






为啥叫transformer:这个模型的作用是解决比如文本分类,但每个文本适合被分到的类别数不定,可以让模型来决定要分到几类中(像变形金刚一样)
基本架构:输入-encoder-decoder-输出,整体架构为n个block
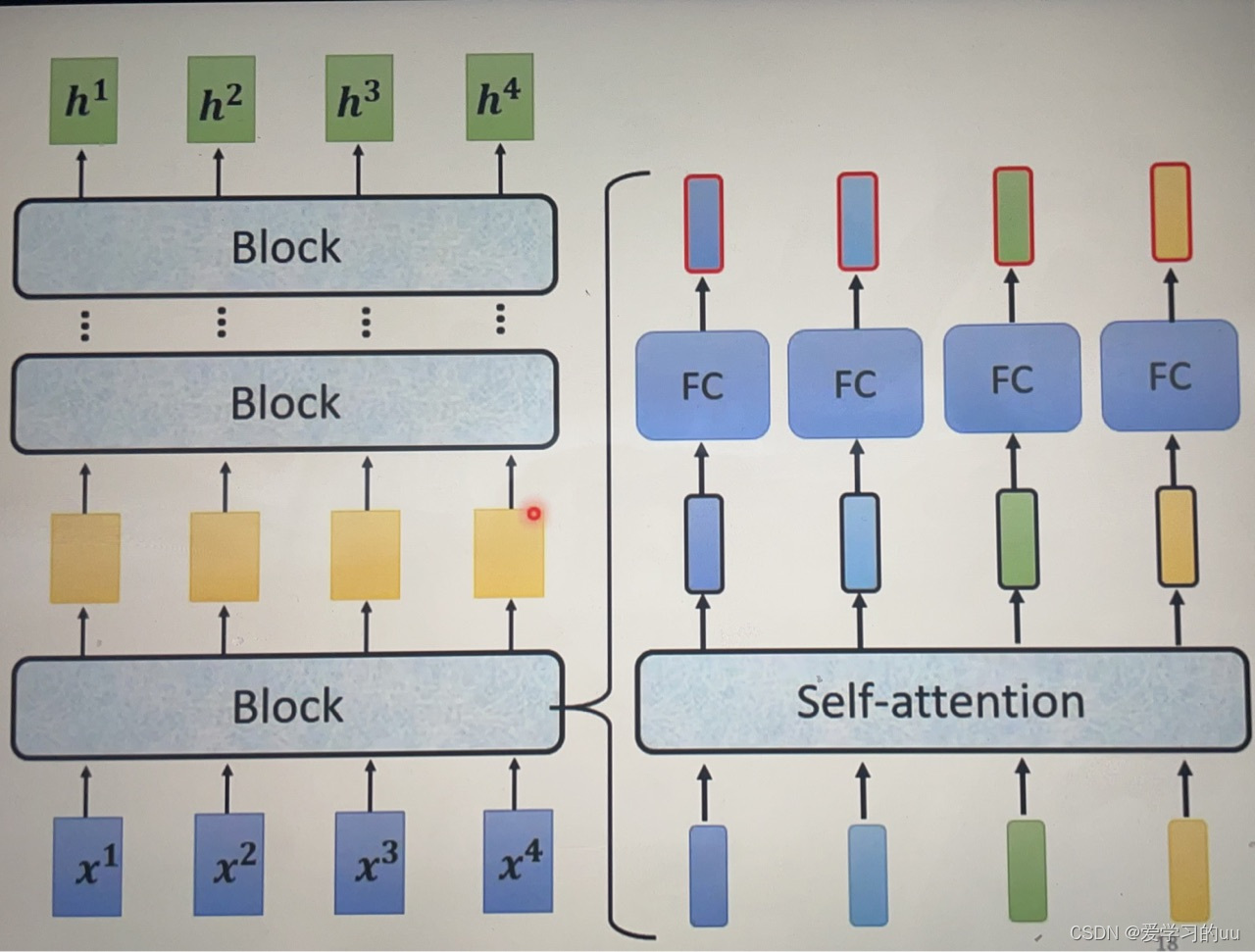
具体细节架构是
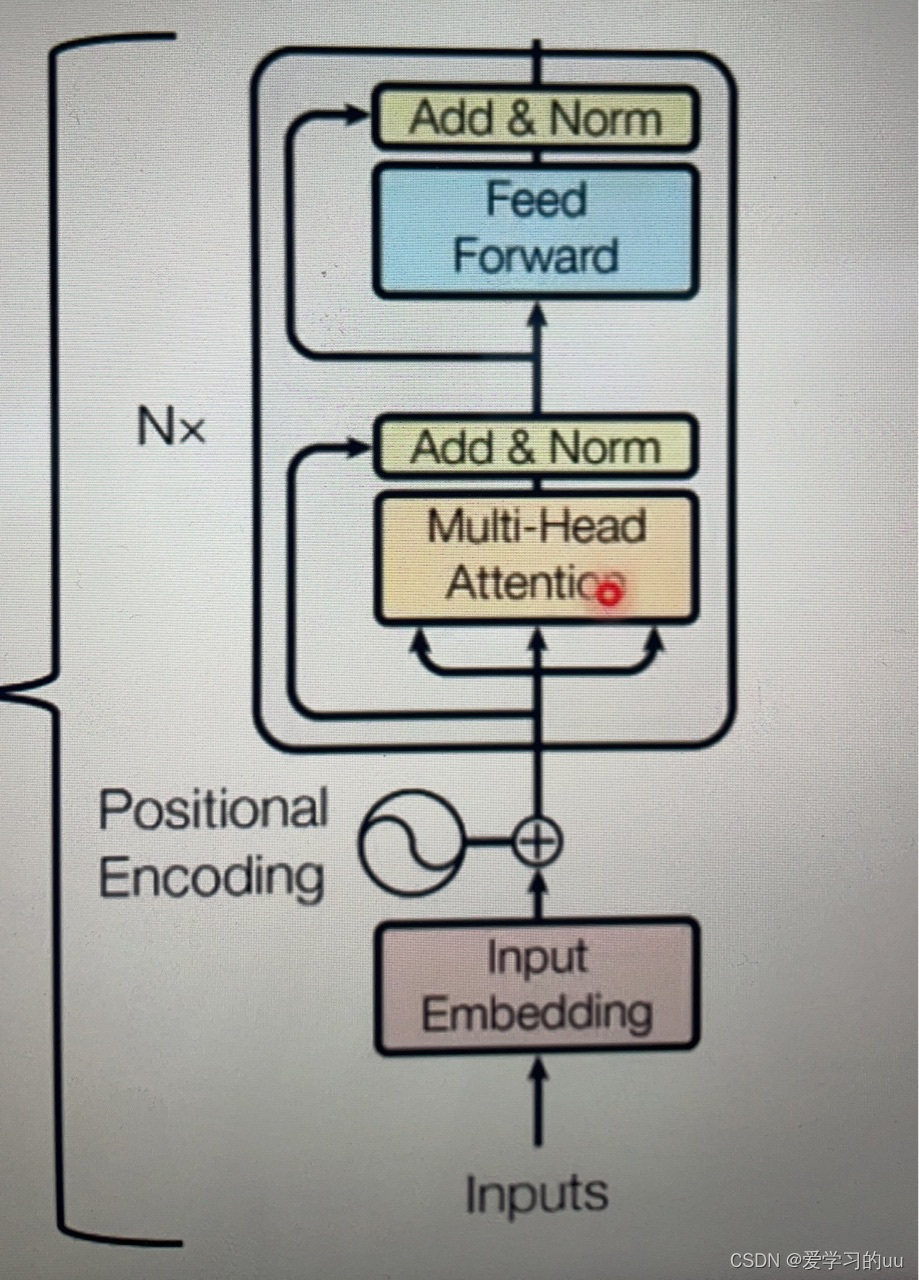
输入-位置编码-多头注意力机制-残差网络+层正则化-feedforward层( 通过线性变换,先将数据映射到高纬度的空间再映射到低纬度的空间,提取了更深层次的特征)
当然,transformer一层不一定要这样设计
decoder:介绍常见的autoregressive形式的decoder
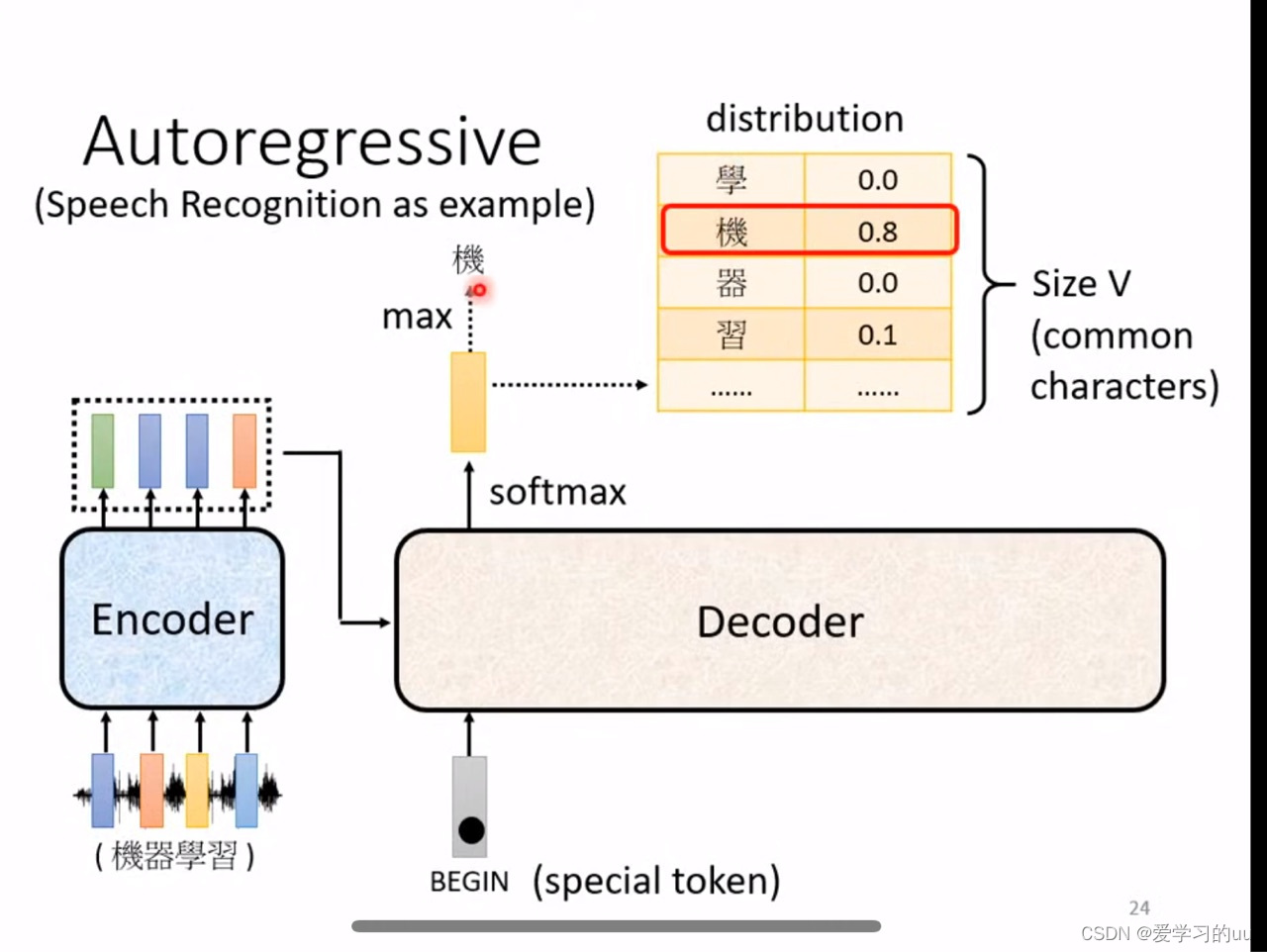
整体结构:把encoder输出读到decoder里面,然后根据一个特殊字符的输入开始,以此输出中文字,每个输出选择概率最大的那个
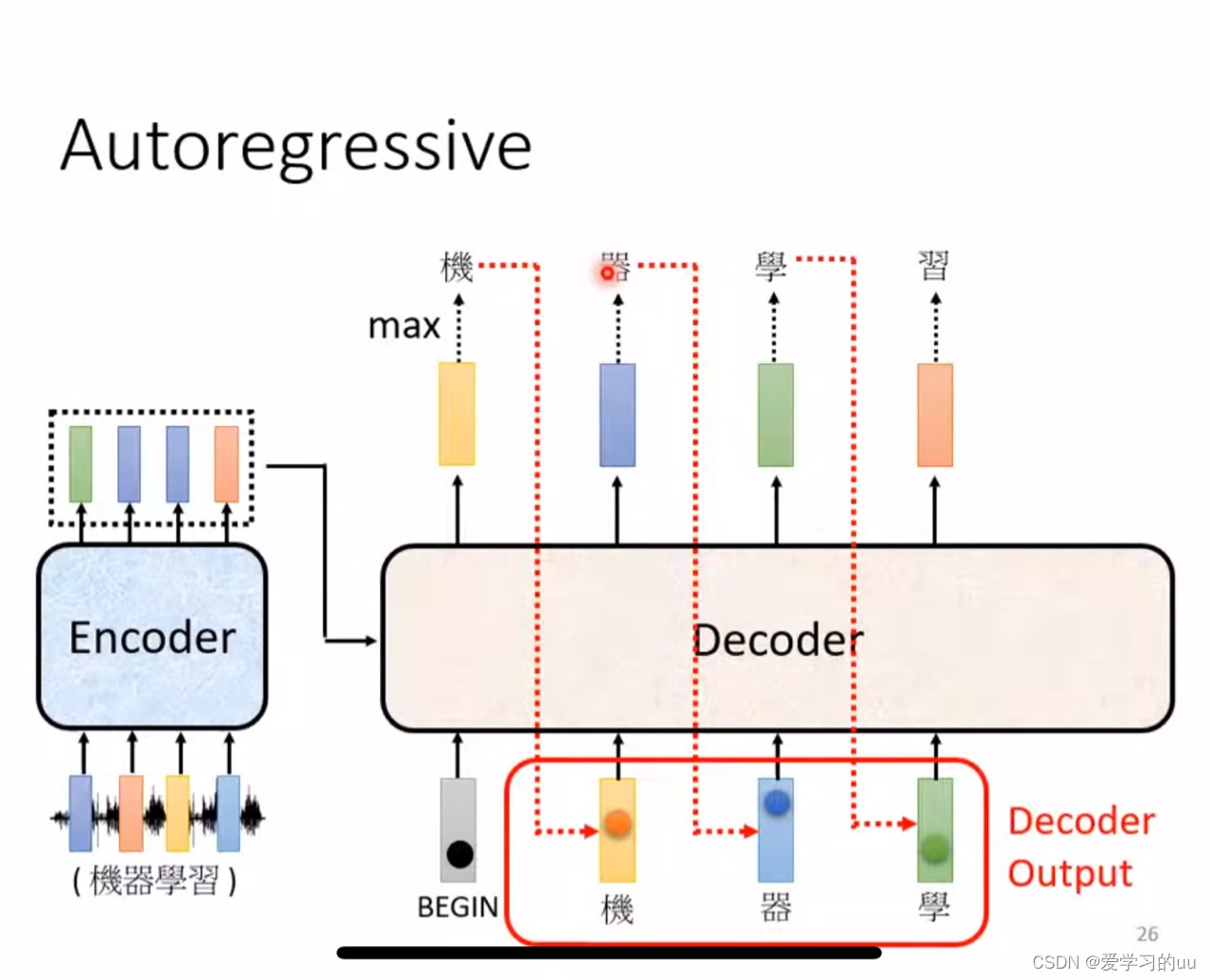
decoder的细节结构:
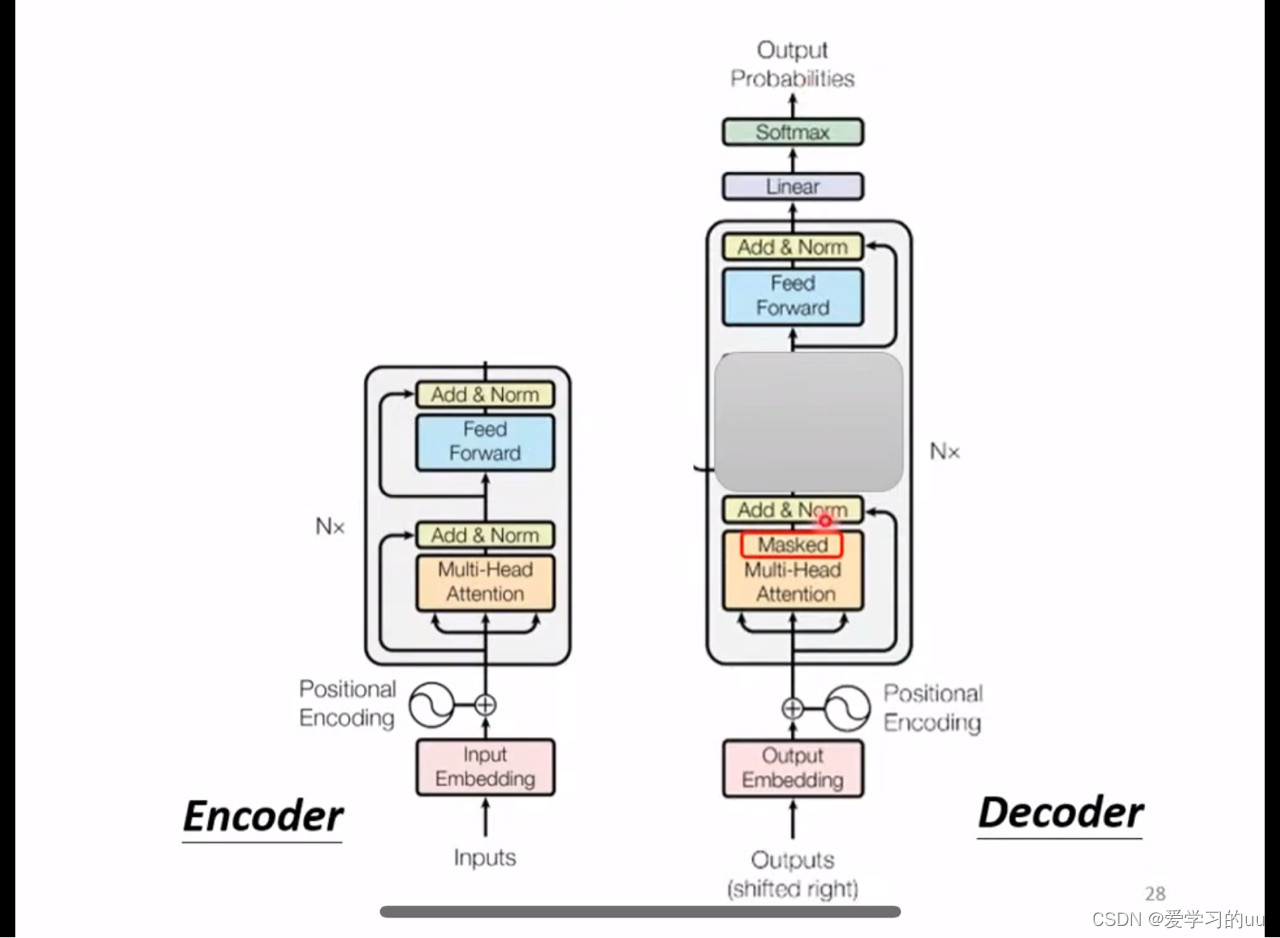
比encoder层多了mask层,具体如下:
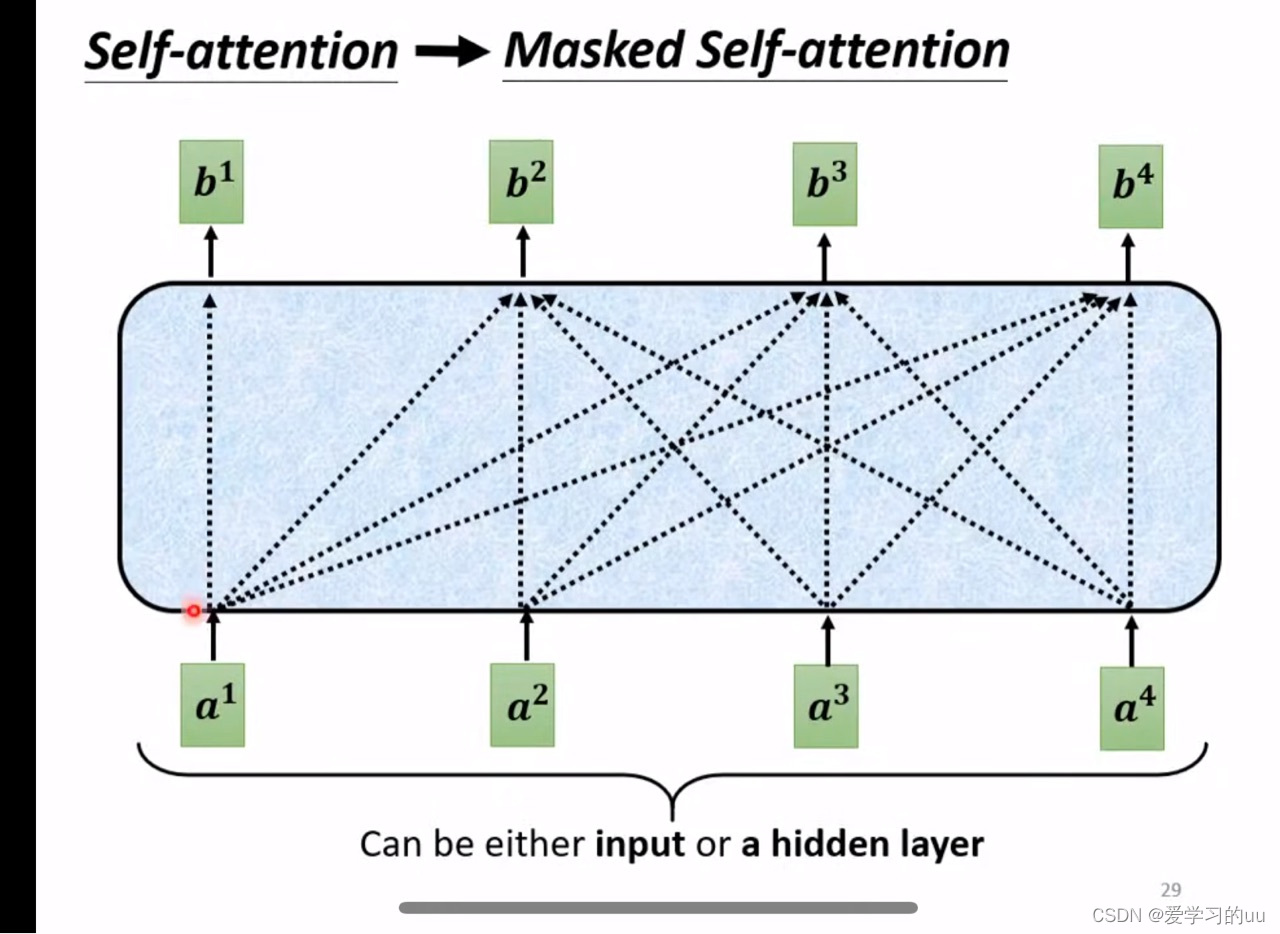
和一般的self attention不同的是,在输出b2时只考虑a1、a2(为了符合decoder的工作原理)
如何决定输出的长度:
在autoregressive中,在可以被输出的中文字符组中加入end,如果某此输出end概率最大,就终止
模型结构讲完再来讲下
auto和not auto的对比:

NAT:同时输入多个begin,并行输出
如何决定长度:两种办法:用另外一个模型训练出输出长度/直接根据输入,输出一个同样长度的输出,然后根据end位置做截断
最后讲下如何训练:
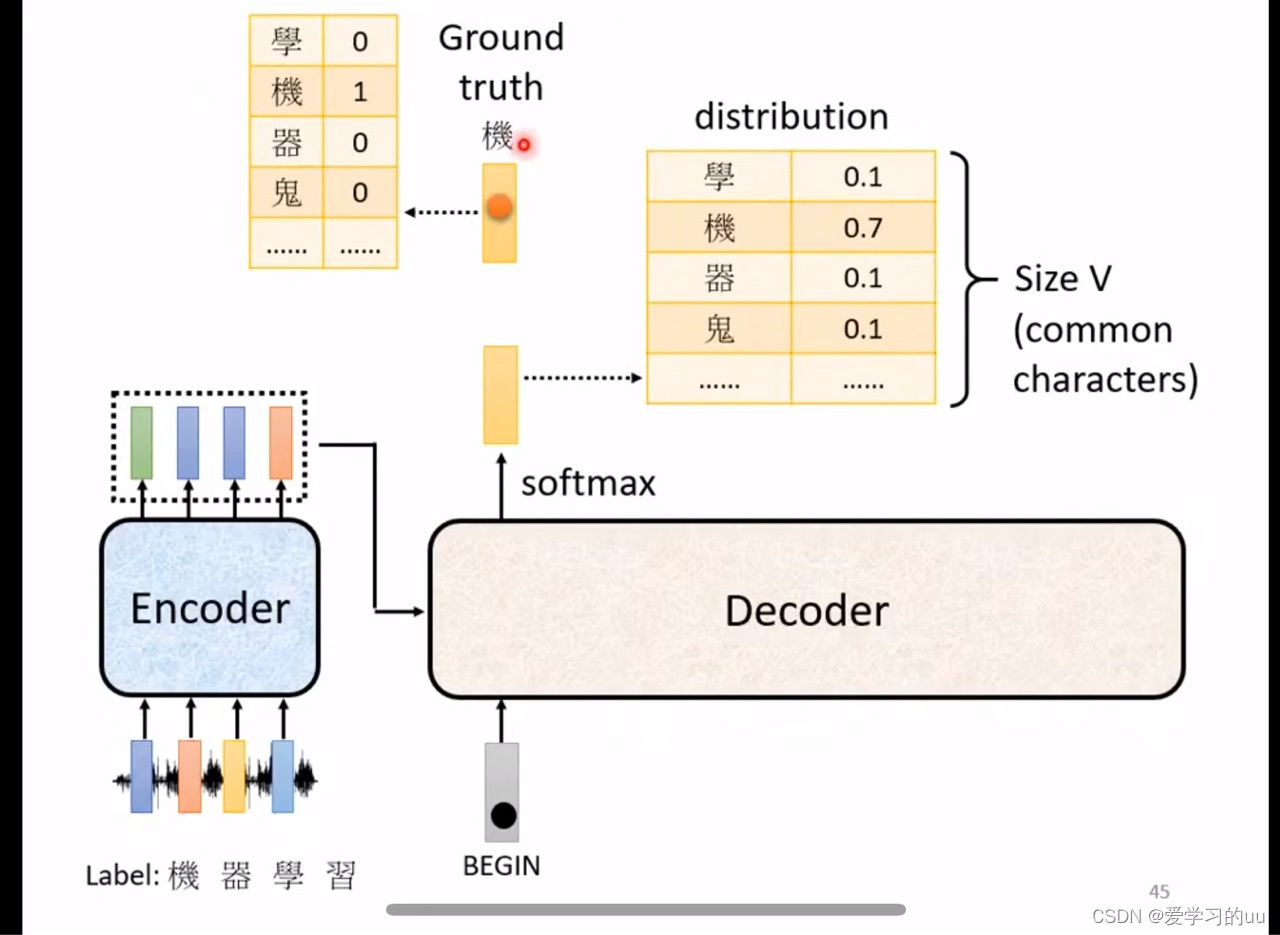
把正确结果的每个字表示为一个one hot编码,和每一位输出单独做交叉熵,目标函数就是每个字的总交叉熵最小(注意把end也算进去)
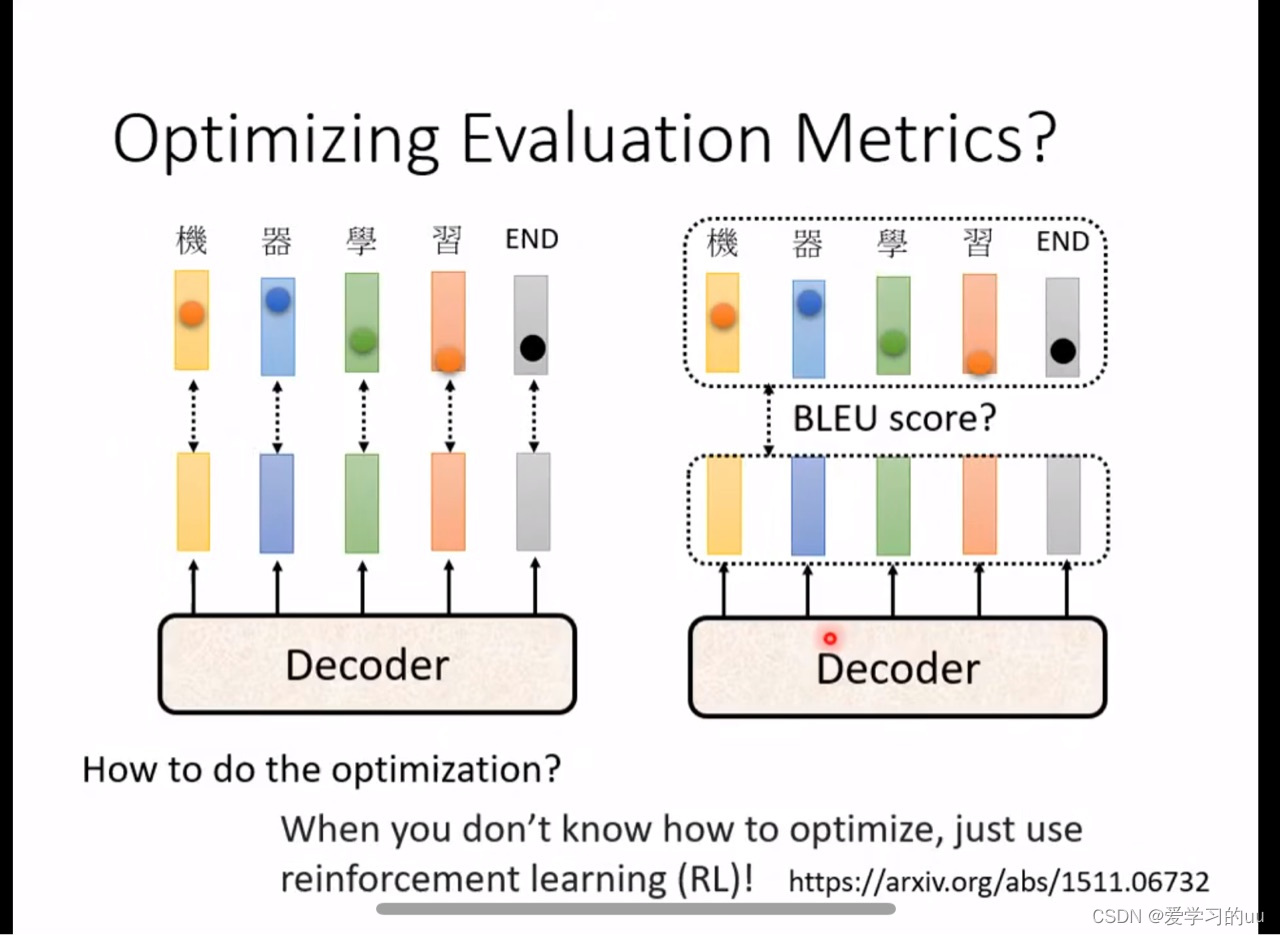
两个tips:
1.训练时采用的是单个字的cross entropy 求和,测试时是算blue score,可能会有偏差,但不能在训练时直接用blue score,因为不能微分(可以用强化学习解决)
2.在训练的时候,每次都是由正确的输入得出输出,但在测试时不是这样,可能导致一步错步步错的情况,解决方法是在训练中就加入一些错误输入














 3842
3842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









