






目录
前言
这篇博客主要介绍注意力感知的多笔触风格迁移(Attention-aware Multi-stroke Style Transfer )项目的原理以及如何部署运行。该项目的作用是:
给定内容图像和风格图像作为输入,风格迁移模型会自动地将内容图像的风格、纹理特征变换为风格图像的类型,同时保证图像的内容特征不变。
项目链接:AAMS
论文链接:Attention-aware Multi-stroke Style Transfer
快速体验:Modelscope
(本篇博客由@Null700 @xinopiuyt和本人合作完成。水平有限,如有错误,欢迎各位大神批评指正!)
一、环境配置
1. Anaconda环境配置
在Windows环境下用anaconda配置环境并在pycharm上部署运行该项目。如果没有,可参考:Anaconda安装教程(Windows),PyCharm。
首先要新建一个环境:打开anaconda prompt,进入默认是基础环境base,输入conda env list查看电脑中已经存在的环境,这里由于我已经建好了一个环境,所以显示两个:
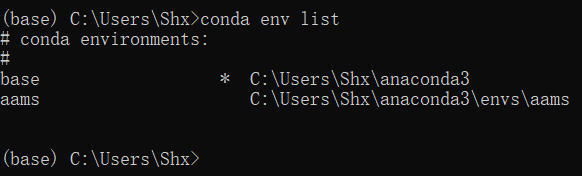
下面新建一个环境来运行该项目,因为该项目是python2.7+tensorflow1.x,和一般用到的配置不同,所以专门建一个环境来跑这个项目是有必要的。下面新建一个名为aams1,python版本为2.7的环境:输入
conda create -n tf python=2.7

接着再输入
conda env list
检查结果:
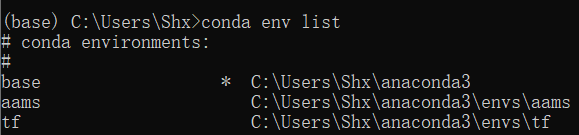
可以看出建立完成。用
conda activate tf
切换到该环境进行进一步的配置:
首先下载tensorflow,由于用的python版本是2.7,所以tensorflow版本不能太高,作者给出的是大于1.4,我们这里选择1.10.0。一般是用pip安装,但是Windows环境下用python2.7去下低版本的tensorflow会很麻烦,直接用pip下不了,所以最后选择直接找到对应版本的tensorflow文件下载到本地再安装,这里安装的事CPU版本的tensorflow,文件下载:link。
下载下来是一个名为“tensorflow-1.10.0-cp27-cp27m-win_amd64.whl”的文件,cd到文件所在的文件夹,然后输入:
pip install tensorflow-1.10.0-cp27-cp27m-win_amd64.whl

不出意外的话会报一大堆错,观察一下报错是因为少了一个叫grpcio的东西。

这里为了防止像安装tensorflow一样四处碰壁,也是直接选择下载文件到本地来安装,link(这个也会有版本问题,具体范围没有去查找,但尽量别用太高的,这里用的是1.39.0)。和上面一样,进入所在文件夹输入:
pip install grpcio-1.39.0-cp27-cp27m-win_amd64.whl
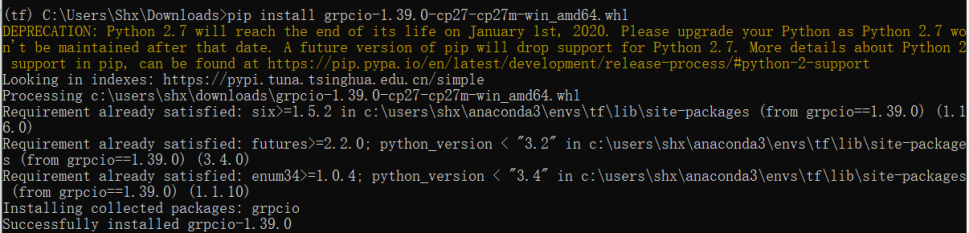
安装完成后再输入
pip install tensorflow-1.10.0-cp27-cp27m-win_amd64.whl
应该就可以成功安装了。下面再安装一些必要的包:
pip install scipy
pip install pillow

pip install opencv-python==4.2.0.32
pip install matplotlib
在运行训练代码时用以上的环境还是会有报错,所以还要额外安装一个包:tensorflow-estimator(要和tensorflow版本匹配)。进入文件所在位置,运行:
pip install tensorflow-estimator==1.10.6
到这里环境配置就结束了,接下来是在PyCharm中接入这个环境。
2. PyCharm环境配置
用PyCharm打开项目,按ctrl+alt+s打开设置界面,在设置界面中找到python interpreter选项,然后点击add interpreter–add local interpreter进入添加界面。在添加界面选择conda environment,然后在interpreter那一栏选择新添加的python环境,再点击确认就添加成功了。
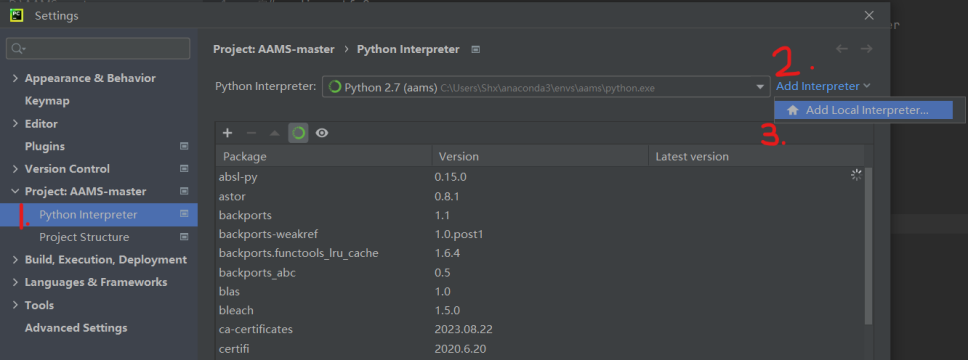
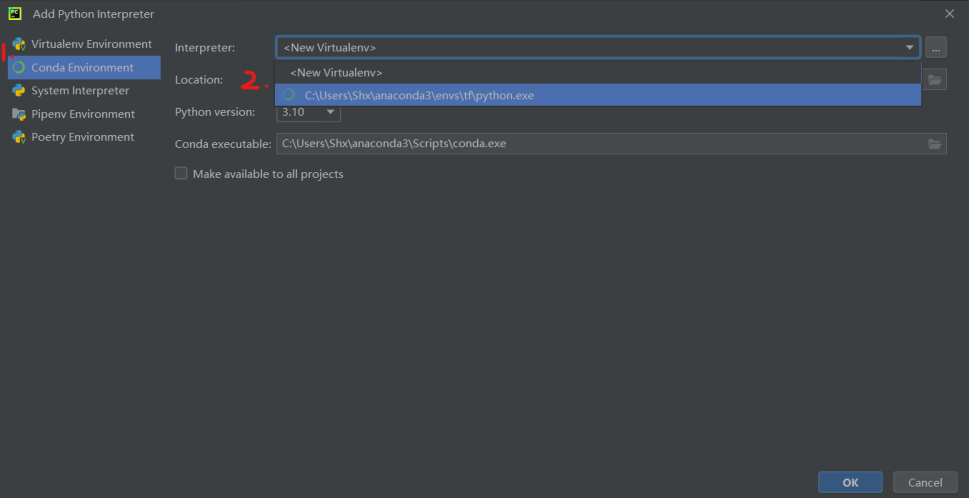
最后再把interpreter切换成新添加的就用上我们新添加的环境了。
(长文预警:下面将对图像的风格转换进行原理讲解,内容较多,想接着运行项目可跳到第三部分)
二、原理讲解
1. 预备知识
(1)VGG卷积神经网络模型:图像特征的提取
论文:《Very Deep Convolutional Networks for Large-Scale Image Recognition》(用于大规模图像识别的甚深卷积网络)
VGG全称Visual Geometry Group,即牛津大学视觉几何组,其发布了一系列以VGG命名的预训练好的卷积神经网络模型。
本项目(AAMS)采用了Oxford Net VGG 19-Layers version E Example图像分类模型来提取特征,以及根据提取的特征重建图像。
VGG19模型是VGGNet系列模型之一,由于该模型包含了16次卷积操作(分在5个卷积层中)和3个全连接层,因此被称为VGG19。
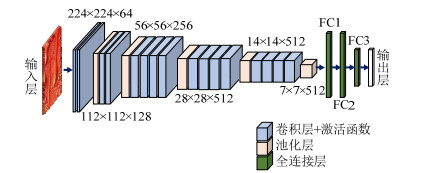
相较于其他卷积神经网络模型,VGG19具有如下的特点:
① 输入该模型的图像大小限制为224*224*3,即长宽224像素值,通道数为3。当图像的尺寸大于该尺寸限制时,需要对图像进行裁剪。
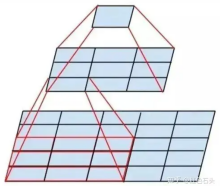
② 卷积层统一使用3×3大小的卷积核。在进行卷积操作前,对图像的边缘进行填充,这样,在卷积操作执行完后,图像的尺寸不会发生变化。同时,每次进行卷积操作之后,都使用激活函数ReLU进行激活,增加非线性,从而提升模型性能。该模型的提出者认为,通过两个3×3的卷积核堆叠的感受野(receptive field)相当于一个5×5的卷积核,三个3×3的卷积核堆叠的感受野相当于一个7×7的卷积核,这也是该模型的层数多于其他模型的原因。
③ 池化层使用2×2大小的池化核,使用最大池化(maxpooling)区分不同的层。每次池化操作之后,图像的尺寸缩小到原来的四分之一。
④ 全连接层统一使用ReLU激活函数,输出层使用softmax函数对结果进行分类,得到1000个类别对应的预测概率值。
在每一个全连接层计算完成后,需要使用Dropout函数,即随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。
⑤ 图像的通道数更多。每次卷积操作都会增加图像的通道数,每个通道都表示一个特征映射(FeatureMap),更多的通道数就代表了更丰富的图像特征,使得更多的信息可以被提取出来。
⑥ 层数更深。正如前文所说,由于在卷积层统一使用3×3大小的卷积核,其两次的卷积操作相当于其他5×5卷积核模型的一次卷积操作,因此该模型相较于其他模型具有更深的层数。这样的好处是可以减少参数的个数,从而减少计算量。
⑦ 全连接层转卷积。VGG19模型在神经网络的测试阶段时将三个全连接网络替换为三次卷积操作,同时在测试时重用训练时的参数。如图所示:
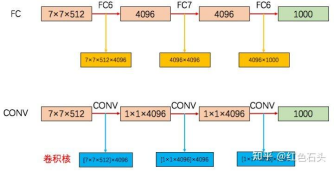
将三个连接层FC6、FC7、FC8替换成了4096个7×7×512的卷积核、1×1×4096的卷积核、1×1×4096的卷积核。
替换的原因:
a. 正如前文所说,VGG19限制了输入图片的尺寸是224x224x3。如果采用全连接层,当遇到尺寸不为224×224的图像时,就需要对图像进行裁剪、缩放或其他的图像预处理操作,这些操作可能导致原图片中的关键目标信息丢失,最终导致模型的测试精度下降。将全连接层替换成卷积后,由于没有了全连接层的限制,使得网络模型可以接受任意尺寸的图像作为输入。
b. 使用卷积操作,即使输入图片尺寸大于224x224时,将softmax层分类的结果进行空间平均化(即求和池化)后,也可以得到1x1x1000的测试结果,即1000个类别对应的概率。并且使用卷积操作也可以减少特征位置给分类带来的影响。
⑧ 输出的结果为1x1x1000的图像,分别对应于1000个不同类别的特征图像。使用softmax函数后,可以求出每个类别对应的预测概率。
(2)卷积神经网络实现风格迁移
风格迁移与图像分类的区别:
- mVGGNet是图像分类模型,其用途是将图像输入到网络中,提取图像的特征,然后输出该图像可能的类别。
- 图像风格迁移恰好与其相反,输入内容图像与风格图像的特征,将风格图像的特征融入到内容图像,输出风格迁移后的图片。如下图所示:
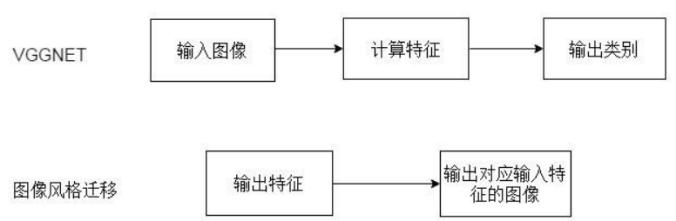
卷积神经网络实现风格迁移:
利用卷积神经网络实现风格迁移时,输入的图片不需要经过整个卷积神经网络的流程(因为经过整个流程后,得到的是图片的分类结果),而只需要从特定的卷积层提取出图像的特征,将内容特征和风格特征分别进行迭代以优化模型,最后将特征图像进行神经网络的反向传播,就能还原出对应这种特征的原始图像。
在风格迁移的研究中发现:经过浅层的卷积后,还原出来的图像能够基本保留原始图像中的形状、位置、颜色等信息;而深层卷积后,还原图像丢失了部分颜色和纹理信息,只保留了原始图像中物体的形状和位置信息。因此,在进行风格迁移时,对内容输入图像使用深层卷积,对风格输入图像使用浅层卷积,最终复原出来的风格图像可以在保留内容图像的主要形状与轮廓的同时,也能够具有风格图像的风格特征。
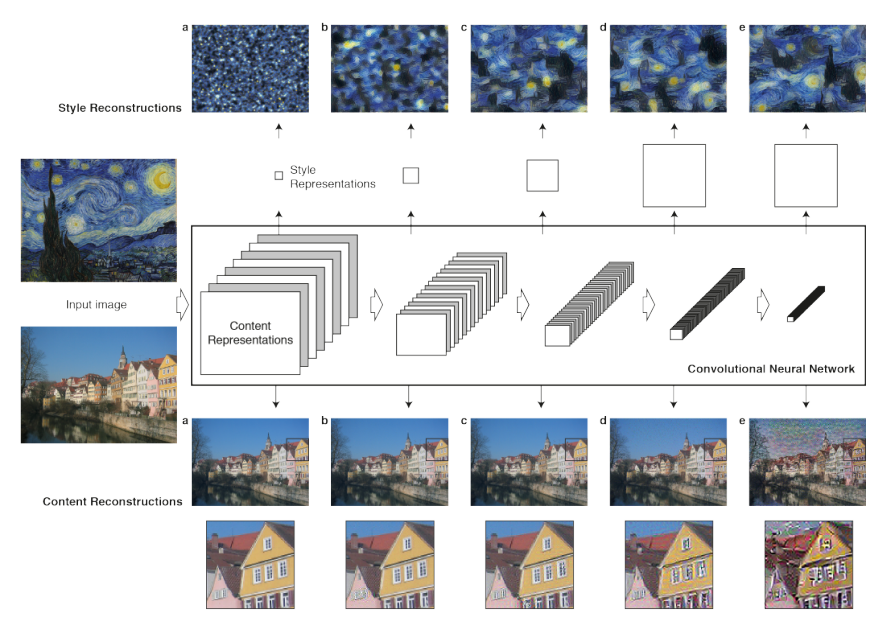
要构建一个基于CNN的风格迁移系统,首先需要为生成的图像定义代价损失函数。
风格迁移的代价函数有两个:其一是内容代价函数,用于衡量生成的图片与原内容图片的相似度;其二是风格代价函数,用于衡量生成的图片与输入的风格图片的相似度。
除了这两个代价函数外,还可以根据需要设置一些其他的损失函数,例如语义内容损失等。最后,将这些代价函数与损失函数加权求和,通过最小化总损失函数的方法来迭代优化风格迁移模型。
风格迁移模型的层次结构:
输入层:将内容图像和风格图像作为输入。
卷积层:通过多个卷积层提取图像的特征信息。
损失函数层:计算内容损失和风格损失,通过最小化损失函数来优化网络参数。
反卷积层:通过反卷积操作将特征图重建为最终的风格化图像。
输出层:输出经过风格迁移后的图像。
具体的步骤如下(以VGG19为例):
-
将内容图片输入到VGG网络中,使用VGG较深的卷积层例如conv4_2 , conv5_2的输出结果来表示获取到的内容特征。(注:conv4_2表示第4个卷积层的第2次卷积操作,其他同理)
-
通过反卷积的操作,将得到的内容特征图重构成一张噪声图。
-
计算内容损失函数。内容损失主要用于衡量生成的图像与内容图像的相似度,简单来讲就是计算这两张图之间的“距离”,因此可以选择曼哈顿距离、欧式距离等距离计算方法,这里以欧式距离为例:内容图像在指定通道上提取出来的特征矩阵与噪声图像在相同通道上提取出来的特征矩阵像素差值的平方。对应的每一个通道的内容损失函数如下:
L i = 1 2 ∗ M ∗ N ∑ i j ( X i j − P i j ) 2 L_i=\frac{1}{2*M*N}\sum_{ij}(X_{ij}-P_{ij})^2 Li=2∗M∗N1ij∑(Xij−Pij)2
其中i、j是像素的对应位置,X是噪声图像的特征矩阵,P是内容图像的特征矩阵,M是内容图像的像素个数(即长*宽),N是图像的通道数。
总的内容损失即为各个通道损失的加权求和。 -
将风格图像输入到VGG网络中,使用VGG较浅的卷积层例如conv1_1,conv2_1,conv3_1,conv4_1的输出来表示获得的风格特征。
-
通过反卷积,将风格特征图重构成噪声图。
-
计算风格损失函数。计算风格损失函数需要用到GRAM矩阵,其具体的计算方法为:分别计算风格图像与噪声图像的GRAM矩阵,风格损失即为风格图像与噪声图像特征的GRAM矩阵差值的平方。对应的每一个通道的风格损失函数如下:
L i = 1 4 ∗ M 2 ∗ N 2 ∑ i j ( G i j − A i j ) 2 L_i=\frac{1}{4*M^2*N^2}\sum_{ij}(G_{ij}-A_{ij})^2 Li=4∗M2∗N21ij∑(Gij−Aij)2
其中G是噪音图像特征的Gram矩阵,A是风格图片特征的GRAM矩阵,i、j、M、N含义和上一个式子相同。 -
最终用于训练的损失函数为内容损失和风格损失的加权和。(当然可以再加上其他的损失值)
L t o t a l = α L c o n t e n t + β L s t y l e L_{total}=\alpha L_{content}+\beta L_{style} Ltotal=αLcontent+βLstyle
计算损失函数后,可以通过梯度下降等方法对模型的参数进行修正。 -
不断执行上述的过程,对模型进行迭代优化,直到达到一定的迭代次数或满足精度的要求后,就能够完成模型的训练。
2. 融合注意力感知的风格迁移
虽然现有的方法已经可以实现风格的迁移,但是在内容图像和风格图像的视觉注意力的空间分布差异较大时运行效果不尽人意,而且大多对图像做没有区分的处理,没有区分不同层次的细节。
而该注意感知的多笔触风格转移项目就综合考虑了上面两个问题,通过在重建框架中引入一个自注意模块来获取内容图像视觉注意力的空间分布,通过多尺度风格交换和多笔触融合模块来对图像种不同层次做不同细节尺度上的处理。
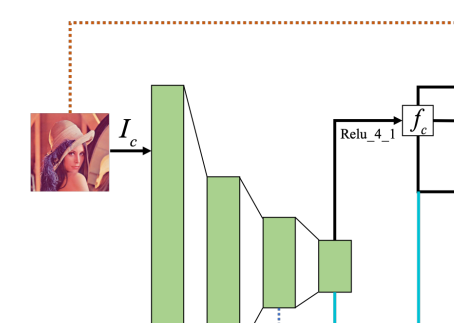
项目的整体框架图如下:首先通过vgg神经网络提取出内容图
I
c
I_c
Ic和风格图
I
s
I_s
Is的特征
f
c
f_c
fc和
f
s
f_s
fs,然后用训练好的自注意模块来提取出
f
c
f_c
fc的注意图
A
c
A_c
Ac。用
f
c
f_c
fc和
f
s
f_s
fs作为多尺度风格交换的输入,得到由用户输入的K决定的融合的特征
f
^
c
s
K
\hat{f}^K_{cs}
f^csK和白化的内容特征
f
^
c
s
0
(
f
c
)
\hat{f}^0_{cs}(f_c)
f^cs0(fc)。在多笔触融合部分,先要对注意图
A
c
A_c
Ac做注意力滤波处理得到
A
^
c
\hat{A}_c
A^c,还要应用K -means方法对注意力图进行聚类处理,得到K+1类后用注意图对特征进行指导构建出融合后的特征
f
c
s
f_{cs}
fcs。最后用
f
c
s
f_{cs}
fcs重建风格化的图像。
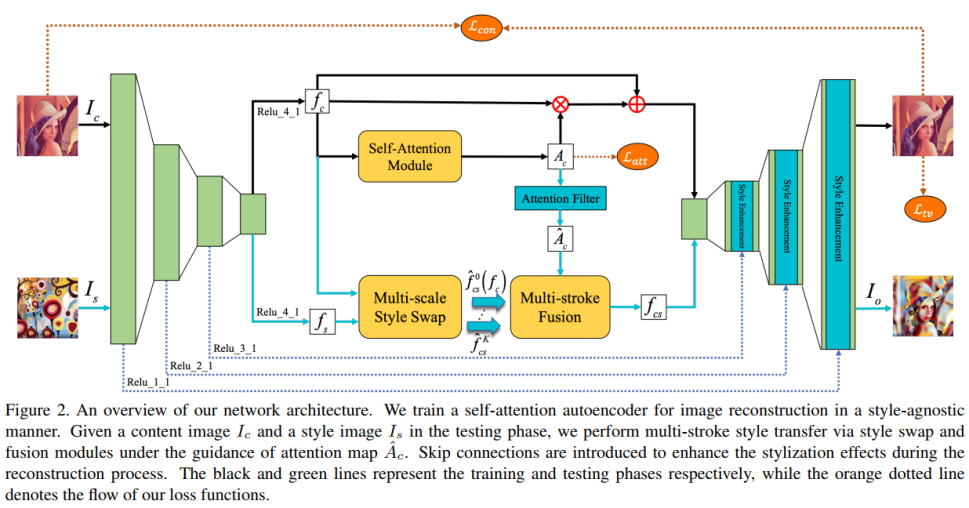
项目的贡献主要在于在瓶颈层引入了三个模块用于特征操作,下面将详细介绍这三个模块。
(1)自注意力自动编码器 Self-Attention Autoencoder
自注意力自动编码器主要用在AAMS模型的训练阶段。该自动编码器是一个不断迭代优化的过程。先将训练图片输入VGG19卷积神经网络中以提取图像的特征,使用VGG19中特定的卷积层的输出作为特征图(content feature)。
接下来,将特征图输入到自注意力模块(Self-Attention Module)中,从而产生一张自注意力特征图(self-attention feature map)。
然后,将特征图与自注意力图做卷积操作后再加上特征图,得到的结果输入到解码器中,进行逆向卷积操作,并使用超采样的方法进行风格增强,从而将融合的特征图重构成一张完整的图片。
最后,将求原图和重构的图片之间的语义内容损失,加上自注意力特征图的稀疏损失和正则化损失作为总的损失函数,通过最小化该损失函数的方法不断迭代优化自动编码器模型。
- 特征图像的提取
从VGG特定卷积层提取图像特信息。该部分在预备知识讲过,不再赘述。
- 自注意力特征图像的生成
该步骤由自注意力模块完成,主要用于捕捉分离的空间区域之间的关系。
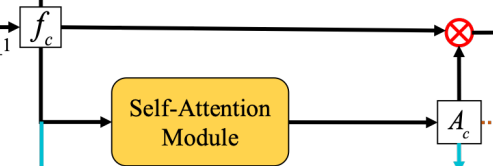
自注意力模块以从编码器中提取的内容特征作为输入,得到自注意特征图作为输出。
自注意力模块对应于AAMS/net/aams.py中的self_attention()函数。
A x i = ∑ j = 1 H W α i j ∗ f l a t ( f x ⨂ Θ h ) j A^i_x=\sum_{j=1}^{HW}\alpha_{ij}*flat(f_x\bigotimes \Theta_h)_j Axi=j=1∑HWαij∗flat(fx⨂Θh)j
其中 ⨂ \bigotimes ⨂表示卷积操作, a i j a_{ij} aij是区域 i i i和区域 j j j之间的权重系数, f x f_x fx是输入该模块的特征图像, Θ h \Theta_h Θh是训练过程的参数矩阵。 f l a t ( ) flat() flat()函数用于将多维输入数据转换为一维向量。 - 图像的重建

通过将获得的自注意力特征图 A x A_x Ax和输入特征图 f x f_x fx相乘得到一个自注意力残差,然后将残差附在特征图 f x f_x fx上,即可得到融合后的特征图。最后将该特征图输入解码器,即可重构图像。
O x = R x + f x = A x ⨀ f x + f x O_x=R_x+f_x=A_x\bigodot f_x+f_x Ox=Rx+fx=Ax⨀fx+fx
其中 A x A_x Ax为自注意力图像, f x f_x fx为特征图像。运算符表示矩阵相乘。 - 最小化损失函数以迭代优化模型

(1)定义内容损失函数为感知图像损失和像素重建损失的总和:
L c o n = ∑ l ∈ l c ∣ ∣ ϕ l ( x ^ ) − ϕ l ( x ) ∣ ∣ 2 2 + λ p ∣ ∣ x ^ − x ∣ ∣ 2 2 \cal L_{con}=\sum_{l\in l_c} ||\phi_l(\hat{x})-\phi_l(x)||_2^2+\lambda_p||\hat{x}-x||_2^2 Lcon=l∈lc∑∣∣ϕl(x^)−ϕl(x)∣∣22+λp∣∣x^−x∣∣22
其中
ϕ
l
(
x
)
\phi_l(x)
ϕl(x)是处理图像x时预训练的VGG19网络层的激活值。
λ
p
\lambda_p
λp是平衡两种损失的权重。
(2)在自注意力图像上定义了稀疏损失,以鼓励自注意力自动编码器更多地关注小区域而不是整个图像,其中
A
x
A_x
Ax为自注意力图:
L
a
t
t
=
∣
∣
A
x
∣
∣
1
\cal L_{att}=||\rm A_x||_1
Latt=∣∣Ax∣∣1
(3)还添加总变分正则化损失
L
t
v
\cal L_{tv}
Ltv,来保证生成图像的空间平滑。
(4)最后,总的损失函数为:(
λ
c
o
n
,
λ
a
t
t
和
λ
t
v
\lambda_{con},\lambda_{att}和\lambda_{tv}
λcon,λatt和λtv都是平衡因子)
L
=
λ
c
o
n
L
c
o
n
+
λ
a
t
t
L
a
t
t
+
λ
t
v
L
t
v
\cal L=\lambda_{con}L_{con}+\lambda_{att}L_{att}+\lambda_{tv}L_{tv}
L=λconLcon+λattLatt+λtvLtv
该部分对应于AAMS/net/aams.py中的self_attention_autoencoder()函数。
(2)多尺度风格交换 Multi-scale Style Swap
风格交换是用最接近的样式特征逐块地替换内容特征的过程。该模块以从编码器中提取出的风格特征(style features)和训练过程中的内容特征图作为输入,得到多个笔触大小(stroke sizes)的特征。其中K是用户提供的聚类数(笔触数)。
在这一模块中,项目采用了在改变风格激活特征图的同时固定交换块的大小,这样就可以在于相同内容特征交换后引入多尺度的笔触。
具体来说,先用白化变换对内容特征fc和风格特征fs在保持全局结构的同时剥离其风格信息,结果记为
f
^
s
\hat{f}_s
f^s和
f
^
c
\hat{f}_c
f^c。然后将白化后的风格特征映射到多个尺度上,得到一系列多尺度风格特征:
f
^
s
k
=
T
β
k
(
f
s
^
)
\hat{f}_s^k=\cal T_{\beta_k}(\hat{f_s})
f^sk=Tβk(fs^)
其中
T
\cal T
T是缩放变换,
β
k
(
k
=
1
,
2
,
…
,
k
)
β_k(k=1,2,…,k)
βk(k=1,2,…,k)是控制不同笔触尺寸的缩放系数。最后,通过在
f
^
c
\hat{f}_c
f^c和多个
f
^
s
k
\hat{f}_s^k
f^sk间同时执行风格交换来产生多个交换特征
f
^
c
s
k
=
F
s
s
(
f
^
c
,
f
^
s
k
)
\hat{f}_{cs}^k=\cal F_{ss}(\hat{f}_c,\hat{f}_s^k)
f^csk=Fss(f^c,f^sk)
其中
F
s
s
\cal F_{ss}
Fss是可并行化的风格交换过程。
该部分对应于AAMS/net/aams.py中的multi_scale_style_swap()函数。
(3)多笔触融合模块 Multi-stroke Fusion
该模块以多尺度风格转换生成的多个笔触大小的特征作为输入,使用经过过滤后的自注意力特征图指导这些多笔触特征的融合,最后得到融合后的特征作为输出。
首先利用注意力过滤器对前面的得到的自注意力特征图 A c A_{c} Ac取绝对值,以突出显示特征图中非0的部分,然后通过高斯核卷积层增强区域一致性。我们可以利用高斯核的方差来进一步控制显著区域在内容图像中的比例,将其归一化到[0,1]后得到注意力图 A ^ c \hat{A}_{c} A^c
为了指导任意多个笔触大小的特征(设从多尺度风格交换中得到K个交换特征
f
^
c
s
k
\hat{f}_{cs}^{k}
f^csk,且引入白化内容特征以标记最显著的区域,记作
f
^
c
s
0
\hat{f}_{cs}^{0}
f^cs0,则一共有K+1个笔触特征),项目采用了k-means方法迭代寻找K+1个聚类中心
a
r
g
m
i
n
G
=
∑
k
=
0
K
∑
a
^
c
i
∈
S
K
∣
∣
a
^
c
i
−
m
k
∣
∣
2
arg min\cal G=\sum_{k=0}^{\rm K}\sum_{\hat{a}_c^i\in \rm S_K}||\hat{a}^i_c-m_k||^2
argminG=k=0∑Ka^ci∈SK∑∣∣a^ci−mk∣∣2
其中
m
k
m_{k}
mk表示簇中所有关注点
a
^
c
i
\hat{a}_{c}^{i}
a^ci的平均强度值。然后,多笔画融合可以表述为在注意图的指导下将内容特征与多个交换特征进行集成:
f
^
c
s
=
∑
k
=
0
K
A
^
c
k
f
^
c
s
k
\hat{f}_{cs}=\sum^K_{k=0}\hat{A}^k_c\hat{f}^k_{cs}
f^cs=k=0∑KA^ckf^csk
其中
f
^
c
s
\hat{f}_{cs}
f^cs为风格化后的图像,
A
^
c
k
\hat{A}_{c}^{k}
A^ck为权重图中第k个笔触特征的权重(由softmax函数得到)
该部分对应于AAMS/net/aams.py中的multi_stroke_fusion()函数。
三、代码部分
该项目的文件组织形式如图所示:
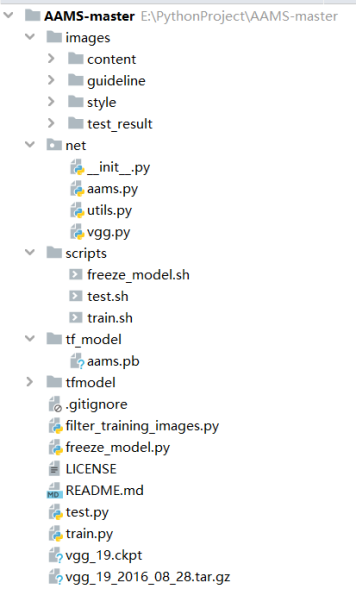
- images目录:包含四个子目录。其中,content目录下存放内容图;guideline目录下存放AAMS风格迁移方法生成结果和其他风格迁移方法的生成结果的对比图、以及AAMS设置不同笔触大小生成的结果图;style目录下存放风格图;test_result目录由使用者自己创建,用于存放用户使用该项目生成的风格迁移图。
- net目录:包含了AAMS方法使用的卷积神经网络,是该项目的核心内容。其中aams.py是基于AAMS方法的神经网络模型;utils.py文件包含了该项目所用到的一些函数,例如求卷积操作等;vgg.py文件中重载了VGG19卷积神经网络模型。详细的内容在后面介绍。
scripts目录:存放了训练模型train.py,测试模型test.py,生成模型freeze_model.py这三个文件对应的shell脚本。可以使用这些脚本运行这三个文件。 - tf_model目录:包含了作者根据COCO2014数据集预训练好的模型,也是作者在论文中使用的模型。可以使用该模型快速入手。
- tfmodel目录:用于存放使用者在训练模型的过程中产生的中间产物。包含了一个检查点文本文件checkpoint.txt,以及TensorFlow 框架保存的用于存储模型训练过程中的参数权重和其他相关信息的模型检查点文件(.ckpt)。当使用freeze_model.py将检查点文件生成模型时,所生成的模型也保存在该目录下。
其他的文件:
- filter_training_images.py:以数据集的绝对路径(或在该项目中创建一个名为datasets的目录,并将数据集保存在该路径下)作为输入参数,对数据集中的图片进行处理,删除了灰度图片等不合法的图片;
- freeze_model.py:以tfmodel目录下的.ckpt检查点文件作为输入,用于将训练好的模型进行冻结,保存成一个名为aams.pb的冻结图方便在其他平台或设备使用;
- train.py:以数据集的路径作为输入,使用数据集来训练模型,训练的中间产物会保存在tfmodel目录下。
- test.py:以冻结的模型、内容图、风格图、内容-风格交互权重为参数,生成的结果会保留在tfmodel目录中。
1. 获取数据集并筛选
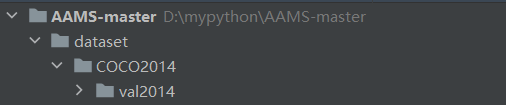
数据集方面,选取了COCO2014数据集作为模型训练数据,若COCO官网无法下载,也可通过kaggle下载。下载后的数据集文件包含了训练图像(train2014)、测试图像(test2014)、验证图像(val2014)以及对应的的标签文件(annotations)。本项目用到的数据集主要是val2014这部分的图像,在项目的根目录下,新建一个名为dataset的文件夹(如果没有),并将解压后的coco2014数据集放入该目录(如图)
接下来,我们要在pycharm中运行程序来筛除掉不合格式的图片。找到项目文件下的
filter_training_images.py文件,右击进入更多运行/调试,选择修改运行配置进入配置页面
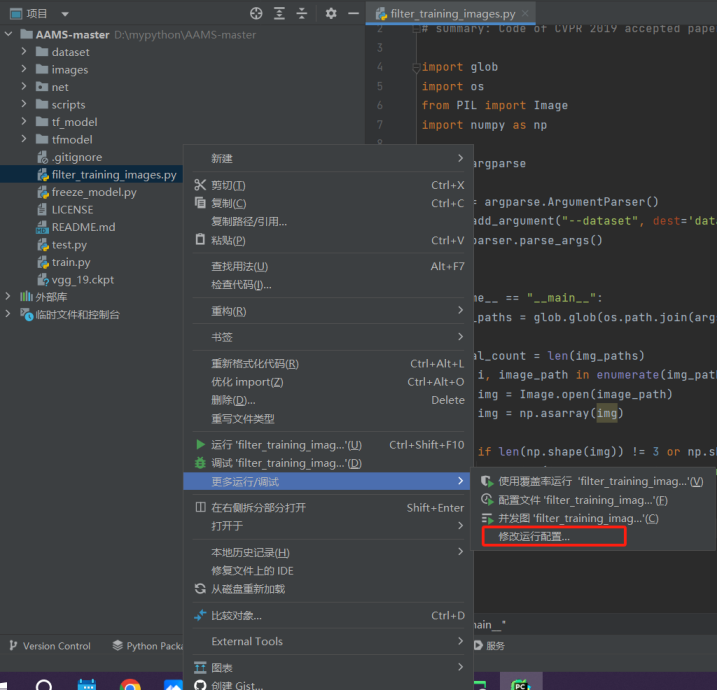
这里只需要更改形参的值即可,其他不用管。在形参那一栏输入
--dataset dataset/[val2014的路径]
这里演示的路径为:dataset/COCO2014/val2014(注意该目录必须是装载图片文件的目录,不能再有子目录,否则程序会直接显示clean done并退出),点击应用后,运行filter_training_images.py即可自动筛掉不合格式的图像,并覆盖原先的数据集(因此不用操心输出路径,直接在原路径上进行接下来的工作即可)。
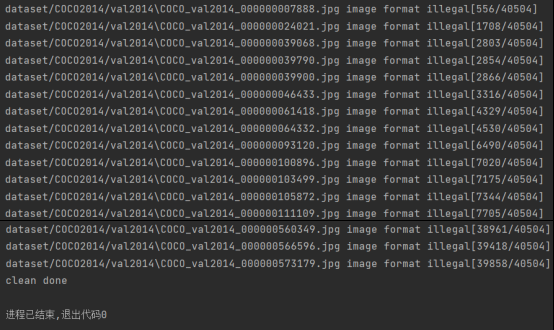
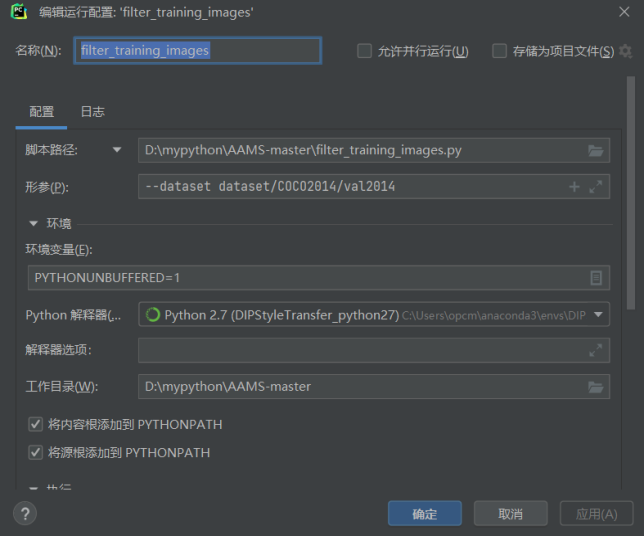 点击运行后,看到如下样式的输出,并且最后显示clean done,则说明数据集筛选完毕。
点击运行后,看到如下样式的输出,并且最后显示clean done,则说明数据集筛选完毕。
2. 训练
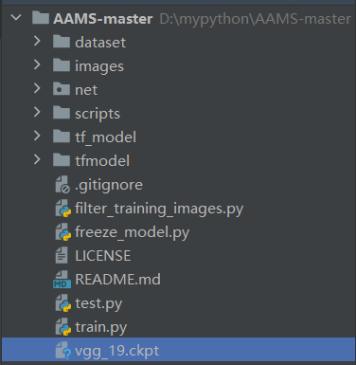
首先下载预训练好的VGG-19模型,解压后得到名为vgg_19.ckpt的模型文件,将其拖入项目文件下即可(如图)。
训练文件的配置与上述filter_training_images.py文件的配置相同。pycharm内找到项目文件下的train.py,右击进入更多运行/调试->修改运行配置进入配置页面后,同样将形参修改为
--dataset dataset/[val2014的路径]
(演示的路径为:dataset/COCO2014/val2014),点击应用后,运行train.py,即可利用VGG-19训练自注意自动编码器。
注意:
- 在训练过程中,可能会遇到ImportError的问题(最好事不要遇到)。这时要去对应的路径检查一下要导入的包内是否有__init__.py文件,如果没有的话加上一个空的就好了,因为pycharm如果文件夹内没有__init__.py文件的话就找不到这个包。
- 训练时会占用C盘空间,并且训练步数有80000步,正常的PC应该很难一次训练完。
训练过程:
训练的中间产物(每隔一段步数记录当前模型的参数):
3. 测试
开始测试前,首先在项目文件下的images文件夹新建一个空的test_result文件夹:
接下来配置测试文件test.py。在项目中找到这个.py文件,同样是右键进入更多运行/调试->修改运行配置->形参。输入以下参数(每个参数之间用空格隔开):
--model tf_model/aams.pb
--content images/content/bird.jpg
--style images/style/pencil.jpg
--inter_weight 1.0
其中
- –content images/content/bird.jpg是输入的内容图,即要迁移风格的图像;
- –style images/style/pencil.jpg是输入的风格图,即输出图像所用的的风格;
- –inter_weight 1.0表示内容与风格之间的交互权重。该权重用于控制样式转移过程中内容和样式之间的平衡。inter_weight值越大,输出风格化的图像将更加强调风格;而inter_weight值越小,则更加保留原始内容。这里默认设置为1.0即可。
点击应用后,运行test.py即可开始生成风格化的图像:
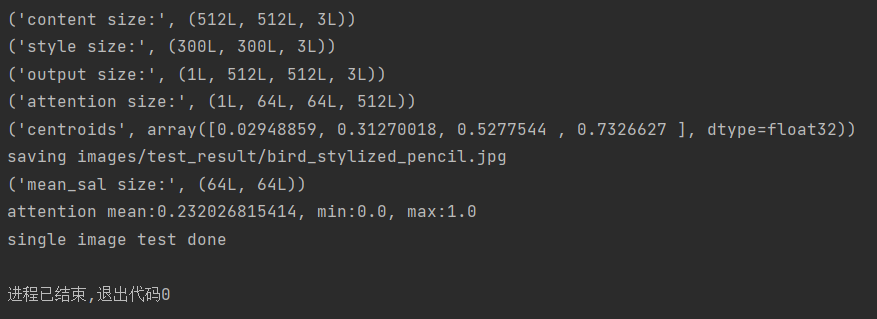
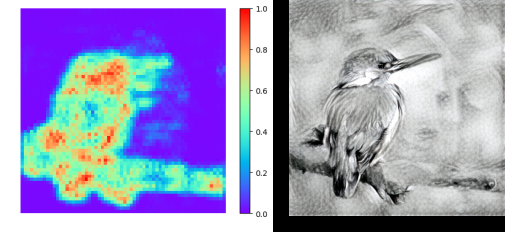
若如图所示,则表明代码运行成功。这时候我们可以在刚刚创建的tets_result文件夹中发现以下两个输出图像:
其中bird_mean_atten.png即为模型输出的原内容图的注意力图(下左);
bird_stylized_pencil.jpg即为模型输出的风格化图像(下右);
修改参数
--content images/content/bird.jpg
和
--style images/style/pencil.jpg
即可指定不同的风格图和内容图。
以下是一些代码效果图:
| 内容图 | 风格图 | 结果 |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |















 3208
3208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









