







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

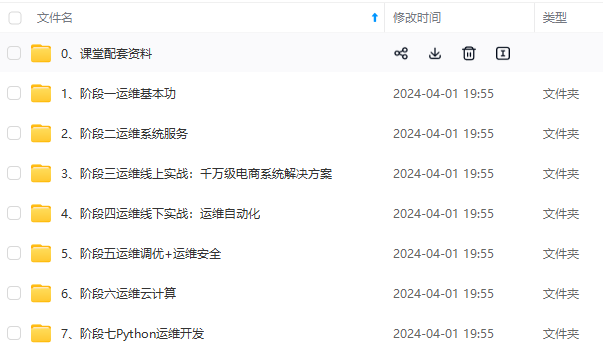
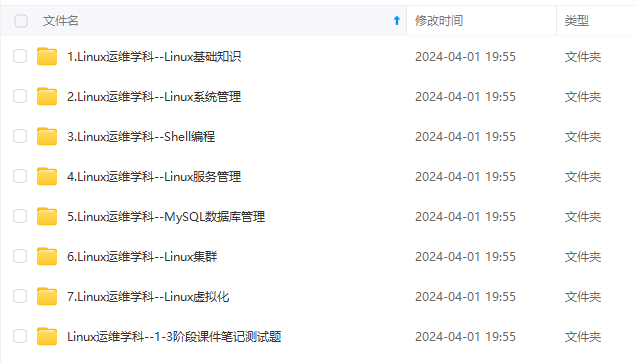
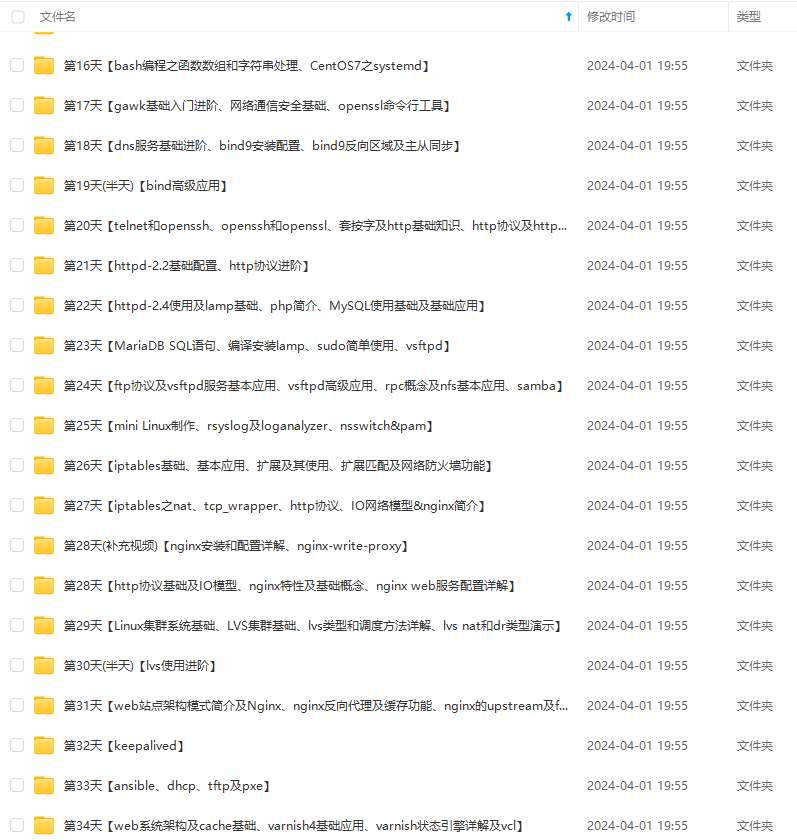
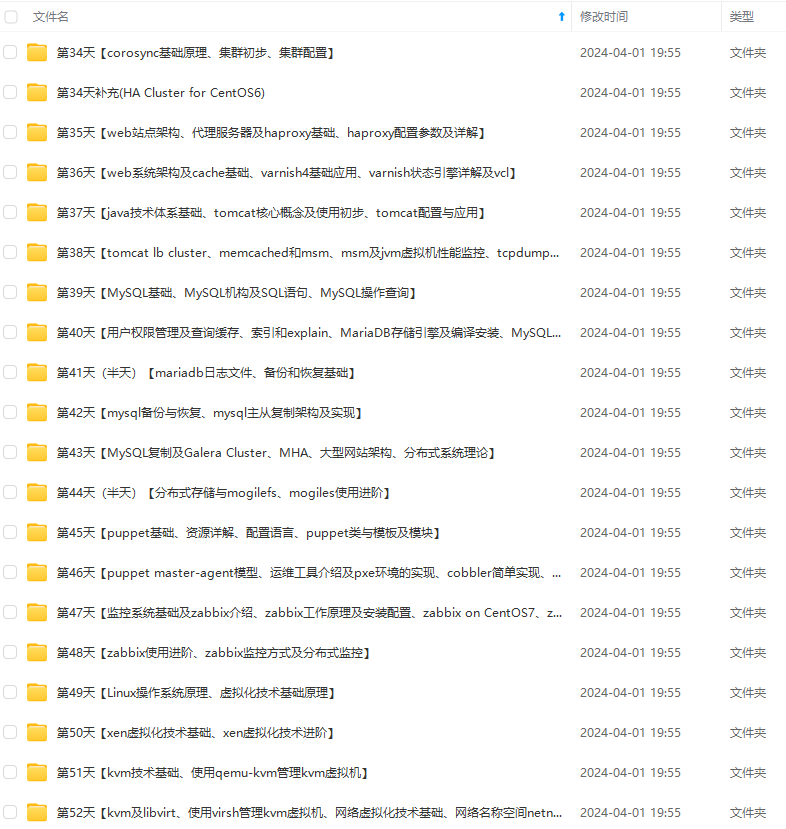
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
输出文档还可以包含计算字段,该字段保存由$group的_id字段分组的一些accumulator表达式的值。 $group不会输出具体的文档而只是统计信息。
语法
{ $group: { \_id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... } }
_id字段是必填的;但是,可以指定_id值为null来为整个输入文档计算累计值。- 剩余的计算字段是可选的,并使用
<accumulator>运算符进行计算。 _id和<accumulator>表达式可以接受任何有效的表达式。
accumulator操作符
| 名称 | 描述 | 类比sql |
|---|---|---|
| $avg | 计算均值 | avg |
| $first | 返回每组第一个文档,如果有排序,按照排序,如果没有按照默认的存储的顺序返回第一个文档。 | limit 0,1 |
| $last | 返回每组最后一个文档,如果有排序,按照排序,如果没有按照默认的存储的顺序返回最后一个文档。 | - |
| $max | 根据分组,获取集合中所有文档对应值的最大值。 | max |
| $min | 根据分组,获取集合中所有文档对应值的最小值。 | min |
| $push | 将指定的表达式的值添加到一个数组中。 | - |
| $addToSet | 将表达式的值添加到一个集合中(无重复值,无序)。 | - |
| $sum | 计算总和 | sum |
| $stdDevPop | 返回输入值的总体标准偏差(population standard deviation) | - |
| $stdDevSamp | 返回输入值的样本标准偏差(the sample standard deviation) | - |
g
r
o
u
p
阶段的内存限制为
100
M
,默认情况下,如果
s
t
a
g
e
超过此限制,
group阶段的内存限制为100M,默认情况下,如果stage超过此限制,
group阶段的内存限制为100M,默认情况下,如果stage超过此限制,group将产生错误,但是,要允许处理大型数据集,请将allowDiskUse选项设置为true以启用$group操作以写入临时文件。
注意:
- “$addToSet”:expr,如果当前数组中不包含expr,那就将它添加到数组中。
- “$push”:expr,不管expr是什么值,都将它添加到数组中,返回包含所有值的数组。
示例
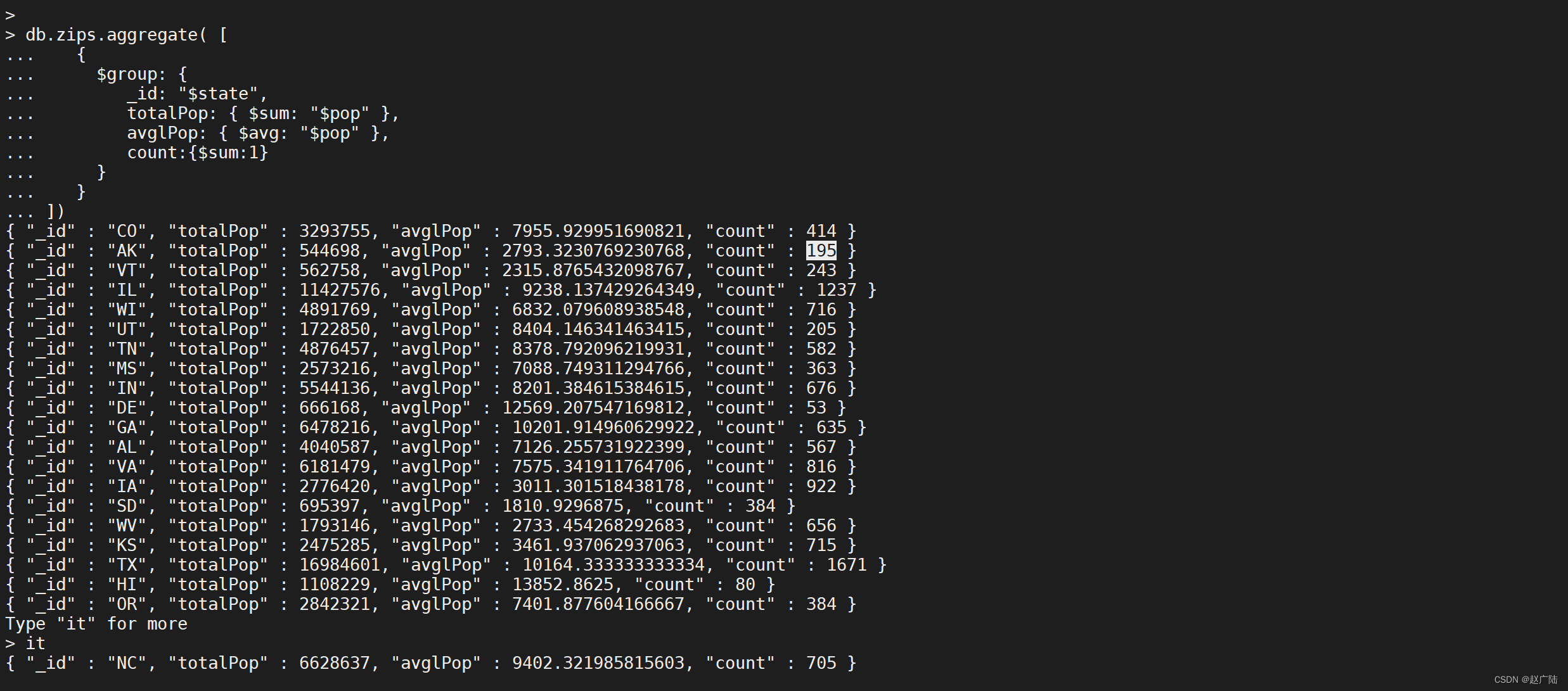
按照
state分组,并计算每一个state分组的总人数,平均人数以及每个分组的数量
db.zips.aggregate([
{
"$group": {
"\_id": "$state",
"totalPop": {
"$sum": "$pop"
},
"avglPop": {
"$avg": "$pop"
},
"count": {
"$sum": 1
}
}
}
])
查找不重复的所有的
state的值
db.zips.aggregate([
{
"$group": {
"\_id": "$state"
}
}
])

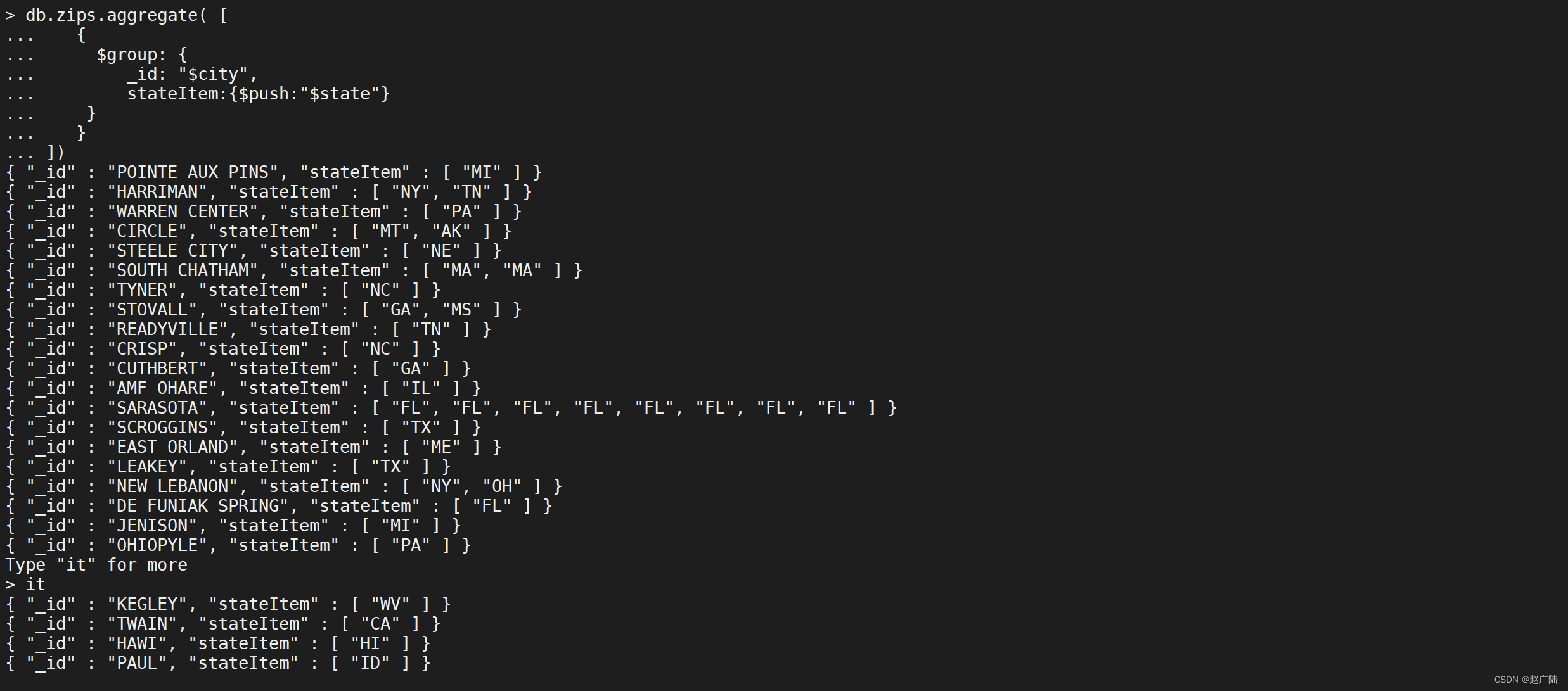
按照
city分组,并且分组内的state字段列表加入到stateItem并显示
db.zips.aggregate([
{
"$group": {
"\_id": "$city",
"stateItem": {
"$push": "$state"
}
}
}
])
下面聚合操作使用系统变量$$ROOT按item对文档进行分组,生成的文档不得超过BSON文档大小限制
db.zips.aggregate([
{
"$group": {
"\_id": "$city",
"item": {
"$push": "$$ROOT"
}
}
}
]).pretty();

$match
过滤文档,仅将符合指定条件的文档传递到下一个管道阶段。
$match接受一个指定查询条件的文档,查询语法与读操作查询语法相同。
语法
{ $match: { <query> } }
管道优化
$match用于对文档进行筛选,之后可以在得到的文档子集上做聚合,$match可以使用除了地理空间之外的所有常规查询操作符,**在实际应用中尽可能将$match放在管道的前面位置**。这样有两个好处:
- 一是可以快速将不需要的文档过滤掉,以减少管道的工作量;
- 二是如果再投射和分组之前执行$match,查询可以使用索引。
使用限制
- 不能在
$match查询中使用$作为聚合管道的一部分。 - 要在
$match阶段使用$text,$match阶段必须是管道的第一阶段。 - 视图不支持文本搜索。
示例
使用 $match做简单的匹配查询,查询缩写是
NY的城市数据
db.zips.aggregate([
{
"$match": {
"state": "NY"
}
}
]).pretty();

使用
m
a
t
c
h
管道选择要处理的文档,然后将结果输出到
match管道选择要处理的文档,然后将结果输出到
match管道选择要处理的文档,然后将结果输出到group管道以计算文档的计数
db.zips.aggregate([
{
"$match": {
"state": "NY"
}
},
{
"$group": {
"\_id": null,
"sum": {
"$sum": "$pop"
},
"avg": {
"$avg": "$pop"
},
"count": {
"$sum": 1
}
}
}
]).pretty();

$unwind
从输入文档解构数组字段以输出每个元素的文档,简单说就是 可以将数组拆分为单独的文档。
语法
要指定字段路径,在字段名称前加上$符并用引号括起来。
{ $unwind: <field path> }
v3.2+支持如下语法
{
$unwind:
{
path: <field path>,
#可选,一个新字段的名称用于存放元素的数组索引。该名称不能以$开头。
includeArrayIndex: <string>,
#可选,default :false,若为true,如果路径为空,缺少或为空数组,则$unwind输出文档
preserveNullAndEmptyArrays: <boolean>
}
}
如果为输入文档中不存在的字段指定路径,或者该字段为空数组,则$unwind默认会忽略输入文档,并且不会输出该输入文档的文档。
版本3.2中的新功能:要输出数组字段丢失的文档,null或空数组,请使用选项preserveNullAndEmptyArrays。
示例
以下聚合使用$unwind为loc数组中的每个元素输出一个文档:
db.zips.aggregate([
{
"$match": {
"\_id": "01002"
}
},
{
"$unwind": "$loc"
}
]).pretty();
db.zips.aggregate([
{
"$match": {
"\_id": "01002"
}
},
{
"$unwind": {
"path": "$loc",
"includeArrayIndex": "locIndex",
"preserveNullAndEmptyArrays": true
}
}
]).pretty();

$project
$project可以从文档中选择想要的字段,和不想要的字段(指定的字段可以是来自输入文档或新计算字段的现有字段),也可以通过管道表达式进行一些复杂的操作,例如数学操作,日期操作,字符串操作,逻辑操作。
语法
$project 管道符的作用是选择字段(指定字段,添加字段,不显示字段,_id:0,排除字段等),重命名字段,派生字段。
{ $project: { <specification(s)> } }
specifications有以下形式:
<field>: <1 or true> 是否包含该字段,field:1/0,表示选择/不选择 field
_id: <0 or false> 是否指定_id字段
<field>: <expression> 添加新字段或重置现有字段的值。 在版本3.6中更改:MongoDB 3.6添加变量REMOVE。如果表达式的计算结果为$$REMOVE,则该字段将排除在输出中。
<field>:<0 or false> v3.4新增功能,指定排除字段
- 默认情况下,_id字段包含在输出文档中。要在输出文档中包含输入文档中的任何其他字段,必须明确指定
p
r
o
j
e
c
t
中的包含。如果指定包含文档中不存在的字段,
project中的包含。 如果指定包含文档中不存在的字段,
project中的包含。如果指定包含文档中不存在的字段,project将忽略该字段包含,并且不会将该字段添加到文档中。
- 默认情况下,id字段包含在输出文档中。要从输出文档中排除id字段,必须明确指定$project中的_id字段为0。
- v3.4版新增功能-如果指定排除一个或多个字段,则所有其他字段将在输出文档中返回。 如果指定排除_id以外的字段,则不能使用任何其他$project规范表单:即,如果排除字段,则不能指定包含字段,重置现有字段的值或添加新字段。此限制不适用于使用REMOVE变量条件排除字段。
- v3.6版本中的新功能- 从MongoDB 3.6开始,可以在聚合表达式中使用变量REMOVE来有条件地禁止一个字段。
- 要添加新字段或重置现有字段的值,请指定字段名称并将其值设置为某个表达式。
- 要将字段值直接设置为数字或布尔文本,而不是将字段设置为解析为文字的表达式,请使用
l
i
t
e
r
a
l
操作符。否则,
literal操作符。否则,
literal操作符。否则,project会将数字或布尔文字视为包含或排除该字段的标志。
- 通过指定新字段并将其值设置为现有字段的字段路径,可以有效地重命名字段。
- 从MongoDB 3.2开始,$project阶段支持使用方括号[]直接创建新的数组字段。如果数组规范包含文档中不存在的字段,则该操作会将空值替换为该字段的值。
- 在版本3.4中更改-如果$project 是一个空文档,MongoDB 3.4和更高版本会产生一个错误。
- 投影或添加/重置嵌入文档中的字段时,可以使用点符号
示例
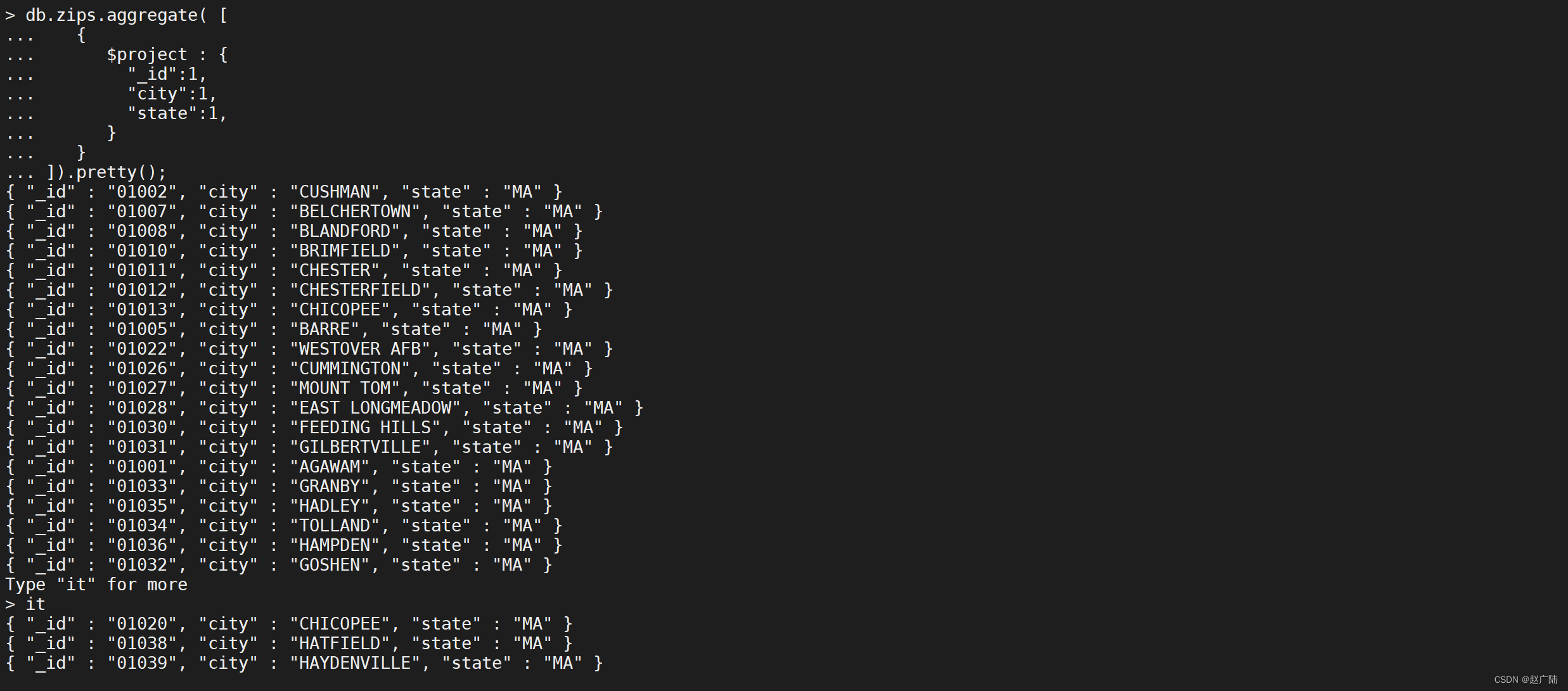
以下$project阶段的输出文档中只包含_id,city和state字段
db.zips.aggregate([
{
"$project": {
"\_id": 1,
"city": 1,
"state": 1
}
}
]).pretty();
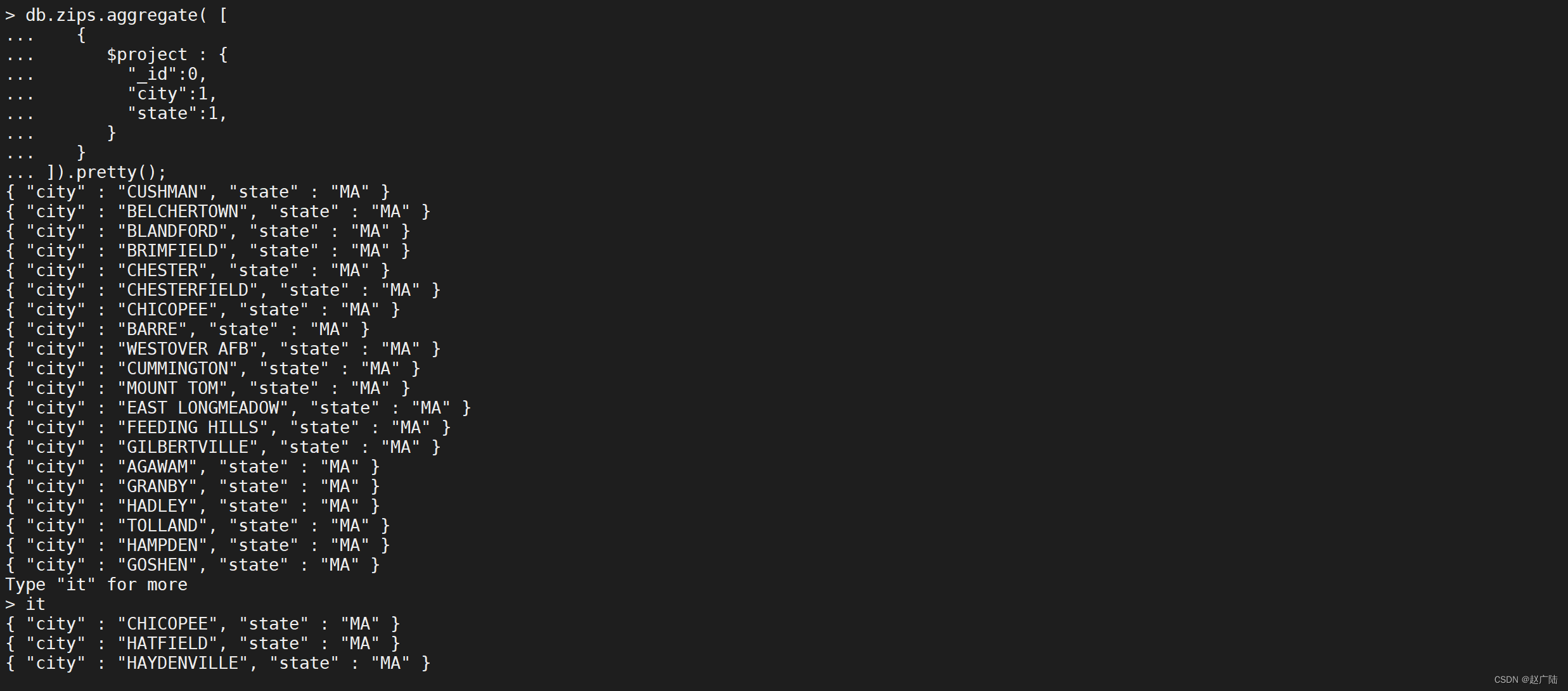
_id字段默认包含在内。要从$ project阶段的输出文档中排除_id字段,请在project文档中将_id字段设置为0来指定排除_id字段。
db.zips.aggregate([
{
"$project": {
"\_id": 0,
"city": 1,
"state": 1
}
}
]).pretty();
以下$ project阶段从输出中排除loc字段
db.zips.aggregate([
{
"$project": {
"loc": 0
}
}
]).pretty();
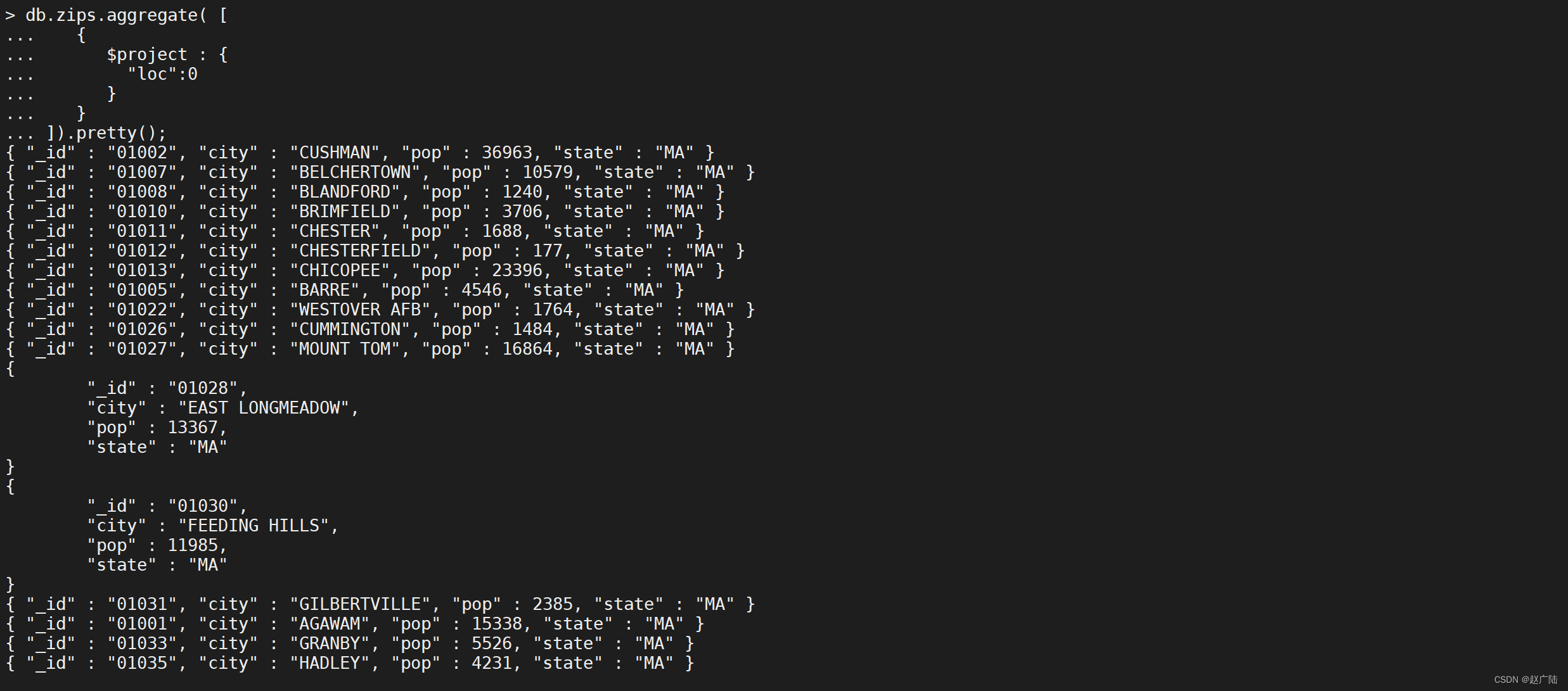
可以在聚合表达式中使用变量REMOVE来有条件地禁止一个字段,
db.zips.aggregate([
{
"$project": {
"\_id": 1,
"city": 1,
"state": 1,
"pop": 1,
"loc": {
"$cond": {
"if": {
"$gt": [
"$pop",
1000
]
},
"then": "$$REMOVE",
"else": "$loc"
}
}
}
}
]).pretty();
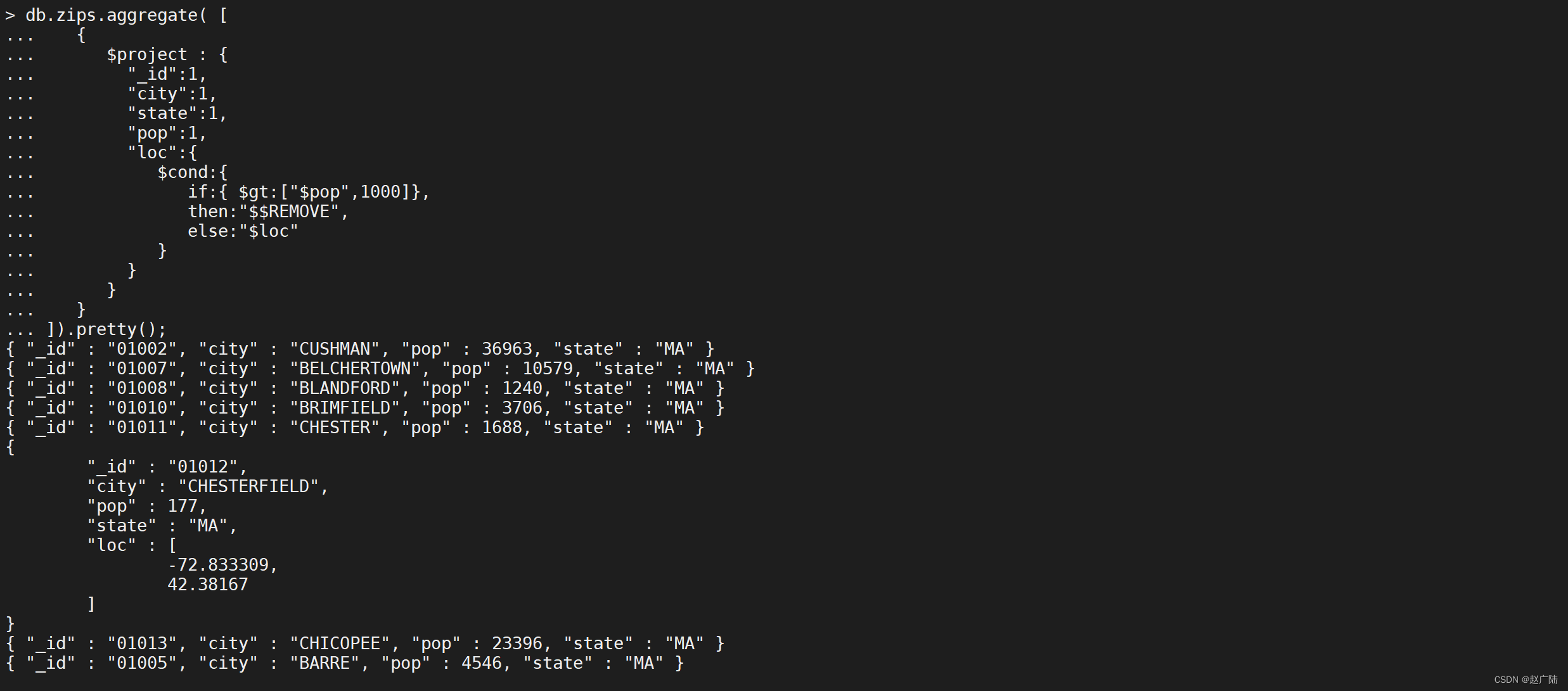
我们还可以改变数据,将人数大于1000的城市坐标重置为0
db.zips.aggregate([
{
"$project": {
"\_id": 1,
"city": 1,
"state": 1,
"pop": 1,
"loc": {
"$cond": {
"if": {
"$gt": [
"$pop",
1000
]
},
"then": [
0,
0
],
"else": "$loc"
}
}
}
}
]).pretty();

新增字段列
db.zips.aggregate([
{
"$project": {
"\_id": 1,
"city": 1,
"state": 1,
"pop": 1,
"desc": {
"$cond": {
"if": {
"$gt": [
"$pop",
1000
]
},
"then": "人数过多",
"else": "人数过少"
}
},
"loc": {
"$cond": {
"if": {
"$gt": [
"$pop",
1000
]
},
"then": [
0,
0
],
"else": "$loc"
}
}
}
}
]).pretty();

$limit
限制传递到管道中下一阶段的文档数
语法
{ $limit: <positive integer> }
示例,此操作仅返回管道传递给它的前5个文档。 $limit对其传递的文档内容没有影响。
db.zips.aggregate({
"$limit": 5
});
注意
当$sort在管道中的$limit之前立即出现时,$sort操作只会在过程中维持前n个结果,其中n是指定的限制,而MongoDB只需要将n个项存储在内存中。当allowDiskUse为true并且n个项目超过聚合内存限制时,此优化仍然适用。
$skip
跳过进入stage的指定数量的文档,并将其余文档传递到管道中的下一个阶段
语法
{ $skip: <positive integer> }
示例,此操作将跳过管道传递给它的前5个文档, $skip对沿着管道传递的文档的内容没有影响。
db.zips.aggregate({
"$skip": 5
});
$sort
对所有输入文档进行排序,并按排序顺序将它们返回到管道。
语法
{ $sort: { <field1>: <sort order>, <field2>: <sort order> ... } }
$sort指定要排序的字段和相应的排序顺序的文档。
<sort order>可以具有以下值之一:
- 1指定升序。
- -1指定降序。
- {$meta:“textScore”}按照降序排列计算出的textScore元数据。
示例
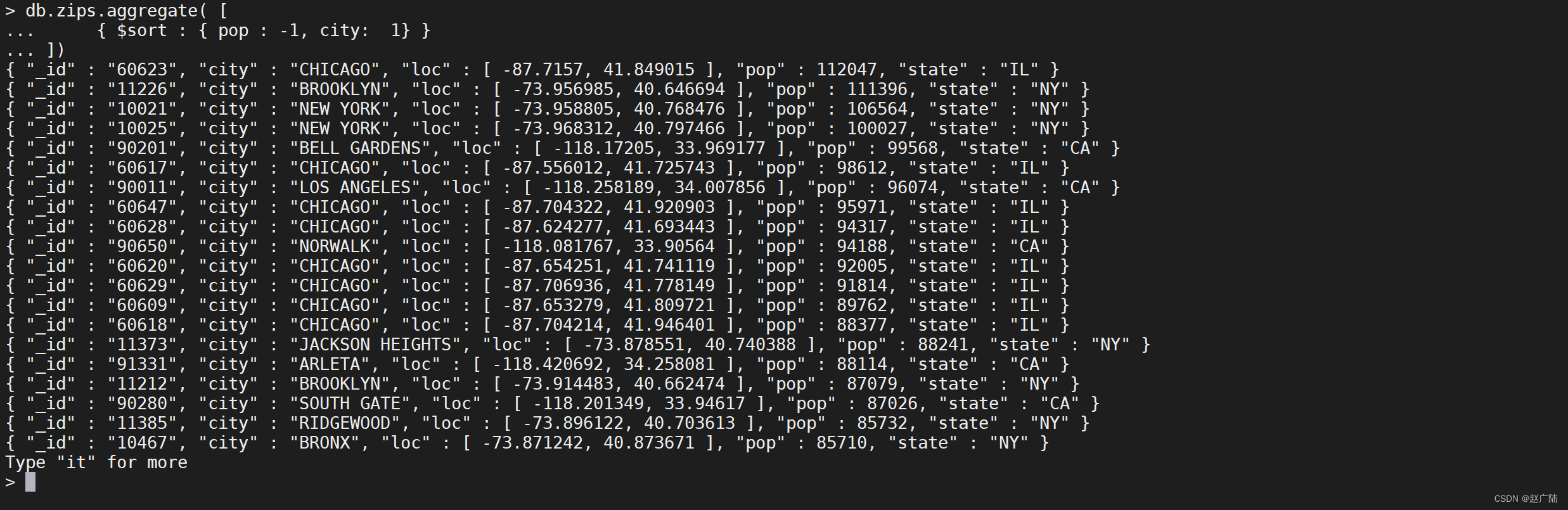
要对字段进行排序,请将排序顺序设置为1或-1,以分别指定升序或降序排序,如下例所示:
db.zips.aggregate([
{
"$sort": {
"pop": -1,
"city": 1
}
}
])
$sortByCount
根据指定表达式的值对传入文档分组,然后计算每个不同组中文档的数量。每个输出文档都包含两个字段:包含不同分组值的_id字段和包含属于该分组或类别的文档数的计数字段,文件按降序排列。
语法
{ $sortByCount: <expression> }
3 使用示例
下面举了一些常用的mongo聚合例子和mysql对比,假设有一条如下的数据库记录(表名:zips)作为例子:
3.1 统计所有数据
SQL的语法格式如下
select count(1) from zips;
mongoDB的语法格式
db.zips.aggregate([
{
"$group": {
"\_id": null,
"count": {
"$sum": 1
}
}
}
])

3.2 对所有城市人数求合
SQL的语法格式如下
select sum(pop) AS tota from zips;
mongoDB的语法格式
db.zips.aggregate([
{
"$group": {
"\_id": null,
"total": {
"$sum": "$pop"
}
}
}
])

3.3 对城市缩写相同的城市人数求合
SQL的语法格式如下
select state,sum(pop) AS tota from zips group by state;
mongoDB的语法格式
db.zips.aggregate([
{
"$group": {
"\_id": "$state",
"total": {
"$sum": "$pop"
}
}
}
])

3.4 state重复的城市个数
SQL的语法格式如下
select state,count(1) AS total from zips group by state;
mongoDB的语法格式
db.zips.aggregate([
{
"$group": {
"\_id": "$state",
"total": {
"$sum": 1
}
}
}
])

3.5 state重复个数大于100的城市
SQL的语法格式如下
最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:

给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
“_id”: “KaTeX parse error: Expected '}', got 'EOF' at end of input: … "sum”: “$pop”
}
}
}
])

### 3.4 state重复的城市个数
>
> SQL的语法格式如下
>
>
>
select state,count(1) AS total from zips group by state;
>
> mongoDB的语法格式
>
>
>
db.zips.aggregate([
{
“KaTeX parse error: Expected '}', got 'EOF' at end of input: … "\_id": "state”,
“total”: {
“$sum”: 1
}
}
}
])

### 3.5 state重复个数大于100的城市
>
> SQL的语法格式如下
### 最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
### 资料预览
给大家整理的视频资料:
[外链图片转存中...(img-ppuMWAXy-1713379110042)]
给大家整理的电子书资料:
[外链图片转存中...(img-S5mZz64Q-1713379110042)]
**如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!**
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)**
[外链图片转存中...(img-duIUvlHF-1713379110042)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1265
1265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









