







站点间共享单车出行时间序列分析
出行时间预测是城市智能交通系统的重要组成部分,同时也是交通规划和管理的重要支撑。我们这里对站点间共享单车出行进行了时间序列分析,数据来源于加拿大多伦多7183-7399节点的共享单车出行数据(如有需要后台私信我获取),其中Duration Time为骑行时间。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from matplotlib.font_manager import FontProperties
font_set= FontProperties(fname=r"c:\windows\fonts\simkai.ttf",size=16)
Step0.读取数据,并检查缺失值
riding_time = pd.read_excel('excelfile')
date,time = riding_time['Start Time'], riding_time['Trip Duration']
print(time.describe())
print(time.info())

数据完整,直接进行序列分析。
Step1.画出时序图
fig_mile_ts = plt.figure(figsize=(12.75, 2.75))
plt.plot(date,time, '*-')
plt.xlabel(u'时间',fontproperties=font_set)
plt.ylabel(u'出行时间',fontproperties=font_set)
plt.show()
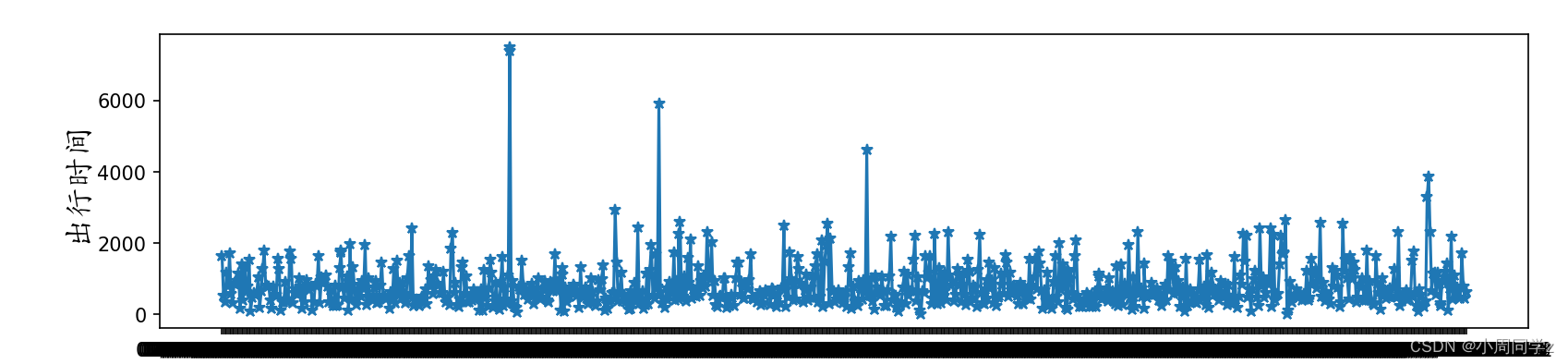
Step2.平稳性检验和纯随机性检验
2.1 自相关图检验
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
fig_mile_acf = plot_acf(time, lags=20)
fig_mile_acf.set_size_inches(12.75, 2.75)
plt.xlim(-0.1, 20.1)
plt.show()
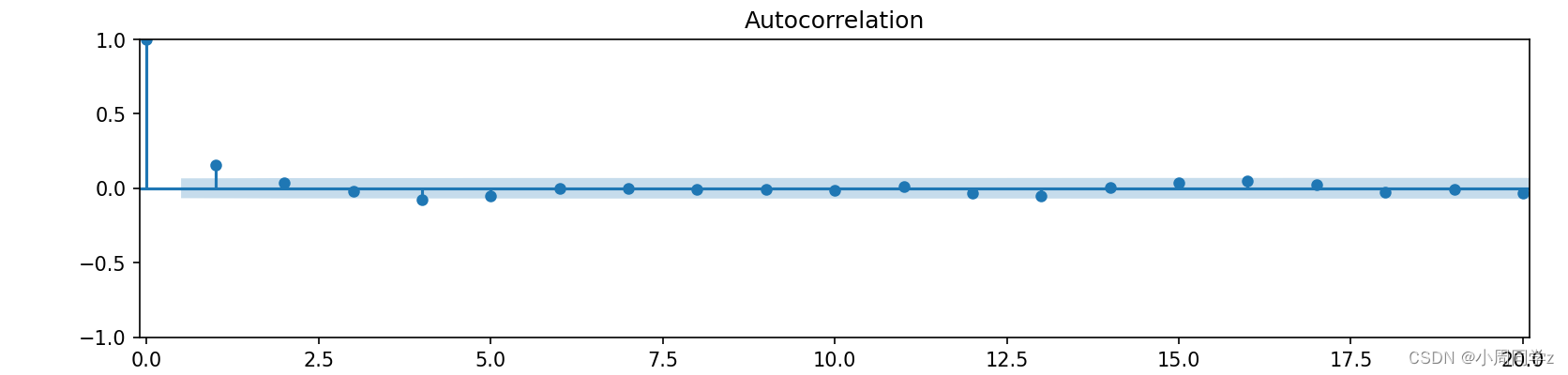
自相关系数很快衰减为接近于0,说明该时间序列具有短期相关性,是平稳时间序列。
2.2 adf检验
import statsmodels.api as sm
print(sm.tsa.stattools.adfuller(time))
![]()
1%、%5、%10不同程度拒绝原假设的统计值和ADF比较,ADF同时小于1%、5%、10%。即说明非常好地拒绝该假设。本数据中,adf值结果为-25.06, 小于三个level的统计值,说明数据是平稳的。
2.3纯随机性检验,QLB统计量
from statsmodels.stats.diagnostic import acorr_ljungbox
df = acorr_ljungbox(time, boxpierce=True, lags = 10, return_df=True)
fig_mile_qlb = plt.figure(figsize=(12.75, 2.75))
plt.plot(df.lb_pvalue, '-o', label='qlb_pval')
plt.xlabel(u'延迟阶数',fontproperties=font_set)
plt.ylabel(u'p值',fontproperties=font_set)
plt.xlim(1, 10)
plt.show()
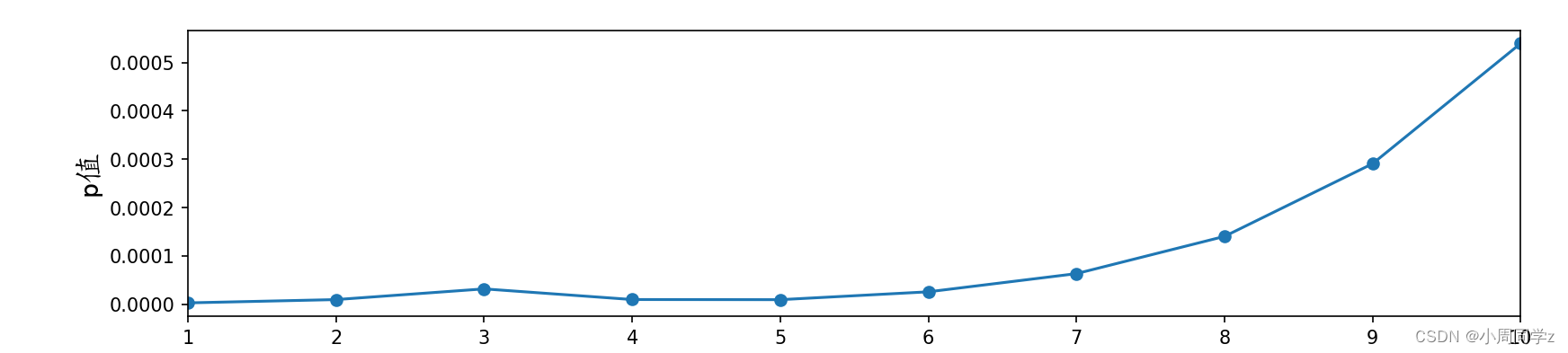
拒绝原假设,为非纯随机序列。
Step.3模型初步定阶
3.1 画出PACF图
fig_yields_pacf = plot_pacf(time, lags=20)
fig_yields_pacf.set_size_inches(12.75, 2.75)
plt.xlim(-0.1, 20.1)
plt.show()

3.2 自动寻优函数定阶
与ACF图结合判断模型阶数,但人工定阶不确定性风险较大,存在模型优化的可能。因此,我们使用自动寻优函数定阶,结果如下:
from pmdarima import auto_arima
model = auto_arima(time, trace=True, error_action='ignore', suppress_warnings=True)
model.fit(time)
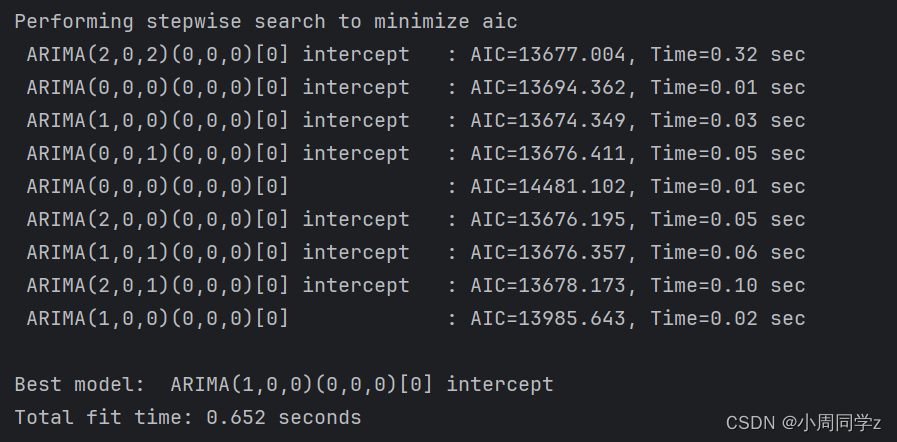
最终确定的模型为ARMA(1,0)。
Step4.参数估计
4.1 拟合参数
import statsmodels.api as sm
time_arma = sm.tsa.ARIMA(time, order=(1,0,0)).fit()# 拟合模型
time_residual = time - time_arma.predict().values # 残差
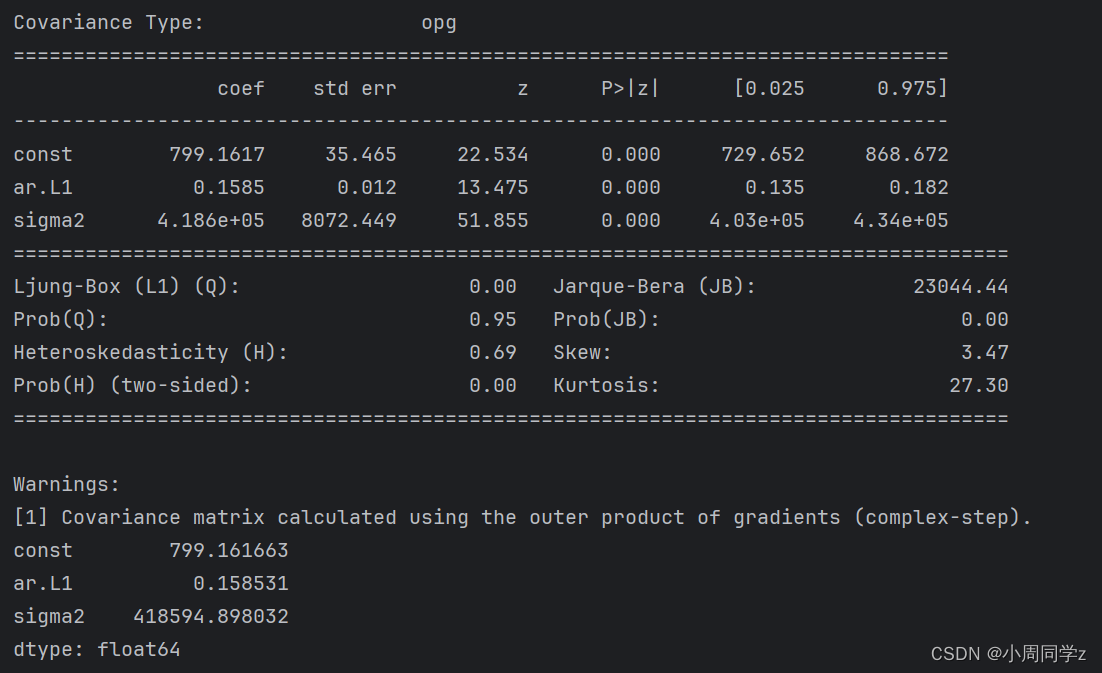
print(time_arma.summary())
print(time_arma.params) # 拟合参数
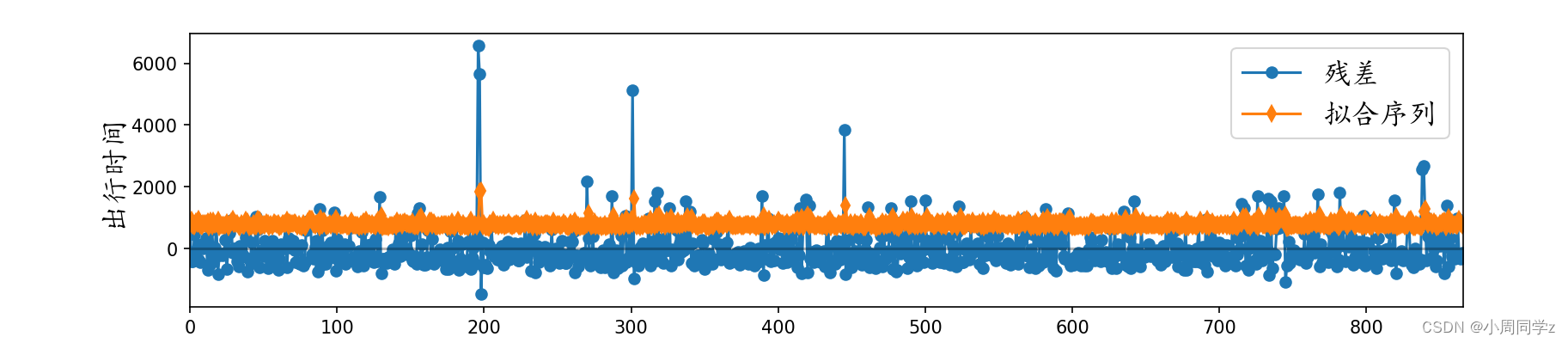
4.2画出拟合残差时序图
fig_time_res_ts = plt.figure(figsize=(12.75, 2.75))
plt.plot(time_residual, '-o', label=u'残差')
plt.xlabel(u'时间',fontproperties=font_set)
plt.ylabel(u'出行时间',fontproperties=font_set)
plt.plot(np.zeros(len(time)), alpha = 0.3, color = 'black')
plt.plot(time_arma.predict().values, '-d', label=u'拟合序列')
plt.legend(prop = font_set)
plt.xlim([0, len(time)])
plt.show()
Step5.模型优化
5.1 模型显著性检验
df = acorr_ljungbox(time_residual, boxpierce=False, lags = 20, return_df=True)
fig_time_qlb = plt.figure(figsize=(12.75, 2.75))
plt.plot(df.lb_pvalue, '-o', label='qlb_pval')
plt.xlabel(u'延迟阶数',fontproperties=font_set)
plt.ylabel(u'p值',fontproperties=font_set)
plt.xlim(1, 20)
plt.show()
print(df.lb_pvalue[[6,12,18]])
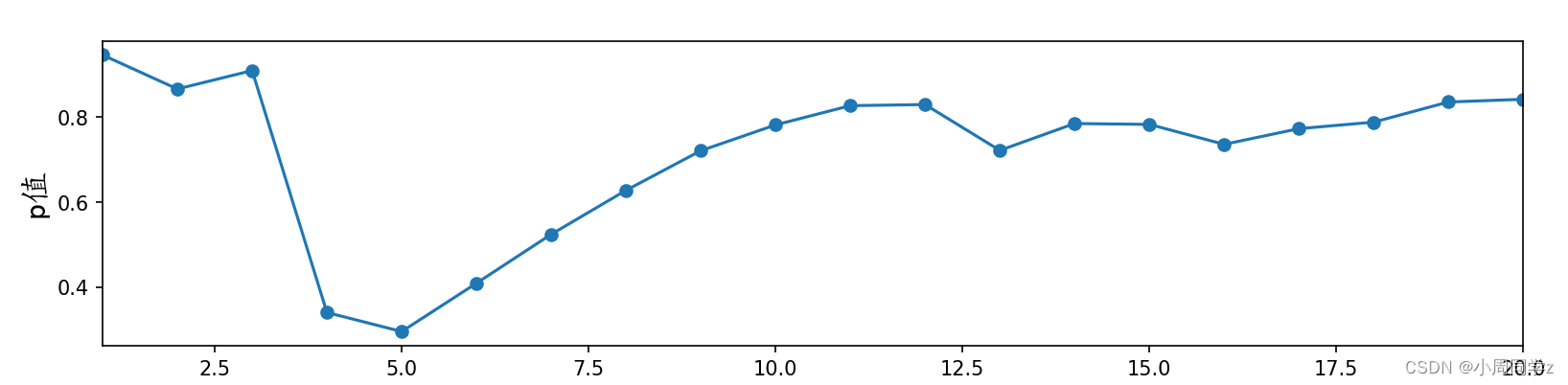
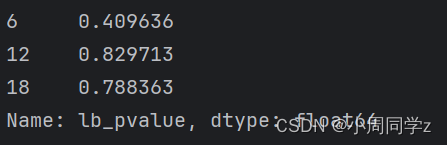
P值大通过纯随机性检验,模型较为显著。
5.2 参数显著性检验
print(time_arma.tvalues)
print(time_arma.pvalues)
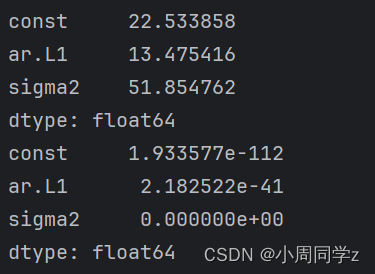
显著拒绝原假设(参数显著为0),参数较为显著。
Step6.模型预测
基于最优预测原理,预测未来三次骑行时长:
ut_insample = time -time_arma.params.values[0]
#print(ut_insample)
time_forecast = np.zeros(3)
time_forecast[0] = time_arma.params.values[0] +\
time_arma.params.values[1] * ut_insample[865]
time_forecast[1] = time_arma.params.values[0] + \
time_arma.params.values[1] * (time_forecast[0]- time_arma.params.values[0])
time_forecast[2] = time_arma.params.values[0] + \
time_arma.params.values[1] * (time_forecast[1]- time_arma.params.values[0])
print(time_forecast)
![]()
预测未来十次骑行时长,并绘制出预测值和真实值之间的拟合图:
predict=time_arma.predict(0,len(time)+10)
plt.plot(date,time)
plt.plot(predict)
plt.legend(['y_true','y_pred'])
plt.show()
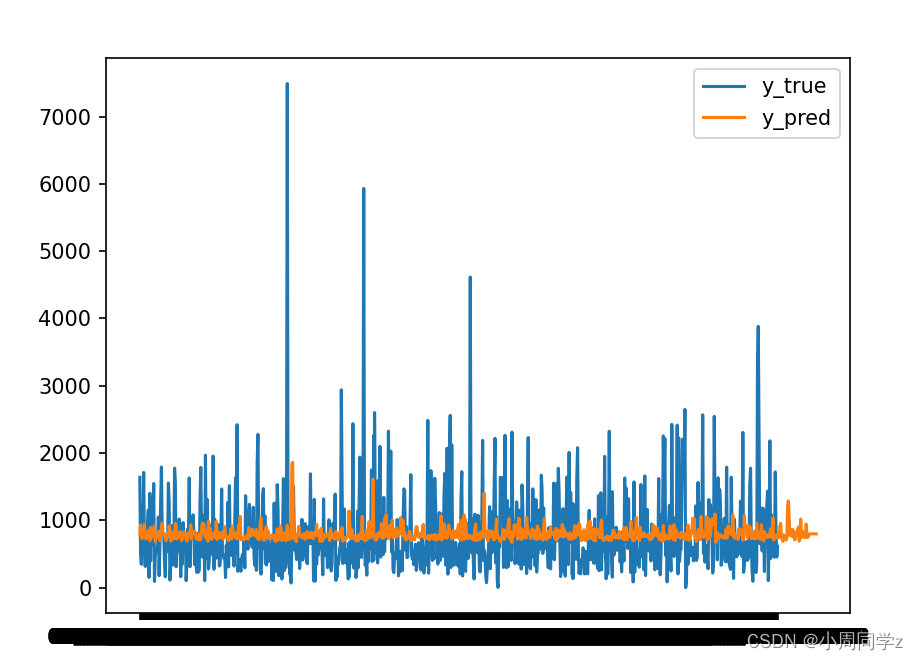
与实际数据较为吻合,但仍然存在数据偏差,观察到原序列数据时序图波动较大,可能存在异方差问题。另外读者也可以尝试做差分,可能拟合效果会更好~
好了,书接上回,我们对异方差问题尝试做处理。
首先,对残差进行BP检验
import statsmodels.formula.api as smf
riding_time['resid_sq'] = time_residual ** 2 #定义残差的平方
reg_resid = smf.ols(formula='resid_sq ~ date', data=riding_time)
results_resid = reg_resid.fit()
bp_F_statistic = results_resid.fvalue
bp_F_pval = results_resid.f_pvalue
print(f'bp检验的F统计量: {bp_F_statistic}')
print(f'bp检验的F统计量对应的p值: {bp_F_pval}')结果如下:
 P值小于0.05,拒绝原假设,存在异方差性。
P值小于0.05,拒绝原假设,存在异方差性。
对残差序列绘制自相关图和偏自相关图
plt.rcParams.update({'figure.figsize':(9,3),'figure.dpi':120})
fig, axes = plt.subplots(1,2)
plot_acf(time_residual ** 2, lags=40, ax=axes[0])
plot_pacf(time_residual ** 2, lags = 40, ax = axes[1],method='ywm')
plt.show()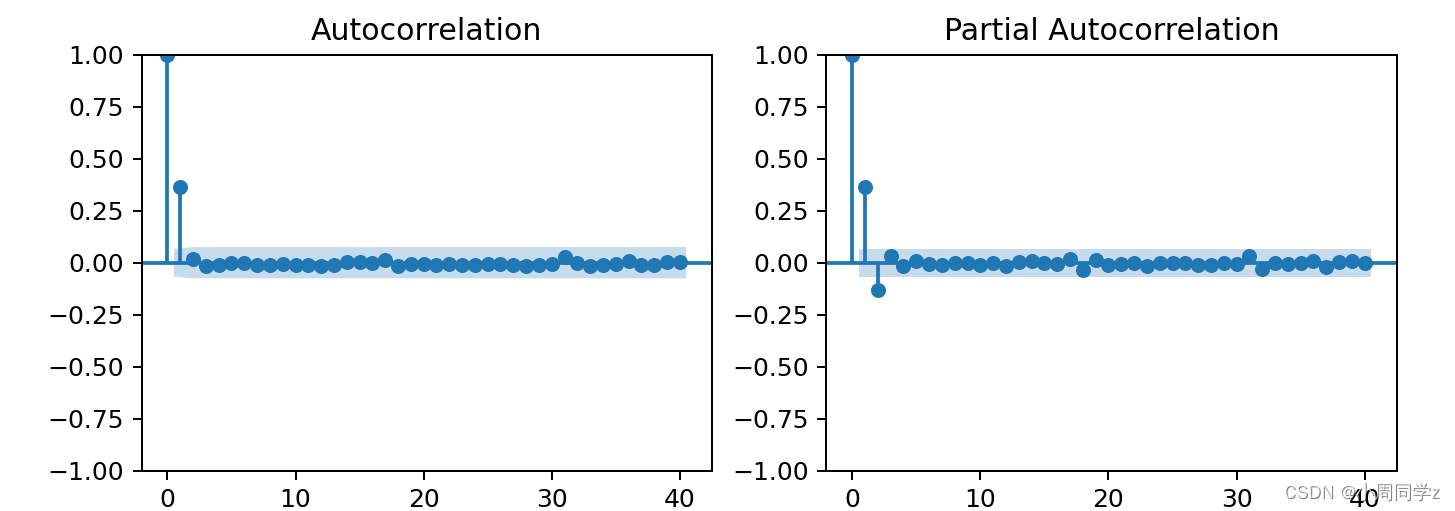
可以观察到,ARCH模型自相关图1阶截尾,偏自相关图2阶截尾,初步定为ARCH(2)模型。进一步考虑bic定阶,
from arch import arch_model
#bic定阶
bic_list = []
for i in range(1,26):
model = arch_model(time_residual, mean='zero', vol='ARCH', p=i)
model_fit = model.fit(disp='off')
bic_list.append(model_fit.bic)
print('p:{},bic:{}'.format(i,model_fit.bic))
best_p = np.argmin(np.array(bic_list)) + 1
print(f'best_p:{best_p}')结果如下:

模型为ARCH(2),对模型参数进行拟合,
# 建立模型
res_model = arch_model(time_residual, mean='zero', vol='ARCH', p=2)
# 训练模型
model_fit = res_model.fit(disp='off')
# 模型结果
print(model_fit.summary())结果如下:
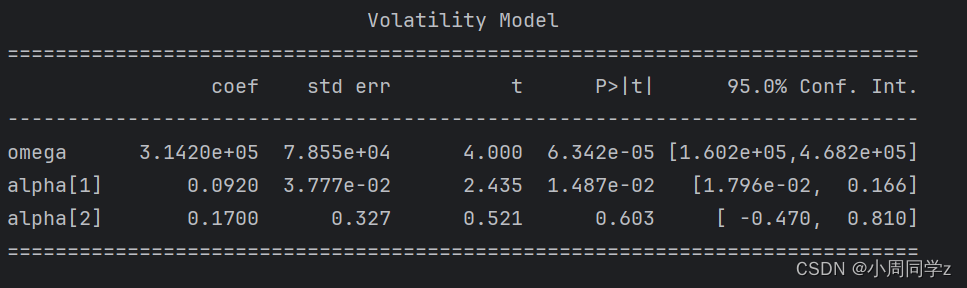
参数显著,检验模型是否显著,对进一步的残差进行白噪声检验:
residual1 = model_fit.resid
from statsmodels.stats.diagnostic import acorr_ljungbox
ljung_box_results = acorr_ljungbox(residual1, lags=20)
print(ljung_box_results.iloc[0,:])结果如下:
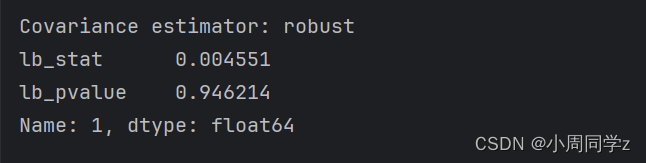
P值为0.946显著大于0.05,可认为剩下的随机项为白噪声序列。
画出拟合图,
arch_forecast = model_fit.forecast(horizon=len(time))
arch_variance = arch_forecast.variance.values[-1,:]
arch_variance1 = 1.96*np.sqrt(arch_variance)
arch_variance2 = -1.96*np.sqrt(arch_variance)
plt.plot(date, time, label='actual', alpha=.2)
plt.plot( time_arma.predict().values + arch_variance1, label='arch')
plt.plot( time_arma.predict().values + arch_variance2, label='arch')
plt.legend()
plt.show()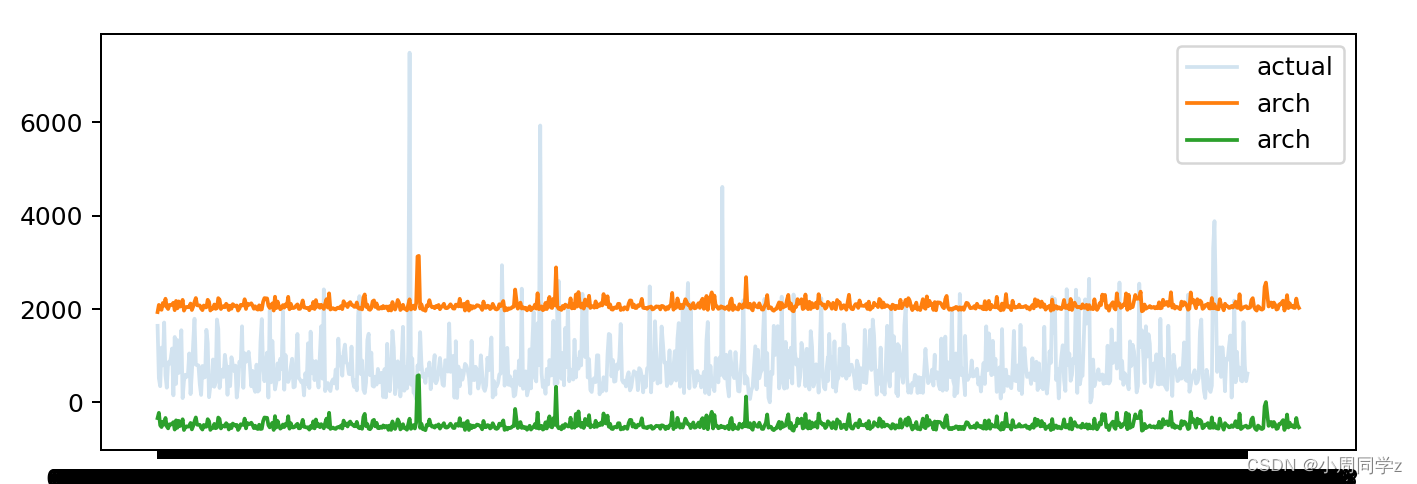
可以观察到,大部分数据落在预测区间之内,拟合效果较好。















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









