







九、标签对象提取文本内容和属性值
find_element仅仅能够定位元素,不能够直接获取其中的数据,如果需要提取数据需要使用以下方法
element.get_attribute('属性名') # 获取元素属性值
element.text # 获取元素文本内容
input_element.send_keys('selenium') # 向输入框输入数据
button_element.click() # 对元素执行点击操作
十、selenium标签页的切换
当selenium控制浏览器打开多个标签页时,如何控制浏览器在不同的标签页中进行切换呢?需要我们做以下两步:
所有标签页的窗口句柄
利用窗口句柄字切换到句柄指向的标签页
这里的窗口句柄是指:指向标签页对象的标识
# 1. 当前所有的标签页的句柄构成的列表
current_windows = driver.window_handles
# 2. 根据标签页句柄列表索引下标进行切换
driver.switch_to.window(current_windows[0])
当有两个以上的窗口时,就要注意了,当前显示的窗口可能并不是当前窗口,你以显示窗口做的一些操作,肯定对当前窗口无效。这是我踩过的深坑之一。
十一、Selenium的行为链
Selenium的行为链(ActionChains)是一种用于模拟用户在浏览器中执行各种鼠标和键盘操作的方法。这些操作可以包括鼠标移动、点击、拖放、键盘按键等,允许您模拟用户在Web应用程序上的交互行为。行为链通常用于实现复杂的用户操作,例如鼠标悬停、拖放元素等。
鼠标操作:
double_click():鼠标双击
context_click():鼠标右击
click():鼠标单击
drag_and_drop(element1,element2):元素拖拽,把element1元素拖拽到element2位置
drag_and_drop_by_offset(element,x,y):元素拖拽,相对于element元素当前位置拖拽到(原x坐标+x,原y坐标+y)
move_to_element(element):鼠标悬停在element元素位置
move_to_element_with_offset(element,x,y):和drag_and_drop_by_offset作用相同,x,y值可为正负
click_and_hold(element):鼠标左键按住element元素
move_by_offset(x,y):相对于鼠标按住的位置移动(x,y)
release():释放按住的鼠标
注:后三个一般是放在一起使用的。所有的方法都是由ActionChains(driver)实例对象调用。
十二、爬虫开始工作:
def crawl(driver, papers_need,keyword): # 爬虫开始工作
# 赋值序号, 控制爬取的文章数量
if papers_need > res_num:
print('对不起,你输入的篇数太大,将按实有篇数检索')
papers_need = res_num
count = 1
# 当爬取数量小于需求时,循环网页页码
while count < papers_need:
# 等待加载完全,休眠3S
time.sleep(3)
title_list = WebDriverWait(driver, 10,0.5).until(EC.presence_of_all_elements_located((By.CLASS_NAME, "fz14")))
# print(title_list)
# 循环网页一页中的条目
for i in range(len(title_list)):
try:
if count % len(title_list) != 0:
term = count % len(title_list) # 本页的第几个条目
else:
term = len(title_list) # 本页的最后一个条目
# term == i
# print(3,term)
# term = count % 50 # 本页的第几个条目
date_xpath = f"/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[5]"
date = WebDriverWait(driver, 10,0.5).until(EC.presence_of_element_located((By.XPATH, date_xpath))).text
# 点击条目
title_list[i].click()
time.sleep(1)
# 获取driver的句柄
n = driver.window_handles
# driver切换至最新生产的页面
driver.switch_to.window(n[-1])
time.sleep(2)
# 开始获取页面信息
title = WebDriverWait(driver, 10,0.5).until(EC.presence_of_element_located((
By.XPATH ,"/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h1"))).text # 标题
authors = WebDriverWait(driver, 10,0.5).until(EC.presence_of_element_located((
By.XPATH ,"/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h3[1]"))).text # 作者
institute = WebDriverWait(driver, 10,0.5).until(EC.presence_of_element_located((
By.XPATH, "/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h3[2]"))).text # 作者单位
try:
search_more = driver.find_element(By.ID, 'ChDivSummaryMore') # 如果摘要没显示完全,点击“更多”后再读取
search_more.click()
time.sleep(1)
abstract = '更多',WebDriverWait(driver, 10,0.5).until(EC.presence_of_element_located((
By.CLASS_NAME, "abstract-text"))).text # 文章摘要
except:
abstract = '摘要',WebDriverWait(driver, 10,0.5).until(EC.presence_of_element_located((
By.CLASS_NAME, "abstract-text"))).text # 文章摘要
try:
keywords = WebDriverWait(driver, 10,0.5).until(EC.presence_of_element_located((
By.CLASS_NAME, "keywords"))).text[:-1] # 关键词
except:
keywords = '无'
url = driver.current_url
# 写入文件
res = f"{count}\t{title}\t{authors}\t{institute}\t{date}\t{keywords}\t{abstract}\t{url}".replace("\n", "") + "\n"
print(res)
try:
with open(f'CNKI_{keyword}.tsv', 'a', encoding='gbk') as f:
f.write(res)
except:
print('文件已打开,请先关闭')
except:
print(f" 第{count} 条爬取失败\n")
count += 1
# 跳过本条,接着下一个
continue
finally:
# 如果有多个窗口,关闭第二个窗口, 切换回主页
n2 = driver.window_handles
if len(n2) > 1:
driver.close()
driver.switch_to.window(n2[0])
# 计数,判断需求是否足够
count += 1
if count == papers_need + 1:
break
# 切换到下一页
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//a[@id='PageNext']"))).click()
except:
print('☆☆☆☆☆检索完成!')
break点选篇目一:
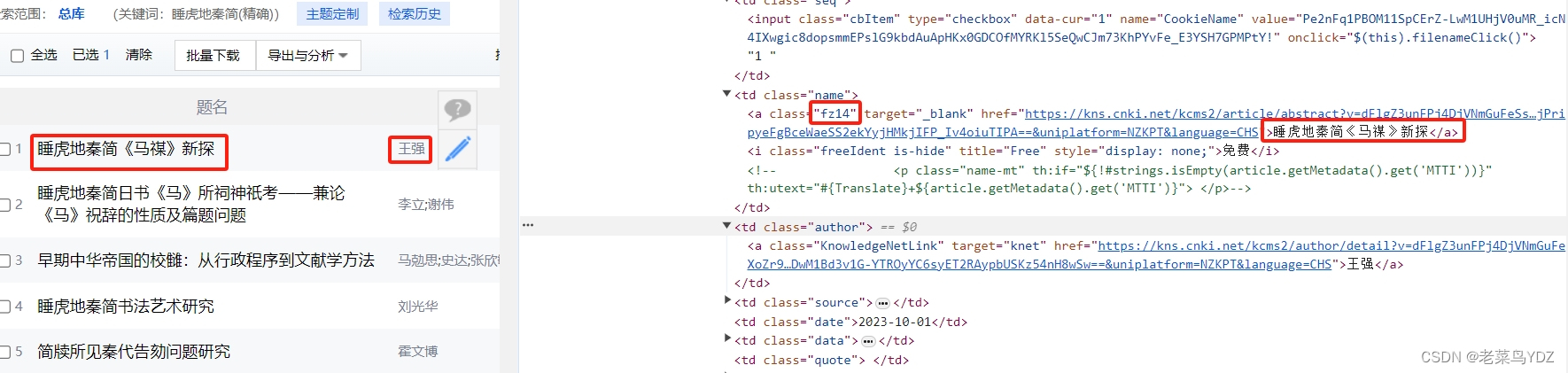
爬取篇名、作者、作者单位:

爬取摘要内容:
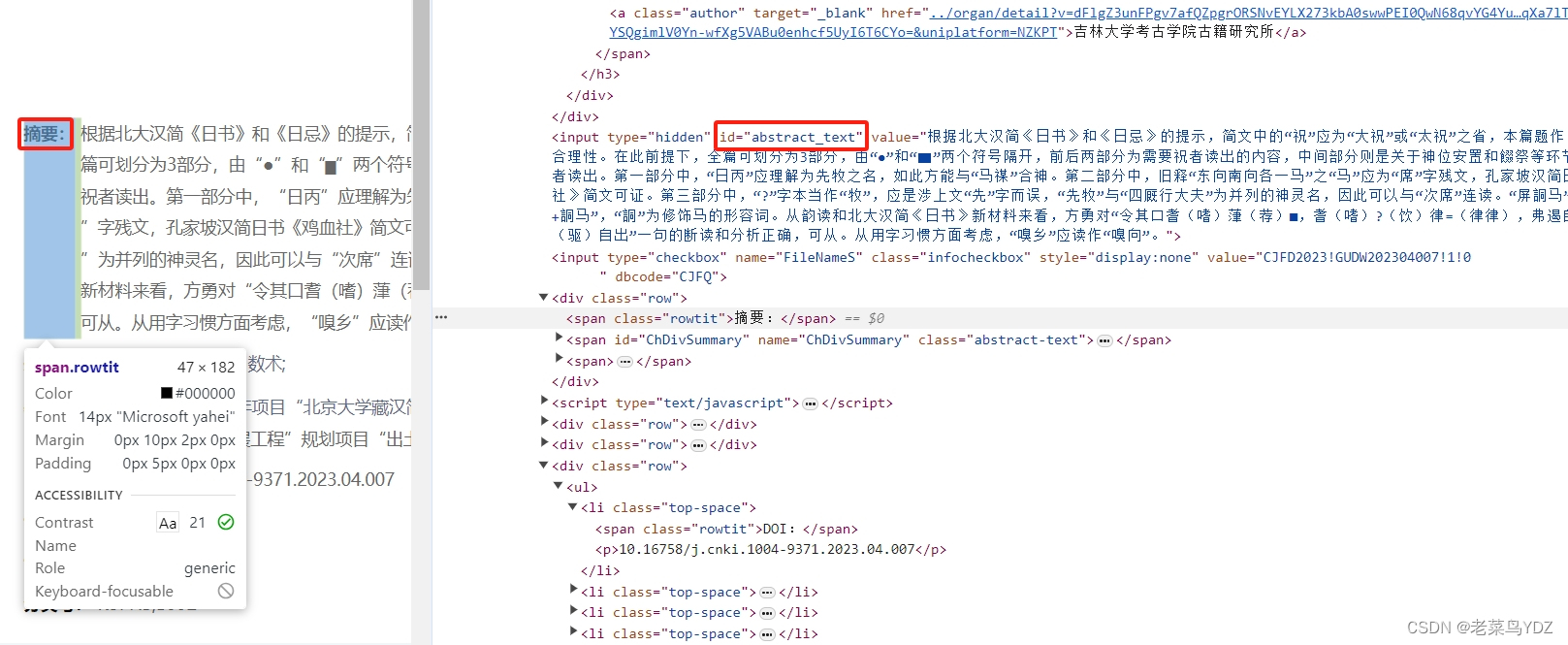
如果摘要显示不全,点击更多,以显示全部摘要:
















 7357
7357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









