






1.解决的训练问题:
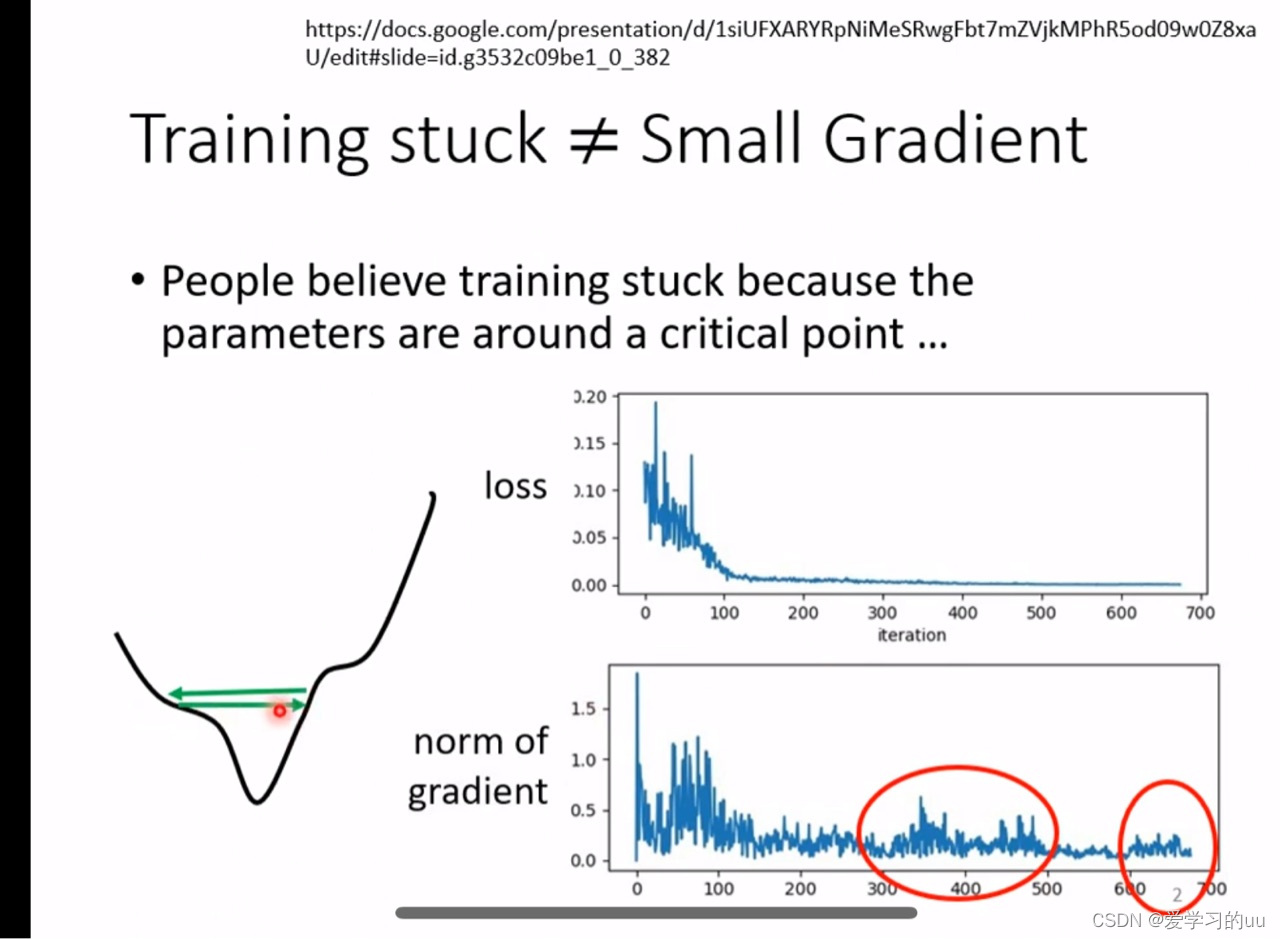
有时损失可能已经不下降了(右上角的图)但实际上并没有到达最优点,原因是如左图所示在两侧山坡上来回(由于这个点梯度较大导致)因此我们需要动态调整步幅(梯度越大学习率越小)

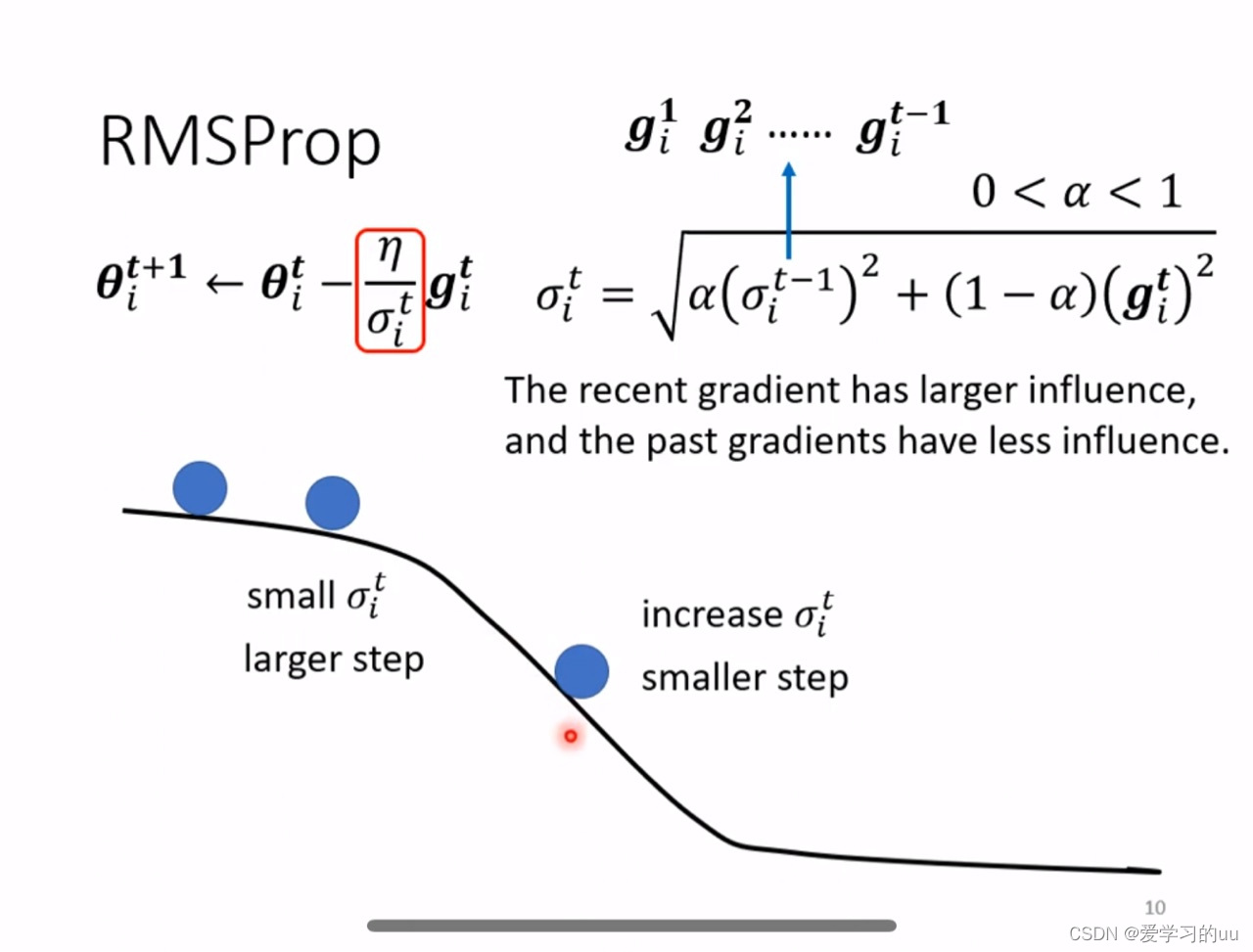
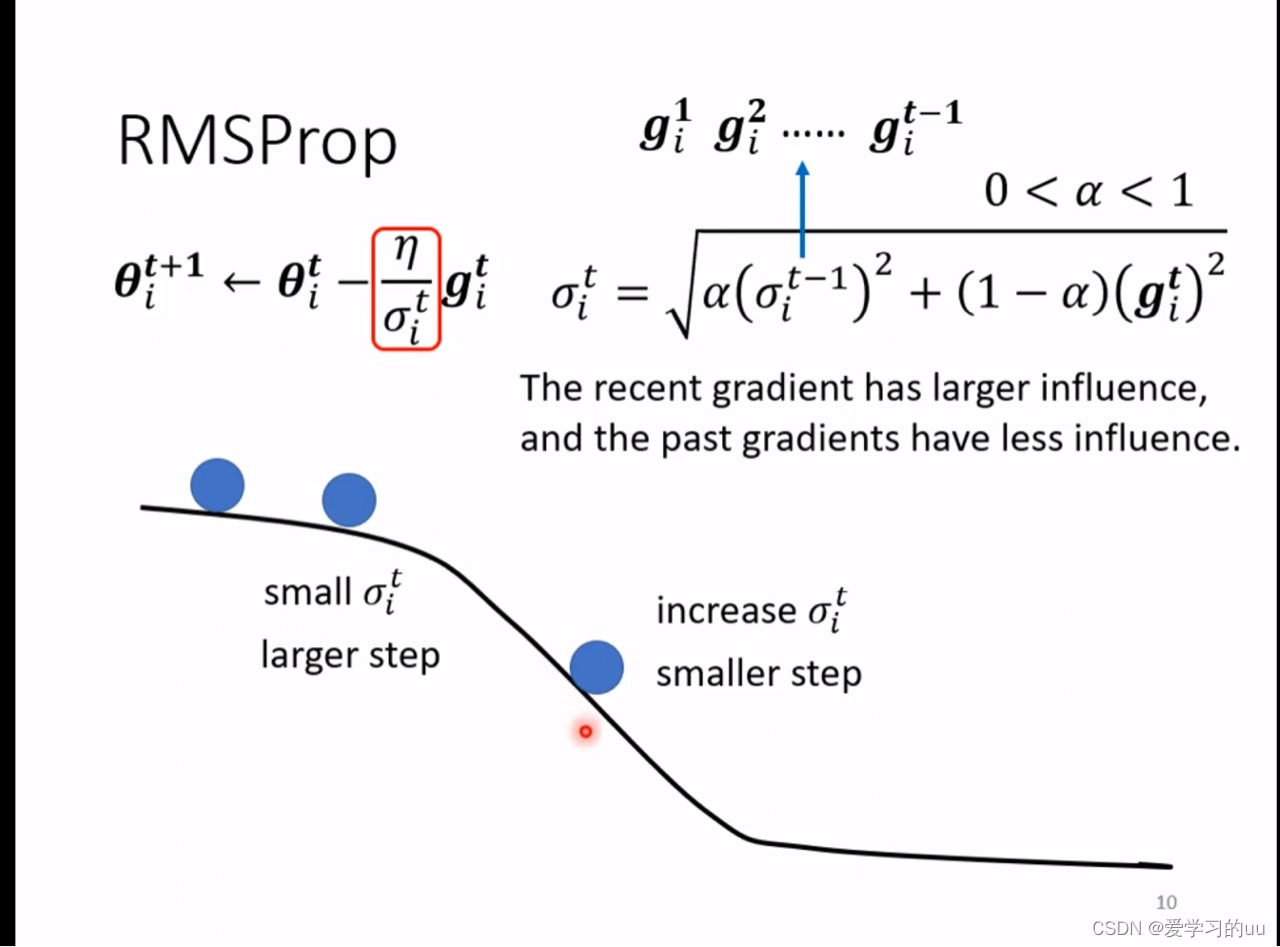
改进1如图所示,原本学习率固定为n,现在随着训练进行,要除所有梯度的平方平均
改进2:希望以前的梯度权重能小一些,得到rmsprop算法
这两个改进导致的值数量变化的大小主要是由所在位置的梯度大小决定的
改进3:这条改进主要针对时间(迭代次数)
针对学习率,随着迭代次数增加,有两种思路:学习率递减或者学习率先增大很减小,如下图
 由此可以得到最终得到的式子如图:
由此可以得到最终得到的式子如图:

注意:之前提到的动量是决定了迭代方向的改变,而本次提到的分母这项是只考虑大小,因此虽然都是由过去的梯度得到,但效果不会抵消














 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









