







一.CVRP问题描述
考虑带容量限制的VRP问题,即CVRP。
1.1 假设
配送中心:只有一个配送中心;
配送方式:任何车辆配送货物结束后需要返回配送中心;
车型:只考虑一种车型,且容量约束相同;
需求不可拆分:客户需求只能由一辆车满足,即任一客户需求小于车辆容量;
车辆充足:不限制车辆数量,即配送车辆需求均能满足;
1.2 要求
优化目标:最小化车辆启动成本和车辆行驶成本之和;
约束条件:客户访问约束,容积约束;
已知信息:配送中心位置、客户点位置、客户点需求、车辆最大容积、车辆启动成本、车辆单位距离行驶成本;(数据如有需要请后台私信我)
二.ACO算法介绍
2.1 算法原理
蚁群算法是一种模拟蚂蚁觅食行为的启发式算法,被广泛应用于优化问题的求解。蚁群算法的基本思想:将一群蚂蚁放在问题的解空间上,让它们通过信息素的传递和挥发,逐渐找到最优解。蚂蚁在初始时随机选择一个起点,并向前行走。
当蚂蚁走到一个节点时,它会选择下一个节点进行移动。蚂蚁选择下一个节点的概率与该节点上的信息素浓度成正比。信息素浓度越高的节点,被选择的概率也越高。当蚂蚁移动到一个节点时,它会在路径上释放一定量的信息素。当其他蚂蚁在寻找解的过程中遇到已经被标记的路径时,它们会更有可能选择这条路径。随着时间的推移,信息素会挥发,路径上信息素的浓度会逐渐降低。这样,路径上的信息素浓度会经历一个上升和下降的过程。蚂蚁们会根据路径上的信息素浓度来选择下一个节点。当信息素浓度很高时,它们更有可能选择这条路径。蚂蚁们持续寻找解,直到找到最优解或者达到预设的迭代次数。
2.2 算法流程
- 初始化信息素浓度矩阵τij ,启发式函数ηij,以及蚂蚁的位置。
- 每只蚂蚁按照信息素和启发式函数的概率选择下一个城市。
- 记录蚂蚁的路径和距离。
- 在所有蚂蚁走完所有城市之后,根据蚂蚁走过的路径和距离更新信息素浓度矩阵。
- 如果未达到停止条件,则返回步骤2。
- 其中,停止条件可以是迭代次数达到预设值或者最佳解不再改变。
蚂蚁选择下一个城市的概率依靠以下公式:
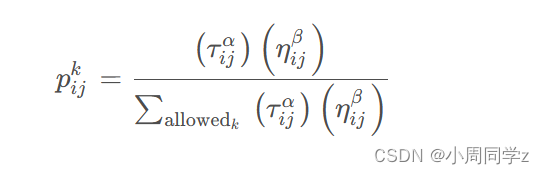
信息素更新如下:
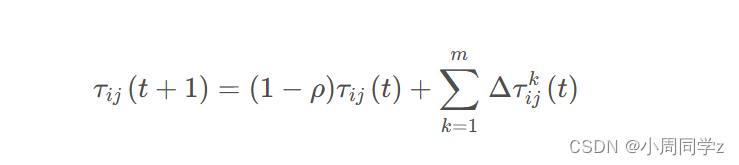
Δτijk(t) = Q/Lk(t) ,其中Q为常量,Lk(t)是蚂蚁k在迭代t中走过的路径长度。
三.Python求解代码
import pandas as pd
import math
import random
import numpy as np
import copy
import xlsxwriter
import matplotlib.pyplot as plt
# 数据结构:解
class Sol():
def __init__(self):
self.nodes_seq=None # 解的编码
self.obj=None # 目标函数
self.routes=None # 解的解码
# 数据结构:网络节点
class Node():
def __init__(self):
self.id=0 # 节点id
self.name='' # 节点名称,可选
self.seq_no=0 # 节点映射id
self.x_coord=0 # 节点平面横坐标
self.y_coord=0 # 节点平面纵坐标
self.demand=0 # 节点需求
# 数据结构:全局参数
class Model():
def __init__(self):
self.best_sol=None # 全局最优解
self.node_list=[] # 需求节点集合
self.sol_list=[] # 解的集合
self.node_seq_no_list=[] #需求节点映射id集合
self.depot=None # 车场节点
self.number_of_nodes=0 # 需求节点数量
self.opt_type=0 # 优化目标类型
self.vehicle_cap=0 # 车辆最大容量
self.distance={} # 节点距离矩阵
self.popsize=100 # 种群规模
self.alpha=2 # 信息启发式因子
self.beta=3 # 期望启发式因子
self.Q=100 # 信息素总量
self.rho=0.5 # 信息素挥发因子
self.tau={} # 弧信息素集合
def readXlsxFile(filepath,model):
# 建议在xlsx文件中,第一行为表头,其中: x_coord,y_coord,demand是必须项;车辆基地数据放在表头下首行
node_seq_no = -1 #需求节点的seq_no 依次编号为 0,1,2,...
df = pd.read_excel(filepath)
for i in range(df.shape[0]):
node=Node()
node.seq_no=node_seq_no
node.x_coord= df['x_coord'][i]
node.y_coord= df['y_coord'][i]
node.demand=df['demand'][i]
if df['demand'][i] == 0:
model.depot=node
else:
model.node_list.append(node)
model.node_seq_no_list.append(node_seq_no)
try:
node.name=df['name'][i]
except:
pass
try:
node.id=df['id'][i]
except:
pass
node_seq_no=node_seq_no+1
model.number_of_nodes=len(model.node_list)
# 初始化参数
def initParam(model):
for i in range(model.number_of_nodes):
for j in range(i+1,model.number_of_nodes):
d=math.sqrt((model.node_list[i].x_coord-model.node_list[j].x_coord)**2+
(model.node_list[i].y_coord-model.node_list[j].y_coord)**2)
model.distance[i,j]=d
model.distance[j,i]=d
model.tau[i,j]=10
model.tau[j,i]=10
# 蚂蚁移动
def movePosition(model):
sol_list=[]
local_sol=Sol()
local_sol.obj=float('inf')
for k in range(model.popsize):
#随机初始化蚂蚁为止
nodes_seq=[int(random.randint(0,model.number_of_nodes-1))]
all_nodes_seq=copy.deepcopy(model.node_seq_no_list)
all_nodes_seq.remove(nodes_seq[-1])
#确定下一个访问节点
while len(all_nodes_seq)>0:
next_node_no=searchNextNode(model,nodes_seq[-1],all_nodes_seq)
nodes_seq.append(next_node_no)
all_nodes_seq.remove(next_node_no)
sol=Sol()
sol.nodes_seq=nodes_seq
sol.obj,sol.routes=calObj(nodes_seq,model)
sol_list.append(sol)
if sol.obj<local_sol.obj:
local_sol=copy.deepcopy(sol)
model.sol_list=copy.deepcopy(sol_list)
if local_sol.obj<model.best_sol.obj:
model.best_sol=copy.deepcopy(local_sol)
# 搜索下一移动节点
def searchNextNode(model,current_node_no,SE_List):
prob=np.zeros(len(SE_List))
for i,node_no in enumerate(SE_List):
eta=1/model.distance[current_node_no,node_no]
tau=model.tau[current_node_no,node_no]
prob[i]=((eta**model.alpha)*(tau**model.beta))
#采用轮盘法选择下一个访问节点
cumsumprob=(prob/sum(prob)).cumsum()
cumsumprob -= np.random.rand()
next_node_no= SE_List[list(cumsumprob > 0).index(True)]
return next_node_no
# 更新路径信息素
def upateTau(model):
rho=model.rho
for k in model.tau.keys():
model.tau[k]=(1-rho)*model.tau[k]
#根据解的nodes_seq属性更新路径信息素(TSP问题的解)
for sol in model.sol_list:
nodes_seq=sol.nodes_seq
for i in range(len(nodes_seq)-1):
from_node_no=nodes_seq[i]
to_node_no=nodes_seq[i+1]
model.tau[from_node_no,to_node_no]+=model.Q/sol.obj
# 采用Split思想对TSP序列进行切割,得到可行车辆路径
def splitRoutes(nodes_seq,model):
"""
采用简单的分割方法:按顺序依次检查路径的容量约束,在超出车辆容量限制的位置插入车场。
例如某TSP解为:[1,2,3,4,5,6,7,8,9,10],累计需求为:[10,20,30,40,50,60,70,80,90,10],车辆容量为:30,则应在3,6,9节点后插入车场,
即得到:[0,1,2,3,0,4,5,6,0,7,8,9,0,10,0]
"""
num_vehicle = 0
vehicle_routes = []
route = []
remained_cap = model.vehicle_cap
for node_no in nodes_seq:
if remained_cap - model.node_list[node_no].demand >= 0:
route.append(node_no)
remained_cap = remained_cap - model.node_list[node_no].demand
else:
vehicle_routes.append(route)
route = [node_no]
num_vehicle = num_vehicle + 1
remained_cap =model.vehicle_cap - model.node_list[node_no].demand
vehicle_routes.append(route)
return num_vehicle,vehicle_routes
# 计算路径总行驶距离
def calDistance(route,model):
distance=0
depot=model.depot
for i in range(len(route)-1):
from_node=model.node_list[route[i]]
to_node=model.node_list[route[i+1]]
distance+=math.sqrt((from_node.x_coord-to_node.x_coord)**2+(from_node.y_coord-to_node.y_coord)**2)
first_node=model.node_list[route[0]]
last_node=model.node_list[route[-1]]
distance+=math.sqrt((depot.x_coord-first_node.x_coord)**2+(depot.y_coord-first_node.y_coord)**2)
distance+=math.sqrt((depot.x_coord-last_node.x_coord)**2+(depot.y_coord - last_node.y_coord)**2)
return distance
# 计算目标函数
def calObj(nodes_seq,model):
num_vehicle, vehicle_routes = splitRoutes(nodes_seq, model)
if model.opt_type==0:
return num_vehicle,vehicle_routes
else:
distance=0
for route in vehicle_routes:
distance+=calDistance(route,model)
return distance,vehicle_routes
# 绘制目标函数收敛曲线
def plotObj(obj_list):
plt.rcParams['font.sans-serif'] = ['SimHei'] #显示中文
plt.rcParams['axes.unicode_minus'] = False #显示正负号
plt.plot(np.arange(1,len(obj_list)+1),obj_list)
plt.xlabel('Iterations')
plt.ylabel('Obj Value')
plt.grid()
plt.xlim(1,len(obj_list)+1)
plt.show()
# 绘制优化车辆路径
def plotRoutes(model):
for route in model.best_sol.routes:
x_coord=[model.depot.x_coord]
y_coord=[model.depot.y_coord]
for node_no in route:
x_coord.append(model.node_list[node_no].x_coord)
y_coord.append(model.node_list[node_no].y_coord)
x_coord.append(model.depot.x_coord)
y_coord.append(model.depot.y_coord)
plt.plot(x_coord,y_coord,marker='s',color='b',linewidth=0.5)
plt.show()
# 输出优化结果
def outPut(model):
work=xlsxwriter.Workbook('result.xlsx')
worksheet=work.add_worksheet()
worksheet.write(0,0,'opt_type')
worksheet.write(1,0,'obj')
if model.opt_type==0:
worksheet.write(0,1,'number of vehicles')
else:
worksheet.write(0, 1, 'drive distance of vehicles')
worksheet.write(1,1,model.best_sol.obj)
for row,route in enumerate(model.best_sol.routes):
route.insert(0, model.depot.id)
route.append(model.depot.id)
worksheet.write(row+2,0,'v'+str(row+1))
r=[str(i)for i in route]
worksheet.write(row+2,1, '-'.join(r))
work.close()
# 主程序
def run(filepath,Q,alpha,beta,rho,epochs,v_cap,opt_type,popsize):
"""
:param filepath:Xlsx文件路径
:param Q:信息素总量
:param alpha:信息启发式因子
:param beta:期望启发式因子
:param rho:信息挥发因子
:param epochs:迭代次数
:param v_cap:车辆容量
:param opt_type:优化类型:0:最小化车辆数,1:最小化行驶距离
:param popsize:蚁群规模
:return:
"""
model=Model()
model.vehicle_cap=v_cap
model.opt_type=opt_type
model.alpha=alpha
model.beta=beta
model.Q=Q
model.rho=rho
model.popsize=popsize
sol=Sol()
sol.obj=float('inf')
model.best_sol=sol
history_best_obj = []
readXlsxFile(filepath,model)
initParam(model)
for ep in range(epochs):
movePosition(model)
upateTau(model)
history_best_obj.append(model.best_sol.obj)
print("%s/%s, best obj: %s" % (ep,epochs, model.best_sol.obj))
plotObj(history_best_obj)
plotRoutes(model)
outPut(model)
if __name__=='__main__':
file = 'filepath'
run(filepath=file,Q=10,alpha=1,beta=5,rho=0.1,epochs=300,v_cap=80,opt_type=1,popsize=60)
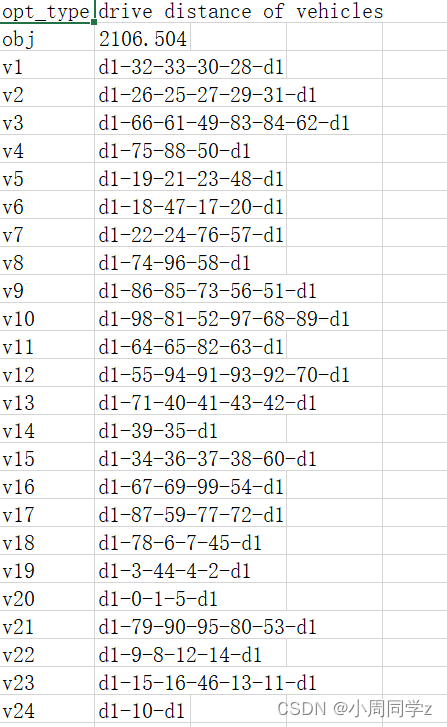
输出结果
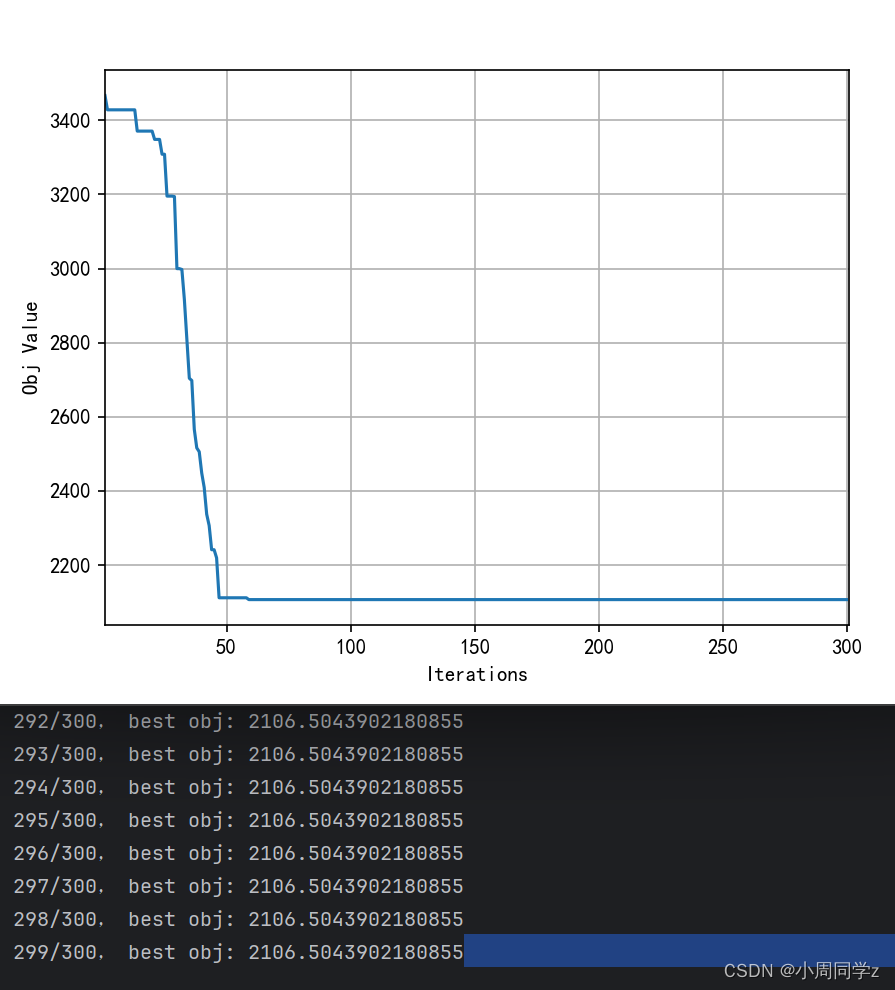
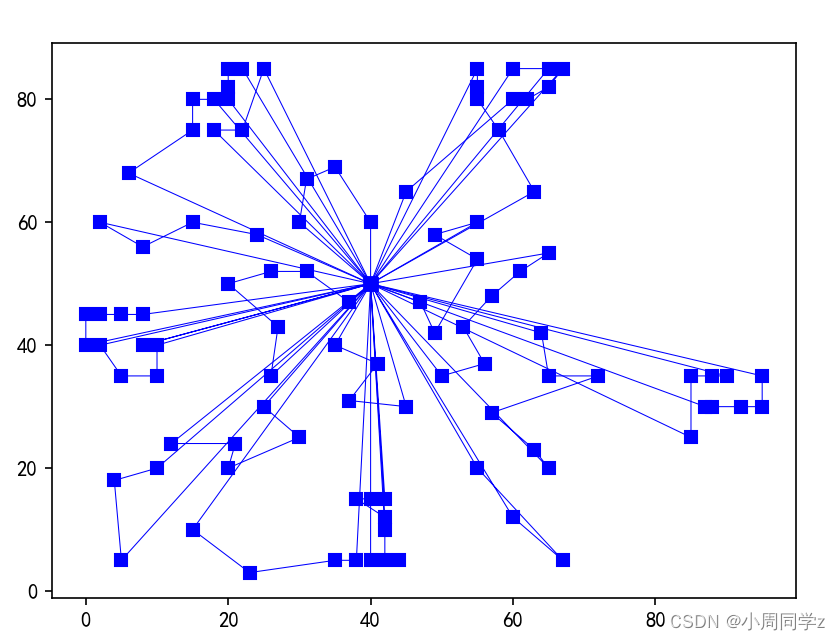















 1437
1437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









