






半监督学习:
2017-Mean-Teacher NIPS
半监督学习Mean teachers
知识补充:
聚类是一种无监督学习任务,其目标是将数据集中的样本划分为相似的组别,每个组别被称为一个簇(cluster)。聚类模型试图通过学习数据之间的相似性或距离来发现数据的内在结构,使得同一簇内的样本彼此更为相似,而不同簇之间的样本差异更大。
在机器学习的上下文中,特别是在分类问题中,我们通常是在考虑模型的输出概率分布。熵的概念可以被用来描述模型对于某个样本的预测的不确定性。你的理解是正确的,当模型的预测概率分布趋向于均匀分布时,熵取得最大值。而在极端情况下,如果模型输出了确定性的预测,即某一类的概率为1,其余类的概率为0,那么熵为0。
MixMatch:
熵最小化
半监督算法的一个常见假设就是分类的决策边界不应该通过数据分布的高密度区域。这句话简单的理解可以想象一个聚类模型,其决策边界一定是在簇与簇之间的稀疏边界上,不可能穿过一个簇的中心(高密度区域)。而实现这一点的一种方法就是要求分类器对未标记数据输出低熵预测。MixMatch中使用一个"sharpening"函数来隐式实现熵最小化。所谓熵最小化、低熵预测,都是指使输出概率分布比较有“偏向性”,而不希望输出一个“平均的预测”。熵在信息论中是不确定度的度量,根据离散模型的熵最大定理,可知在均匀分布时熵取得最大值,换句话说,出现一个确定的分布,即某一类的概率是1,其余类的概率是0时,熵为0。也就是说想要得到熵最小,就得使分类器输出后的模型预测概率集中分配给某一类。后面再介绍“sharpening”函数如何实现这一点。
一致性正则化
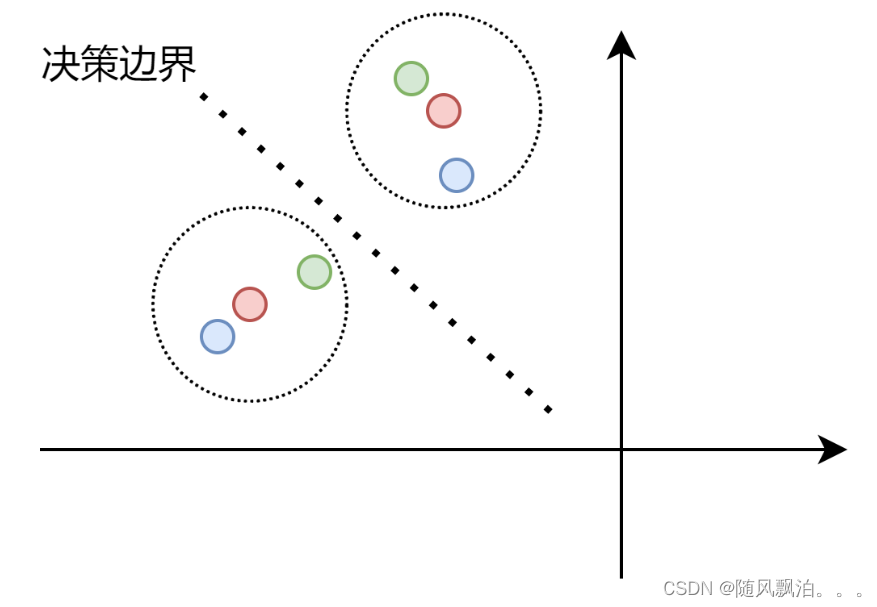
一致性正则化也是一个常见的半监督假设。VAT、MeanTeacher等其实都或多或少使用了这种假设。其核心在于,**我们希望一个样本和其加扰版本(通常图像中称为Augment)通过分类器后,得到相似的输出。**其实也就是说分类边界不应该穿过数据分布的高密度区域。如下图,红色点是原始样本,蓝色和绿色为其扰动版本,红色同心圆的虚线圆是我们期望的容差范围,即在这个区间类的都应该认为和其中心数据点为同一类。通过扰动数据点的加入,将决策边界推到合适的位置,使分类器的鲁棒性更强。
Fixmatch:
FIxmatch
FixMatch 知乎















 3303
3303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









