shape应该为下式
w [dim_in,dim_out] b[dim_out]
利用正态分布 生成初始w
w1 = tf.Variable(tf.random.truncated_normal([784,256],stddev=0.01))
b1 = tf.Variable(tf.random.truncated_normal([256]))
w2 = tf.Variable(tf.random.truncated_normal([256,128],stddev=0.01))
b2 = tf.Variable(tf.random.truncated_normal([128]))
w3 = tf.Variable(tf.random.truncated_normal([128,10],stddev=0.01))
b3 = tf.Variable(tf.random.truncated_normal([10]))
这是超参数 步长
lr = 1e-3x 是 当前 batch 数
循环训练十次
for i in range(10):对每个batch进行训练
for step,(x,y) in enumerate(train_db): #默认只会跟着 tf.Variable
x = tf.reshape(x,(-1,28*28))tf.GradientTape() 可以记录梯度值 为之后梯度下降使用
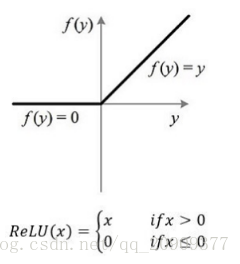
tf.nn.relu()是激活函数 就像神经必须要达到一定的值 才会有反应
在神经网络中对于每个神经元也是如此
with tf.GradientTape() as tape:
h1 = x @ w1 + b1
h1 = tf.nn.relu(h1)
h2 = h1 @ w2 + b2
h2 = tf.nn.relu(h2)
out = h2 @ w3 + b3向前传播后,得到一个误差loss 即正确结果和预测结果的偏差
# loss [b] -- > [b,10] 将标签 转为one_hot形式
y_onehot = tf.one_hot(y,depth=10)在这里将一个batch的误差进行中和
# loss = mean((正确结果 - 预处结果)^2 )这里求得是每张图片的误差的平方
loss = tf.square(y_onehot - out)这里是一个batch的误差值 即128张图片的误差均值
loss = tf.reduce_mean(loss)求解 loss 关于 w1,b1,w2,b2,w3,b3的梯度 就是loss关于w1,...b3的偏导数
代表了 loss 在 w1 。。。 b3 方向上的最大变化率
grads = tape.gradient(loss,[w1,b1,w2,b2,w3,b3])利用梯度下降算法 得到新的参数(预备知识: 导数 梯度 梯度下降 方向导数 偏导数 矩阵运算)
# 相减运算后 返回的是一个tensor类型 不是一个 tf.Variable类型 所以使用原地操作
w1.assign_sub(lr * grads[0])
w2.assign_sub(lr * grads[2])
w3.assign_sub(lr * grads[4])
b1.assign_sub(lr * grads[1])
b2.assign_sub(lr * grads[3])
b3.assign_sub(lr * grads[5])
if step % 100 == 0:
print(step,'loss:',float(loss))运行结果:
网络应用
从数据集得到数据,并且带入网络进行求解 输出one-hot编码的结果

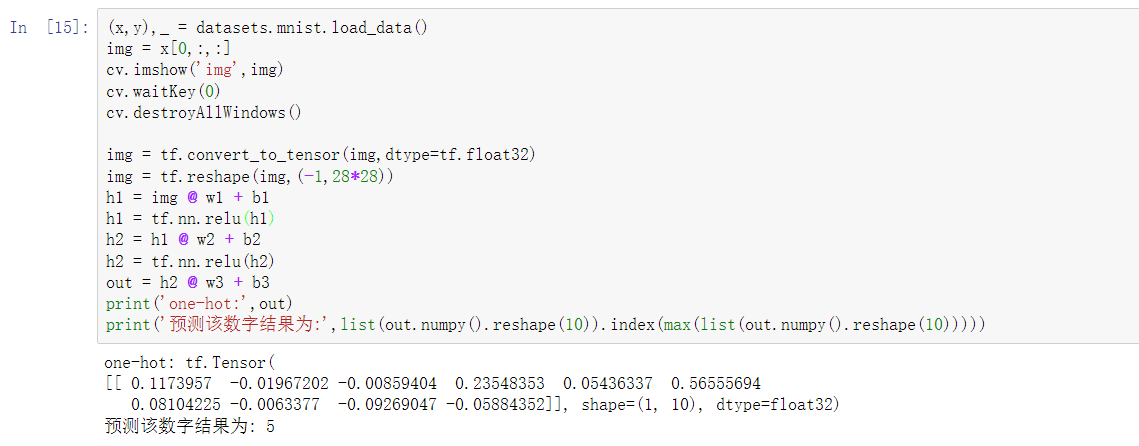
可以看到 效果还是挺不错的
完整代码
点击查看代码
import tensorflow as tf
import cv2 as cv
from tensorflow import keras
from tensorflow.keras import datasets
# 拿到一个[60k,28,28] [60k]的数据集
# 返还两个元组 解压赋值 将元组1 解压赋值给x,y
(x,y),_ = datasets.mnist.load_data()
# 这里的数据集是 ndarray类型
x = tf.convert_to_tensor(x,dtype=tf.float32)
y = tf.convert_to_tensor(y,dtype=tf.int32)
train_db = tf.data.Dataset.from_tensor_slices((x,y)).batch(128)
train_iter = iter(train_db)
data = next(train_iter)
print(data[0].shape,data[1].shape)
# 迭代器 返还一个元组 0代表图片 1代表标签
# 神经网络 向前传播
# [b,784] --> [b,256] --> [b,128] --> [b,10]
# w [dim_in,dim_out],[dim_out] 因为 第二层中的值 由 第一层中的 每个值的权重和决定
# 正态分布 生成初始w
w1 = tf.Variable(tf.random.truncated_normal([784,256],stddev=0.01))
b1 = tf.Variable(tf.random.truncated_normal([256]))
w2 = tf.Variable(tf.random.truncated_normal([256,128],stddev=0.01))
b2 = tf.Variable(tf.random.truncated_normal([128]))
w3 = tf.Variable(tf.random.truncated_normal([128,10],stddev=0.01))
b3 = tf.Variable(tf.random.truncated_normal([10]))
lr = 1e-3
# 前向运算 x 是 batch
for i in range(10):
for step,(x,y) in enumerate(train_db): #默认只会跟着 tf.Variable
# x[128,28,28]
# y[128]
x = tf.reshape(x,(-1,28*28))
with tf.GradientTape() as tape:
# x[b,784] * [784,256]
h1 = x @ w1 + b1
h1 = tf.nn.relu(h1)
h2 = h1 @ w2 + b2
h2 = tf.nn.relu(h2)
out = h2 @ w3 + b3
# loss [b] -- > [b,10] 将标签 转为one_hot形式
y_onehot = tf.one_hot(y,depth=10)
# loss = mean((正确结果 - 预处结果)^2 )
loss = tf.square(y_onehot - out)
loss = tf.reduce_mean(loss)
# 求解 loss 关于 w1,b1,w2,b2,w3,b3的梯度
grads = tape.gradient(loss,[w1,b1,w2,b2,w3,b3])
# 相减运算后 返回的是一个tensor类型 不是一个 tf.Variable类型
w1.assign_sub(lr * grads[0])
w2.assign_sub(lr * grads[2])
w3.assign_sub(lr * grads[4])
b1.assign_sub(lr * grads[1])
b2.assign_sub(lr * grads[3])
b3.assign_sub(lr * grads[5])
if step % 100 == 0:
print(step,'loss:',float(loss))
(x,y),_ = datasets.mnist.load_data()
img = x[0,:,:]
cv.imshow('img',img)
cv.waitKey(0)
cv.destroyAllWindows()
img = tf.convert_to_tensor(img,dtype=tf.float32)
img = tf.reshape(img,(-1,28*28))
h1 = img @ w1 + b1
h1 = tf.nn.relu(h1)
h2 = h1 @ w2 + b2
h2 = tf.nn.relu(h2)
out = h2 @ w3 + b3
print('one-hot:',out)
print('预测该数字结果为:',list(out.numpy().reshape(10)).index(max(list(out.numpy().reshape(10)))))














 3156
3156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









