







老师给的建议:
1,阅读原论文看公式,理解怎么来的【待】
2,github找资源学习(如风格迁移)【待】
3,熟悉代码,化为己用【待】
4,转置卷积
GAN|生成手写数字|全连接网络
import torch
import torch.nn as nn
from torch.utils.data import Dataset
import pandas,numpy,random
import matplotlib.pyplot as plt
#数据集-------------------------------------------------------------------------
class MnistDataset(Dataset):
def __init__(self, csv_file):
self.data_df = pandas.read_csv(csv_file, header=None)
def __len__(self):
return len(self.data_df)
def __getitem__(self, index):
label = self.data_df.iloc[index,0]
target = torch.zeros((10))
target[label]=1.0
image_values = torch.FloatTensor(self.data_df.iloc[index,1:].values)/255.0
return label, image_values, target
def plot_image(self, index):
arr = self.data_df.iloc[index,1:].values.reshape(28,28)
plt.title("label="+str(self.data_df.iloc[index,0]))
plt.imshow(arr, interpolation='none',cmap='Blues')
mnist_dataset = MnistDataset('mount/My Drive/Colab Notebooks/mnist_data/mnist_train.csv')
mnist_test_dataset = MnistDataset('mount/My Drive/Colab Notebooks/mnist_data/mnist_test.csv')
#训练鉴别器的随机图
def generate_random_image(size):
random_data = torch.rand(size)
return random_data
#训练生成器的随机种子
def generate_random_seed(size):
random_data = torch.randn(size)
return random_data
#鉴别器-------------------------------------------------------------------------
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(784,200),
nn.LeakyReLU(0.02),
nn.LayerNorm(200),
nn.Linear(200,1),
nn.Sigmoid()
)
self.loss_function = nn.BCELoss()
self.optimiser = torch.optim.Adam(self.parameters(), lr=0.0001)
self.counter = 0
self.progress = []
def forward(self, inputs):
return self.model(inputs)
def train(self, inputs, targets):
outputs = self.forward(inputs)
loss = self.loss_function(outputs, targets)
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0,0.25,1.0,0.5,5.0))
#训练鉴别器
D = Discriminator()
for label,image_data_tensor,target_tensor in mnist_dataset:
D.train(image_data_tensor,torch.FloatTensor([1.0]))
D.train(generate_random_image(784),torch.FloatTensor([0.0]))
#生成器-------------------------------------------------------------------------
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(100,200),
nn.LeakyReLU(0.02),
nn.LayerNorm(200),
nn.Linear(200,784),
nn.Sigmoid()
)
self.optimiser = torch.optim.Adam(self.parameters(), lr=0.0001)
self.counter=0
self.progress=[]
def forward(self, inputs):
return self.model(inputs)
def train(self, D, inputs, targets):
g_output = self.forward(inputs)
d_output = D.forward(g_output)
loss = D.loss_function(d_output, targets)
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0,0.25,1.0,0.5,5.0))
#生成器未经过训练生成的图像
G = Generator()
output = G.forward(generate_random_seed(1))
img = output.detach().numpy().reshape(28,28)
plt.imshow(img,interpolation='none',cmap='Blues')
#训练GAN------------------------------------------------------------------------
D = Discriminator()
G = Generator()
epochs =4
for epoch in range(epochs):
for label,image_data_tensor,target_tensor in mnist_dataset:
D.train(image_data_tensor,torch.FloatTensor([1.0]))
D.train(G.forward(generate_random_seed(100)).detach(),torch.FloatTensor([0.0]))
G.train(D,generate_random_seed(100),torch.FloatTensor([1.0]))
#生成器经过训练生成的图像
f,axarr = plt.subplots(2,3,figsize=(16,8))
for i in range(2):
for j in range(3):
output = G.forward(generate_random_seed(100))
img = output.detach().numpy().reshape(28,28)
axarr[i,j].imshow(img,interpolation='none',cmap='Blues')
#遇到的问题,generate_random_seed(100),100是生成器输入的大小nn.Sequential
一个序列容器,用于搭建神经网络的模块被按照被传入构造器的顺序添加到nn.Sequential()容器中。
一个包含神经网络模块的OrderedDict也可以被传入nn.Sequential()容器中。
利用nn.Sequential()搭建好模型架构,模型前向传播时调用forward()方法,模型接收的输入首先被传入nn.Sequential()包含的第一个网络模块中。然后,第一个网络模块的输出传入第二个网络模块作为输入,按照顺序依次计算并传播,直到nn.Sequential()里的最后一个模块输出结果。
item()
1,item()取出张量具体位置的元素元素值
2.并且返回的是该位置元素值的高精度值
3.保持原元素类型不变;必须指定位置
4.节省内存(不会计入计算图)
鉴别器训练函数train()
-
获取loss:输入图像和标签,通过infer计算得到预测值,计算损失函数;
-
optimizer.zero_grad() 清空过往梯度;
-
loss.backward() 反向传播,计算当前梯度;
-
optimizer.step() 根据梯度更新网络参数
D.train(generate_real(),torch.FloatTensor([1.0]))
D.train(generate_random()),torch.FloatTensor([0.0]))
符合格式规律的数据是真实的,目标输出为1.0
随机生成的数据是伪造的,目标输出为0.0
生成器训练函数train()
首先,self.forward(inputs)将输入值inputs传递给生成器自身的神经网络。
接着,通过D.forward(g_output)将生成器网络的输出g_ouput传递给鉴别器的神经网络,并输出分类结果 d_output。
鉴别器损失值由这个d_output和训练目标targets变量计算得出。
误差梯度的反向传播由这个损失值触发,在计算图中经过鉴别器回到生成器。
更新由self.optimiser而不是D.optimiser触发。这样一来,只有生成器的链接权重得到更新,这正是GAN训练循环第3步的目的
rand和randn
-
numpy.random.rand(d0, d1, …, dn)的随机样本位于[0, 1)中:本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。
-
numpy.random.randn(d0, d1, …, dn)是从标准正态分布中返回一个或多个样随机样本值。
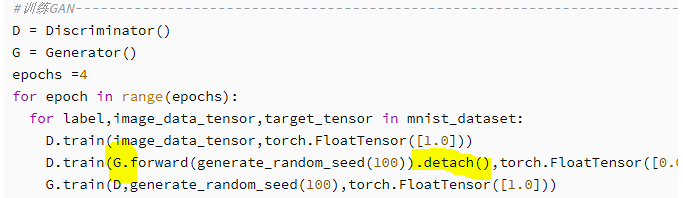
detach()将输出张量从计算图中分离出来,避免计算生成器中的梯度,减少计算量开销
学习要点|《pytorch生成式对抗网络编程》
















 292
292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









