







- 例如,采用一个固定的比例来选择每个决策树的特征空间大小。
- 随机森林中的每棵树的建立都比一个单独的决策树要简单和快速;但是这种方法增加了模型的 。
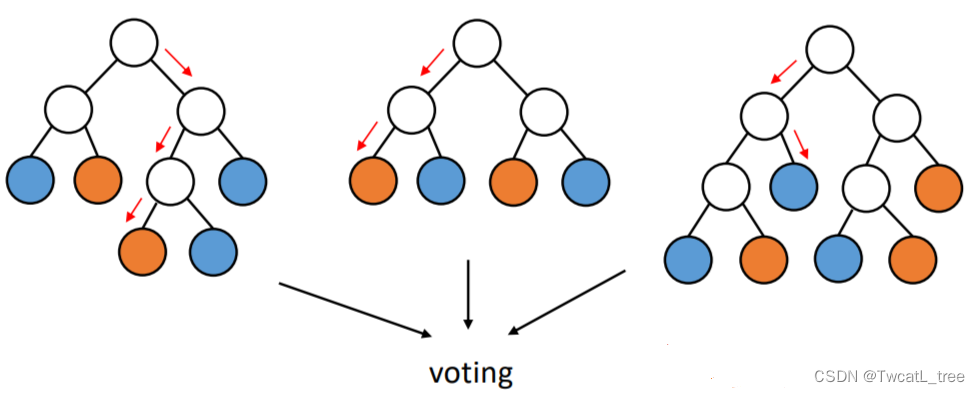
森林就是多个随机树的集合
- 每棵树都是用不同的袋装训练数据集建立的。
- 综合分类是通过投票进行的。
随机森林的超参数:
树的数量B,可以根据“out-of-bag”误差进行调整。
特征子样本大小:随着它的增加,分类器的强度和相关性都增加
(
⌊
l
o
g
2
∣
F
∣
1
⌋
)
\left ( \left \lfloor log_{2}\left | F \right | + 1 \right \rfloor \right )
(⌊log2∣F∣+1⌋)。因为随机森林中的每棵树使用的特征越多,其与森林中其他树的特征重合度就可能越高,导致产生的随机数相似度越大。
可解释性:单个实例预测背后的逻辑可以通过多棵随机树共同决定。
随机森林的特点:
- 随机森林非常强大,可以高效地进行构建。
- 可以并行的进行。
- 对过拟合有很强的鲁棒性。
- 可解释性被牺牲了一部分,因为每个树的特征都是特征集合中随机选取的一部分。
5.3 演进法 Boosting(算法操作)
演进法的思想源于调整基础分类器,使其专注于难以分类的实例的直觉判断。
具体方法:
迭代地改变训练实例的分布和权重,以反映分类器在前一次迭代中的表现。
- 从初始训练集训练出一个基学习器;这时候每个样本的权重都为。
- 每个都会根据上一轮预测结果调整训练集样本的权重。
- 基于调整后的训练集训练一个新的基学习器。
- 重复进行,直到基学习器数量达到开始设置的值。
- 将个基学习器通过加权的投票方法(weighted voting)进行结合。
例子:

对于boosting方法,有两个问题需要解决:
- 每一轮学习应该如何改变数据的概率分布
- 如何将各个基分类器组合起来
Boosting集成方法的特点:
- 他的基分类器是决策树或者 OneR 方法。
- 数学过程复杂,但是计算的开销较小;整个过程建立在迭代的采样过程和加权的投票(voting)上。
- 通过迭代的方式不断的拟合残差信息,最终保证模型的精度。
- 比bagging方法的计算开销要大一些。
- 在实际的应用中,boosting的方法略有过拟合的倾向(但是不严重)。
- 可能是最佳的词分类器(gradient boosting)。
5.3.1 演进法实例:AdaBoost
Adaptive Boosting(自适应增强算法):是一种顺序的集成方法(随机森林和 Bagging 都属于并行的集成算法)。
具体方法:
有T个基分类器:
C
1
,
C
2
,
.
.
.
,
C
i
,
.
.
,
C
T
C_{1},C_{2},…,C_{i},…,C_{T}
C1,C2,…,Ci,…,CT。
训练集表示为
{
x
i
,
y
j
∣
j
=
1
,
2
,
.
.
.
,
N
}
\left { x_{i},y_{j}|j=1,2,…,N \right }
{xi,yj∣j=1,2,…,N}。
初始化每个样本的权重都为
1
N
\frac{1}{N}
N1,即:
{
w
j
(
1
)
=
1
N
∣
j
=
1
,
2
,
.
.
.
,
N
}
\left { w_{j}^{(1)=\frac{1}{N}}|j=1,2,…,N \right }
{wj(1)=N1∣j=1,2,…,N}。
在每个iteration i 中,都按照下面的步骤进行:
计算错误率 error rate
ξ
i
=
∑
j
=
1
N
w
j
(
i
)
δ
(
C
j
(
x
j
)
≠
y
j
)
\xi _{i}=\sum _{j=1}^{N} w_{j}^{(i)}\delta (C_{j}(x_{j})\neq y_{j})
ξi=∑j=1Nwj(i)δ(Cj(xj)=yj)
δ
(
)
\delta \left ( \right)
δ()是一个indicator函数,当函数的条件满足的时候函数值为1;即,当弱分类器
C
i
C_{i}
Ci对样本
x
j
x_{j}
xj进行分类的时候如果分错了就会累积
w
j
w_{j}
wj。
使用
ξ
i
\xi _{i}
ξi来计算每个基分类器
C
i
C_{i}
Ci的重要程度(给这个基分类器分配权重
α
i
\alpha _{i}
αi)
α
i
=
1
2
l
n
1
−
ε
i
ε
i
\alpha _{i}=\frac{1}{2}ln\frac{1-\varepsilon _{i}}{\varepsilon _{i}}
αi=21lnεi1−εi
从这个公式也能看出来,当
C
i
C_{i}
Ci 判断错的样本量越多,得到的
ξ
i
\xi _{i}
ξi就越大,相应的
α
i
\alpha _{i}
αi就越小(越接近0)
根据
α
i
\alpha _{i}
αi来更新每一个样本的权重参数,为了第i+1个iteration做准备:
w
j
(
i
1
)
=
w
j
(
i
)
Z
(
i
)
×
{
e
−
α
i
i
f
C
i
(
x
j
)
=
y
j
e
α
i
i
f
C
i
(
x
j
)
≠
y
j
w_{j}{(i+1)}=\frac{w_{j}{(i)}}{Z^{(i)}}\times \left{\begin{matrix} e^{-\alpha _{i}} &ifC_{i}(x_{j})=y_{j} \ e^{\alpha _{i}} & ifC_{i}(x_{j})\neq y_{j} \end{matrix}\right.
wj(i+1)=Z(i)wj(i)×{e−αieαiifCi(xj)=yjifCi(xj)=yj
样本j的权重由
w
j
(
i
)
w_{j}^{(i)}
wj(i)变成
w
j
(
i
1
)
w_{j}^{(i+1)}
wj(i+1)这个过程中发生的事情是:如果这个样本在第i个iteration中被判断正确了,他的权重就会在原本KaTeX parse error: Expected ‘}’, got ‘EOF’ at end of input: w_{j}^{(i)}的基础上乘以
e
−
α
i
e^{-\alpha _{i}}
e−αi;根据上面的知识
α
i
0
\alpha _{i} > 0
αi>0因此
−
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6418
6418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









