







try:
data.to_sql(db_name,engine,index=False,if_exists=if_exists)
#print(code+‘写入数据库成功’)
except:
pass
复制代码
由于行情数据量庞大,下载比较慢,先下载20190101至20190425期间日交易
数据,后续再不断更新。
#下载20190101-20190425数据并插入数据库stock_data
#此步骤比较耗费时间,大致25-35分钟左右
for code in get_code():
data=get_data(code)
insert_sql(data,‘stock_data’)
#读取整张表数据
df=pd.read_sql(‘stock_data’,engine)
print(len(df))
#输出结果:270998
#选取ts_code=000001.SZ的股票数据
df=pd.read_sql(“select * from stock_data where ts_code=‘000001.SZ’”,engine)
print(len(df))
复制代码
构建一个数据更新函数,可以下载和插入其他时间周期的数据。2018年1月1日至2019年4月25日,数据就已达到108万条。
#更新数据或下载其他期间数据
def update_sql(start,end,db_name):
from datetime import datetime,timedelta
for code in get_code():
data=get_data(code,start,end)
insert_sql(data,db_name)
print(f’{start}:{end}期间数据已成功更新’)
#下载20180101-20181231期间数据
#只需运行一次,不再运行后可以注释掉
#下载数据比较慢,需要20-35分钟左右
start=‘20180101’
end=‘20181231’
db_name=‘stock_data’
#数据下载和存入数据库
update_sql(start,end,db_name)
#使用pandas的read_sql读取数据
df_all_data=pd.read_sql(‘stock_data’,engine)
print(len(df_all_data))
#输出结果:1087050
#查看交易代码和交易日期个数
print(len(df_all_data.ts_code.unique()))
print(len(df_all_data.trade_date.unique()))
#输出结果:3604;319
d=df_all_data.trade_date.unique()
print(d.max())
print(d.min())
2019-04-25T00:00:00.000000000
2018-01-02T00:00:00.000000000
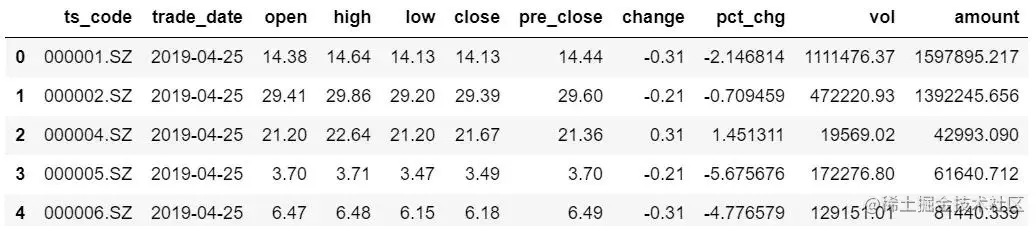
#获取交易日2019年4月25日数据
pd.read_sql("select * from stock_data where trade_date=‘2019-04-25’ ",engine).head()
复制代码
构建数据查询和可视化函数:
def plot_data(condition,title):
from pyecharts import Bar
from sqlalchemy import create_engine
engine = create_engine(‘postgresql+psycopg2://postgres:123456@localhost:5432/postgres’)
data=pd.read_sql(“select * from stock_data where+”+ condition,engine)
count_=data.groupby(‘trade_date’)[‘ts_code’].count()
attr=count_.index
v1=count_.values
bar=Bar(title,title_text_size=15)
bar.add(‘’,attr,v1,is_splitline_show=False,linewidth=2)
return bar
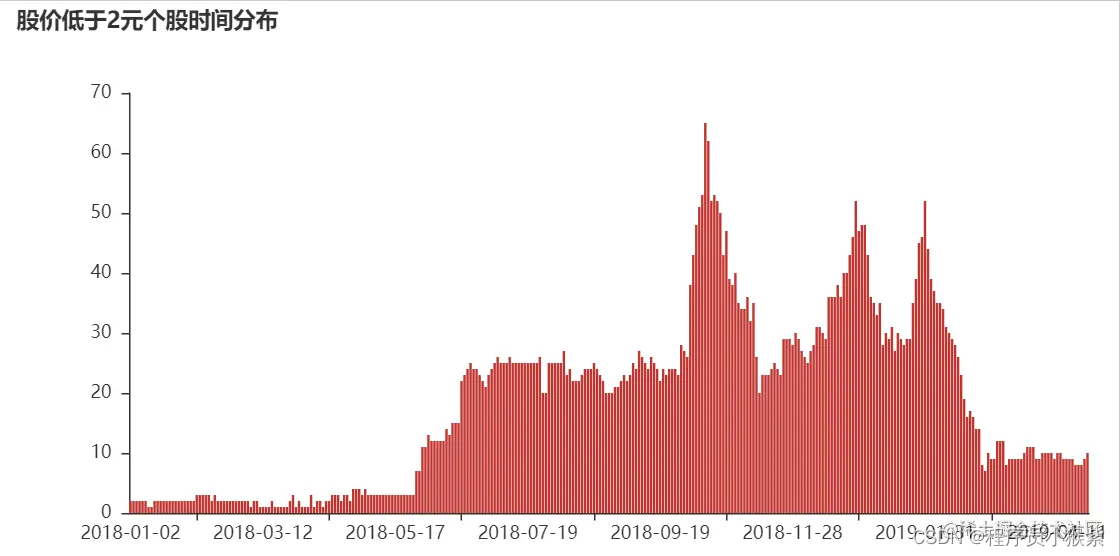
查询股价低于2元个股数据分布
c1=“close<2”
t1=“股价低于2元个股时间分布”
plot_data(c1,t1)
复制代码
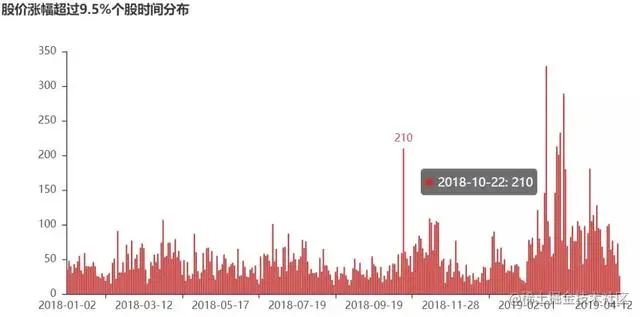
查询股价日涨幅超过9.5%个股数据分布:
c2=“pct_chg>9.5”
t2=“股价涨幅超过9.5%个股时间分布”
plot_data(c2,t2)
复制代码
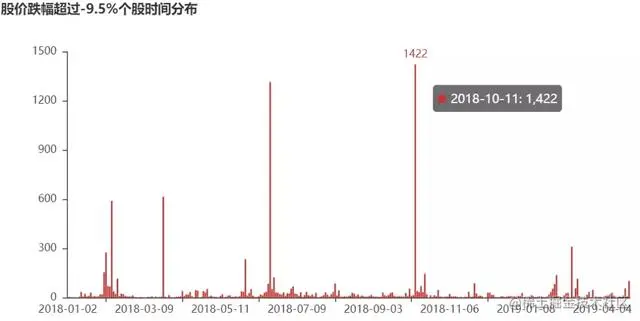
查询股价日跌幅超过-9.5%个股数据分布:
c3=“pct_chg<-9.5”
t3=“股价跌幅超过-9.5%个股时间分布”
plot_data(c3,t3)
复制代码
结合选股策略对数据库进行查询和提取数据:
#筛选代码
#获取当前交易的股票代码和名称
def get_new_code(date):
#获取当前所有交易股票代码
df0 = pro.stock_basic(exchange=‘’, list_status=‘L’)
df1 =pro.daily_basic(trade_date=date)
df=pd.merge(df0,df1,on=‘ts_code’)
#剔除2017年以后上市的新股次新股
df=df[df[‘list_date’].apply(int).values<20170101]
#剔除st股
df=df[-df[‘name’].apply(lambda x:x.startswith(‘*ST’))]
#剔除动态市盈率为负的
df=df[df.pe_ttm>0]
#剔除大市值股票
df=df[df.circ_mv<10**5]
#剔除价格高于20元股票
#df=df[df.close<20]
codes=df.ts_code.values
return codes
len(get_new_code(‘20190425’))
#输出结果:46
import talib as ta
#20日均线交易策略
def find_stock(date):
f_code=[]
for code in get_new_code(date):
try:
data=df_all_data.loc[df_all_data.ts_code==code].copy()
data.index=pd.to_datetime(data.trade_date)
data=data.sort_index()
data[‘ma_20’]=ta.MA(data.close,timeperiod=20)
if data.iloc[-1][‘close’]>data.iloc[-1][‘ma_20’]:
f_code.append(code)
except:
pass
return f_code
fs=find_stock(‘20190305’)
print(f’筛选出的股票个数:{len(fs)}')
if fs:
df_find_stocks=pd.DataFrame(fs,columns=[‘ts_code’])
#将选出的股票存入数据库,如果表已存在,替换掉,相当于每次更新
insert_sql(df_find_stocks,‘find_stocks’,if_exists=‘replace’)
print(‘筛选的股票已入库’)
筛选出的股票个数:9
筛选的股票已入库
#查看数据库中筛选的股票池
codes=pd.read_sql(‘find_stocks’,engine)
codes=codes.values.tolist()
codes=[c[0] for c in codes]
#print(codes)
复制代码
对筛选的股票作进一步分析:
select_data=pd.DataFrame()
for code in codes:
try:
df_= df_all_data[df_all_data.ts_code.values==code]
df_.index=pd.to_datetime(df_.trade_date)
df_=df_.sort_index()
select_data[code]=df_.close
except:
pass
select_data.fillna(method=‘ffill’,inplace=True)
select_data.tail()
ret=select_data.apply(lambda x:x/x.shift(1)-1)
ret=ret.dropna()
ret.tail()
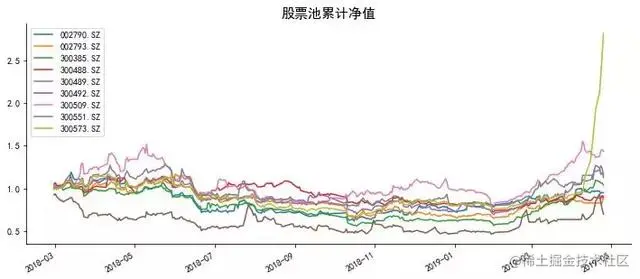
prod_ret=ret.apply(lambda x:(1+x).cumprod())
prod_ret.plot(figsize=(12,5))
plt.xlabel(‘’,fontsize=15)
plt.title(‘股票池累计净值’,size=15)
ax = plt.gca()
ax.spines[‘right’].set_color(‘none’)
ax.spines[‘top’].set_color(‘none’)
plt.show()
复制代码
#根据代码从数据库中获取数据
def get_data_from_sql(code):
from sqlalchemy import create_engine
engine = create_engine(‘postgresql+psycopg2://postgres:123456@localhost:5432/postgres’)
data=pd.read_sql(f"select * from stock_data where ts_code=‘{code}’",engine)
data.index=pd.to_datetime(data.trade_date)
data=data.sort_index()
#计算20日均线
data[‘ma20’]=data.close.rolling(20).mean()
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-ljFyzbQF-1712921780943)]















 4129
4129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









