







基于熵最小化的半监督学习
一、论文贡献
该文章提出了一种适用于任何概率分类器的估计原则,旨在使未标记数据在有益的情况下得到充分利用,同时对它们的贡献进行控制,从而为学习方案提供鲁棒性。
二、判据的推导
【semi-supervised-learning-by-entropy-minimization论文主要公式解读】 https://www.bilibili.com/video/BV1Eg4y1b7vH/?share_source=copy_web&vd_source=65c4019397e52f04c18a84bc888b0f35
最重要的公式
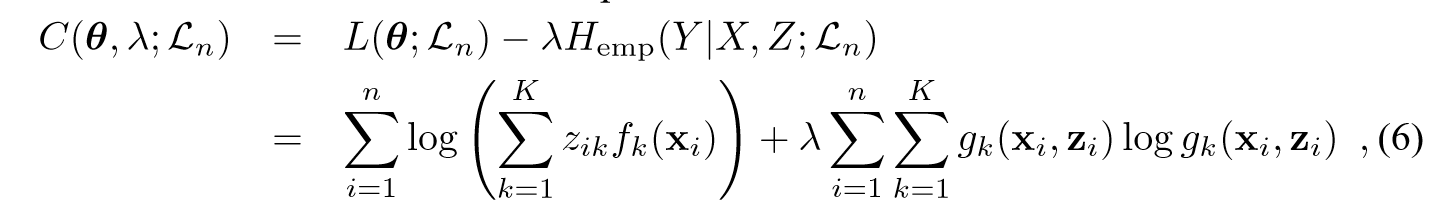
-
L似然函数
-
λH正则化项
-
$H_{emp}$ ( 5 )是H(3)的一个简化,对数据点(式中: P ( X)之间发生突变的wiggly函数fk ( · )分解为下界)。为了加强两个泛函的封闭性,在实验部分,后加一个惩罚项及其对应的Lagrange乘子ν,对fk ( · )施加一个光滑性约束。
三.相关工作
-
自训练
-
最小熵方法
-
输入依赖正则化
四.实验
4.1人工数据
-
目标:检验监督学习在多大程度上可以通过无标签样本进行改进,以及最小熵是否可以与该框架中通常提倡的生成式模型竞争。
-
方法:
-
将最小熵正则项应用到Logistic回归模型中,将其与最大似然拟合的逻辑回归和已知所有标签的逻辑回归进行比较
-
前者显示了通过处理未标记数据而获得的结果,后者提供了通过正确猜测所有标签而获得的"水晶球"性能。
-
-
还将最小熵逻辑回归与高斯混合模型(在有标记和无标记样本上通过最大似然估计的两个均值和一个共同的协方差矩阵,参见e . g . )的经典EM算法进行了比较。
-
当真实分布为高斯混合时,使用真实分布的参数初始化EM,或者当分布偏离模型时,在(完全标记的)测试样本上使用极大似然参数初始化EM,可以避免似然函数出现坏的局部极大值。
-
这样的初始化有利于EM,因为它可以保证在所有的似然局部极大值中挑选出处于最优值吸引域中的那个。
-
此外,这种初始化防止了在第一个E步中给出未标记样本的"伪标注"可能导致的干扰。
-
特别地,在此阶段避免了"标签切换" (即标记不良的簇)。
-
-
正确的联合密度模型
-
实验设置:
-
在第一组实验中,考虑50维输入空间中的两类问题。每个类由一个正态分布以等概率生成。
-
ω 1类均值为( aa ... a),协方差矩阵为单位阵的正态类。
-
ω 2类是均值为- ( aa ... a)且协方差矩阵为单位阵的正态类
-
参数a调节Bayes误差,其变化范围为1 % ~ 20 % ( 1 %、2.5 %、5 %、10 %、20 %)。
-
学习集包括nl个已标记样本,( nl = 50,100,200)和nu个未标记样本,( nu = nl × ( 1,3,10,30,100 )) )。总共评估了75个不同的设置,每个设置生成10个不同的训练样本。在规模为10 000的测试集上估计泛化性能。
-
-
该benchmark为已知无标签数据传递信息的情况下的算法提供了比较。除了EM算法对最优参数的良好初始化外,EM还得益于模型的正确性:数据是根据模型生成的,即具有相同协方差的两个高斯子种群。逻辑回归模型只适用于联合分布,这是比正确性更弱的实现。
-
实验结果:由于不存在建模偏差,错误率的差异仅源于估计效率的差异。总体错误率(在所有设置下取平均值)优于最小熵逻辑回归( 14.1 ± 0.3 %)。EM ( 15.6 ± 0.3 %)比逻辑回归( 14.9 ± 0.3 %)平均表现更差。作为参考,在所有样本都标注的情况下,贝叶斯平均错误率为7.7 %,逻辑回归达到10.4 ± 0.1 %。
-
-
图1:左:试验误差vs . Bayes误差率为nu / nl = 10;右:5 % Bayes误差( a = 0 . 23)的试验误差与nu / nl的比值。最小熵逻辑回归( o )和混合模型( + )的检验误差。逻辑回归( 虚线)和已知所有标签的逻辑回归( 点-线 )的错误被展示,以供参考。
-
-
图1提供了比这些原始数字更多的信息摘要。图中分别表示(平均nl)与Bayes错误率和nu / nl的比值。第一个图表明,正如渐近理论[ 4、9 ]所指出的那样,当Bayes误差较低时,未标记样本是主要的信息。这一观察验证了最小熵假设的相关性。该图也说明了生成模型参数化要求高的后果。当样本量较低时,混合模型的表现优于简单逻辑回归模型,因为它们的参数个数随输入特征的个数呈二次( vs .线性)增长
-
从第2个图可以看出,最小熵模型在类间分离较好的情况下,可以较快地利用未标记数据。当nu = 3nl时,该模型在丢弃未标记数据的基础上有了很大的改进。在这个阶段,生成式模型的表现并不好,因为可用的例子数量与模型中的参数数量相比是很低的。然而,对于非常大的样本量,用100倍的样本进行分析。与标注样本相比,生成式方法最终变得比诊断方法更准确。
关节密度模型设定有误
-
实验设置:在第二个系列的实验中,通过让类条件密度被离群点破坏,对设置进行了轻微的修改。对于每一类,样本由以相同均值为中心的两个高斯混合生成:一个单位方差分量聚集了98 %的样本,其余2 %的样本由一个大的方差分量生成,其中每个变量的标准差为10。EM所使用的混合模型由于是简单的高斯混合,因此存在一定的误设。
-
-
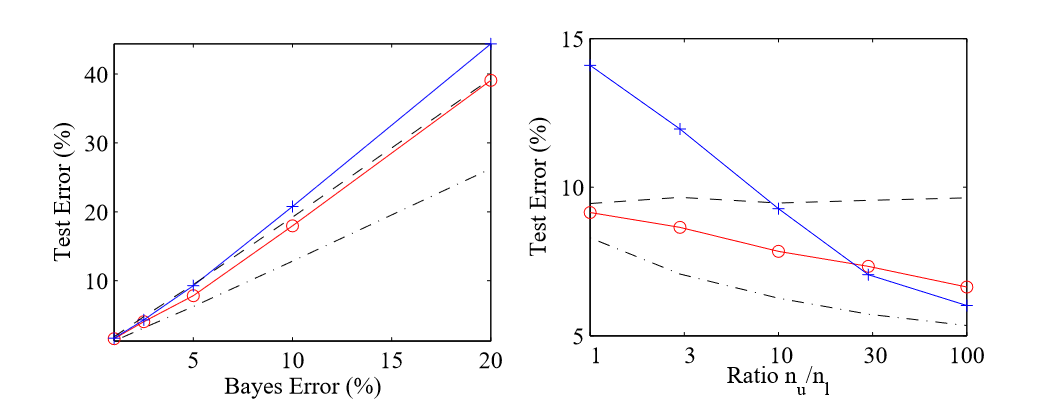
图2:当α = 0.23时,测试误差与nu / nl的比值。最小熵逻辑回归( o)和混合模型( + )的平均测试误差。图中给出了逻辑回归(虚线)和已知所有标签的逻辑回归(点-虚线)的检验误差率以供参考。左:用异常值进行实验;右:用无信息的未标记数据进行实验。
-
-
实验结果:图2的左边显示的结果应与图1的右边进行比较。生成模型显著地受到误设的影响,并且在所有样本量下的表现都比逻辑回归差。未标记样本首先对测试误差产生有利影响,然后在超过标记样本数量时产生不利影响。另一方面,诊断模型表现出与前一种情况一样的平滑性,最小熵准则性能得到改善。
-
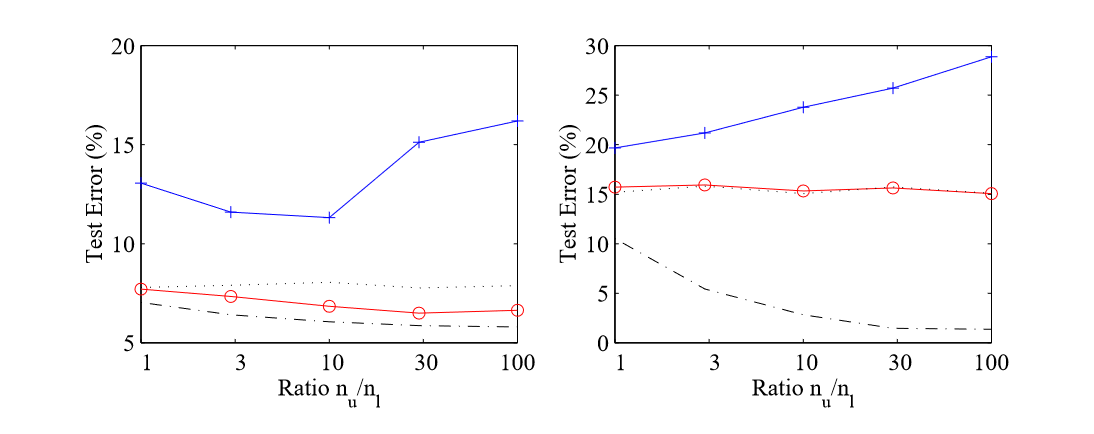
最后的一系列实验说明了聚类假设的鲁棒性,通过在未标记样本不具有信息的分布上进行测试,在低密度P ( X )不表示边界区域的分布上进行测试。数据来自两个高斯聚类,如同第一组实验,但标签现在独立于聚类:一个例子x属于ω 1类,如果x2 > x1,则属于ω 2类,否则属于ω 2类:贝叶斯决策边界现在是将中间的每个聚类分离出来。混合模型不变。现在离用于生成数据的模型相距甚远。
-
图1的右边图表明EM良好的初始化并不妨碍模型被未标记数据所迷惑:它的测试误差随着未标记数据量的增加而稳步增加。另一方面,诊断模型表现良好,最小熵算法不受两个聚类的干扰;它的性能几乎与只有(交叉验证提供了接近零的λ值)标记数据的训练性能相同,这可以看作是在这种情况下的最终性能。
与流形转导的比较
-
实验设置:本文也提供了与"流形族"转导算法的比较。选择了Zhou等人的一致性方法,因为它的简单性。取α = 0.99,尺度参数σ 2在试验结果的基础上进行了优化。结果见表1。

-
表1:最小熵( ME )和一致性方法( CM )的错误率( % )
对于a = 0.23,nl = 50
-
纯高斯簇
-
高斯簇被离群点破坏
-
类边界分离一个高斯簇
-
-
实验结果:一致性方法的结果是极差的,其误差远远高于最小熵,并且随着未标记数据样本的增长没有任何改善的迹象。
-
此外,当类与簇不对应时,一致性方法执行随机类分配。
-
作者说,此设置是为了全局分类器的比较而设计的,对于流形方法来说是非常不利的,因为数据是真正的50维。在这种情况下,局部方法受到"维数灾难"的影响,需要更多的未标记样本才能得到合理的结果。因此对于真正的高维数据,流形学习并不是半监督学习的最佳选择。
-
4.2人脸表情识别
-
图像识别问题实验:即识别与普遍情绪(愤怒、恐惧、厌恶、高兴、悲伤、惊讶和中性)相对应的7个(平衡)类别。模式是正面人脸的灰度图像,具有标准化的位置。该数据集包含140 × 100像素的375张此类图片。
-
具体方法:测试了核化逻辑回归(高斯核),它的最小熵版本,最近邻和一致性方法。重复( 10次)采样数据集的1 / 10以提供标记部分,其余部分用于测试。
-
实验结果:虽然选择( α , σ2)来最小化测试误差,但一致性方法表现不佳,测试误差(与随机分配的86 %误差相比)为63.8 ± 1.3 %。最近邻得到相似的结果,测试误差为63.1 ± 1.3 %,而核化的逻辑回归(忽略未标记样本)提高到53.6 ± 1.3 %。最小熵核化逻辑回归达到了52.0 ± 1.9 %的误差(相比之下,在这个数据库上,人为的误差大约为20 %)。
-
再次,局部方法失败。这可能是由于数据库中包含了每个人的几张图片,具有不同的面部表情。因此,局部方法可能会选择相同的身份而不是相同的表达,而全局方法能够学习相关的方向。
-
五.讨论
-
本文提出使用最小熵正则项来解决监督学习框架中的半监督学习问题。这个正则化器是受理论启发的:在类重叠度较小的情况下,未标记的样本大多是有益的。MAP框架提供了一种手段来控制未标记样本的权重,从而在未标记数据倾向于损害分类时偏离乐观。
-
本文的建议包含了自学习作为一种特殊情况,因为最小化熵增加了分类器输出的置信度。它还在另一种极限情况下逼近直推式大间隔分类器的解,因为最小化熵是一种从学习样本中驱动决策边界的方法。
-
最小熵正则化器既可以应用于局部分类器也可以应用于全局分类器。因此,当数据的维数有效地高时,即当数据不在低维流形上时,它可以改善流形学习。
-
此外,实验表明,最小熵正则化可能是生成式模型的一个严重的竞争者。它在三种情况下与这些混合模型进行了比较:对于小样本容量,生成模型不能完全受益于正确的联合模型的知识;当联合分布被(甚至略微)误设时;当未标记样本在类别概率上表现为无信息时。

















 1475
1475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









