





CREMA-D: Crowd-sourced Emotional Multimodal Actors Dataset - PMC
摘要
人们通过面部的表情和说话的声音来传达他们的情绪状态。我们提供了一个独特的视听数据集,专门用于研究多模态情绪的表达和感知。该数据集通过演员说出某个句子,以面部表情和说话的声音来表达某种基本的情绪状态(快乐happy、悲伤sad、愤怒anger、恐惧fear、厌恶disgust和中性neutral)。来自91名不同种族背景的演员表演了7,442个片段,由众包的多个标注者以三种模态进行标注,这三个模态包括:纯音频,纯视频、视频+音频。总共2,443名众包标注者,标注了他们感知到的情绪分类和情绪强度。统计显示,人工标注在纯音频、纯视频、视频+音频三种模态下,相对于表演目标情绪的识别符合率分别为 40.9%、58.2% 和 63.6%。其中演目标为中性的情绪识别符合率最高,其次是快乐、愤怒、厌恶、恐惧和悲伤。对比不同模态下感知到的平均情绪强度,纯视频最高。愤怒和快乐可以根据单一模态的证据,就能得到很好的识别;厌恶和恐惧的准确识别,需要同时从视频和音频信息中寻找线索。我们在此引入的大型数据集,还可用于探索与情绪的视听感知相关的其他问题。
关键词: 情绪数据集、面部表情、多模态识别、语音表情
1、引言
情绪是通过面部表情和语音表情传达的。许多先前的研究都遵循了艾克曼Ekman的基本情绪理论,并集中在面部线索的情绪感知上。艾克曼确立了一个基本情绪模型(喜悦joy、悲伤sadness、愤怒anger、恐惧fear、厌恶disgust和惊讶surprise),是基于特定面部表情的,全世界不同族群的人们都能正确识别[1,2,3]。人们通过语音表达情绪的方面,也存在类似的平行研究[4,5]。许多韵律特征,例如音高、持续时间、响度、语音质量等,都有助于在语音中传达情绪。尽管声学特征与情绪的相关性,在不同说话人之间差异很大,但人们普遍发现,音高是情绪交流中最重要的特征,其次是持续时间和响度[6,7,8]。此外,最近的计算机情绪识别系统,使用了语音谱特征来提高识别准确率[9,10,11]。基于面部和语音的双模态情绪感知研究,仅在最近几年才受到相当大的关注。众所周知,面部表情比声音变化传达了更多关于受试者情绪状态的信息,而声音变化更多地传达清醒的程度[12,13]。 一些研究调查了音频和视频信息是如何整合的,并特别关注当面部和声音表情可能出现相互矛盾的解释时出现的问题[14,15]。 然而,我们仍然没有充分理解这两种模式之间的相互作用。具体来说,音频和视频模态对哪些情绪能表现出互补性,以及互补的概率有多高(当模态组合产生的印象与任何一种单独的模态产生的印象都不同时)、主导性(当两种模态产生不同情绪的印象,而且其中有且只有一个模态与多模态感知的总体印象相匹配时)和冗余性(当两种不同的模态都与多模态感知情绪的印象相匹配时),都是令人感兴趣的。
公开可用的情绪数据集,有的仅包含视觉呈现 [16, 17, 18, 19]、有的仅包含听觉刺激 [20, 21, 22, 23, 24] ,有的是包含视觉和听觉的剪辑 [25, 26, 27, 28, 29],但这些数据集的规模都相对较小,而且仅来自少数标注者的情绪感知,或者不包含针对同一样本的各种模态的独立标注。因此,研究人员在梳理视觉和听觉模态分别对情绪感知的贡献时,受到了限制。
我们提供了一个演员表演众包标注的多模态情绪数据集 CREMA-D,用于研究基本情绪的多模态表达与感知。该数据集收集了大量的表情,作为标准情绪刺激用于神经影像学的研究,这需要不同长度和强度的情绪表达,还需要分离的视觉和听觉模态。演员被用来产生这些刺激,因为他们接受过专项训练,能够以不同的强度清晰地表达各种情绪。他们的情绪表达,由专业的戏剧导演指导。CREMA-D收录了来自91位不同年龄和种族的演员的7,442个片段,表达了七种“普遍情绪”中的六种[30]:快乐、悲伤、愤怒、恐惧、厌恶和中立(导演认为惊讶不够独立,因为它持续的时间很短,而且与任何其他的情绪强相关)。该数据集的每个片段,分别在三种不同模态(纯音频、纯视觉、视频+音频)下进行情绪感知和标注,这些标注由 2,443 名标注者使用众包的方式提交和验证。每个片段在每种模态下都有两种类型的情绪标注——分类标签和强度标签。同一片段有多人标注的结果,可以从中概括出群体感知的情绪标签,比如多数一致的情绪分类标签、情绪强度的平均值。此外,从感知模态的角度看,该数据集分为三个子集,每个子集都包含所有片段及其在该模态下的情绪标签。匹配片段,是指该片段多数一致的群体感知情绪标签,与表演的目标情绪相匹配。不匹配的片段,是指该片段多数一致的群体感知情绪标签,与表演的目标情绪不匹配。最后,模糊的片段,是指群体感知没有多数一致性。
为了解决视听感知问题,我们第一个提供了数满足以下 5 个标准的数据集:(1) 超过 50 名演员 (2) 超过 5,000 个片段 (3) 6 个情绪类别 (4) 每个片段至少 6 个标注者 (5) 3 种模态。较早的数据集,这五个标准中最多只有三个是满足的,如表1.GEMEP数据库[31]包括15个类别的标注,每个片段至少有23个标注者,使用所有三种标注模态;然而,这些片段仅来自 10 位演员,只有 1,260 个标注片段。De Silva等[32]研究了6个类别的音频和视觉感知之间的相互作用,每个片段有18个标注者,并使用了所有三种模式,但只有2个演员和72个片段被标注。Mower Provost等[15]讨论了使用McGurk效应范式创建的视听数据集,该数据集具有匹配和不匹配的声音和面部信息;该数据集是通过众包收集的,仅来自1位女演员的72个原始片段和216个重新合成的片段。Collignon 等人的 AV 集成数据集结合了无声视频剪辑(受试者在脸上表达情绪时不说话)和来自不同来源的语音音频剪辑,以创建标注的情绪显示以及不匹配的情绪。该数据集仅有恐惧和厌恶两种情绪[33]。AV合成角色研究,使用与人类音频剪辑同步的动画视频剪辑[34]来制作视听刺激。一些视听数据库有一组带有音频标注的音频数据和带有视频标注的视频数据,但没有具有相应标注的混合音像数据[35,36]。 IEMOCAP [37] 和 Chen双模态数据集 [38] 具有广泛的收集协议,但仅在音频和视频信息同时存在时才进行标注。同样,HUMAINE [39] 和 RECOLA [40] 数据集有许多不同类型的标签来标注视听情绪表达的不同方面,但所有标注都是针对同时存在声音和面部信息的录制部分进行的。CHAD数据集有超过5000个视听片段,有7个情绪类别,每个片段有120个标注者,但只有音频被标注[41]。最近的MAHNOB-HCI [42]数据集是参与者观看情绪视频,然后自我报告情绪标签。GEMEP 数据集包括 1,260 个视听表达,其中 10 位演员表达了 15 种情绪;每个表达由18-20名标注者评估[31]。有关其他情绪数据集的更多详细信息,请参见[31,43]。
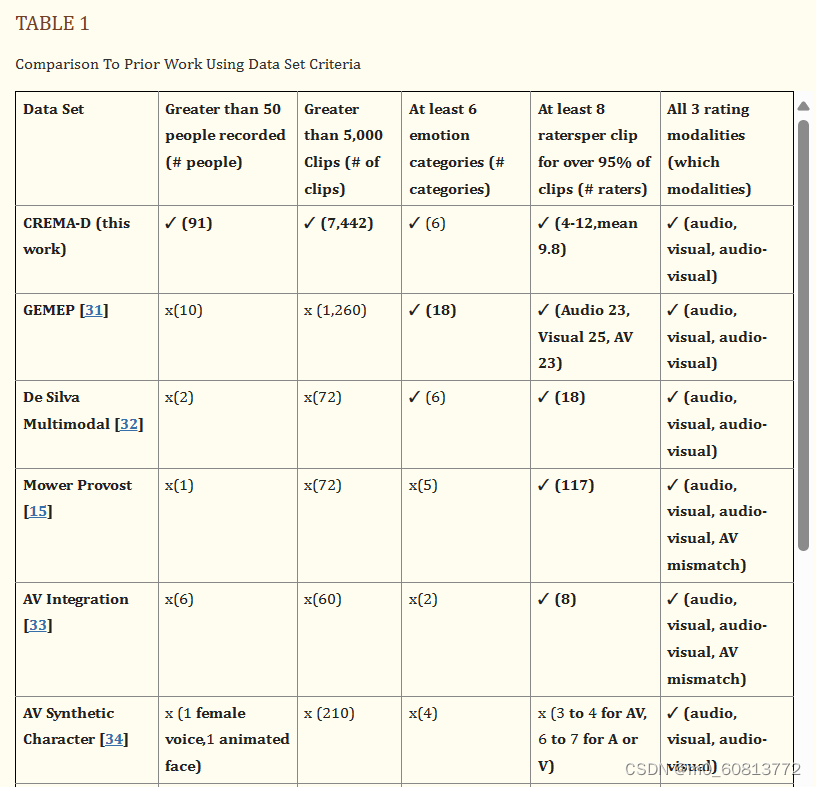
我们的数据集有大量的演员和标注者,这使我们能够研究情绪交流中的各种变异因素。它还提供所有三种模式的众包标注,允许在单模态和多模态之间进行感知比较。
众包为我们提供了大量的标注者总数,这增加了标注的生态有效性。此外,众包使单个标注者不需要承担太多的标注的任务。这样可以减弱个别标注者的偏见产生的标注误差。众包还使我们能够为每个片段收集更多的评分,并使我们能够研究情绪感知相对于表演目标情绪的偏差。
CREMA-D 明确区分了匹配、不匹配和模糊的片段。该数据集将发布情绪表达的类别和模糊程度。这些特性允许开发需要微妙情绪和非基本情绪的应用程序。在一些研究中,例如Berlin数据集[8],只发布匹配的片段。一些数据集,如IEMOCAP [37]和FAU Aibo [24],根本没有标注刺激的模糊程度。然而,在我们的数据集中,可以通过分析与数据集一起分发的评估文件,来检索基本/非基本的情绪表达。在大多数研究中,没有提到这种区别。
本文的其余部分介绍了我们数据采集工作的全部细节,并首次分析了情绪模态之间的相互作用。分析的目的,是突出数据集的潜力,以及可以使用该数据集的各种应用。第 2 节中描述了准备工作;第 2.1 节描述了情绪表达的获取,第 2.2 节描述了标注协议和众包方法。第 3 节介绍了如何从原始众包数据中清除虚假响应,并讨论我们如何定义每个情绪表达片段的群体响应。在第 4 节中,我们进一步研究了数据集的变异因素,并讨论了我们收集的数据集中涉及的各种情绪表达的优势。在第 5 节中,我们探讨了人们如何从音频、视频和视听模态中感知情绪,并进一步讨论不同情绪感知模态之间的相互作用。
2 数据准备
2.1 视听刺激
我们研究的视听刺激,是专业演员在专业导演的监督下表演录像。演员的任务是,在说出给定的句子的同时,传达他们正在体验的目标情绪。导演描述专门设计的场景,来引导演员唤起目标情绪。唤起快乐的一个例子是:“问演员他们最喜欢的旅行目的地是什么;告诉他们刚刚赢得了前往目的地的 10 天全免费旅行。” 有一些演员更喜欢使用个人经历,而不是剧本场景来唤起目标情绪,并被允许这样做。演员在特定的目标情绪中表演给定的句子,直到该表演获得导演的认可。由于需要安排的演员人数众多,因此需要两名导演。
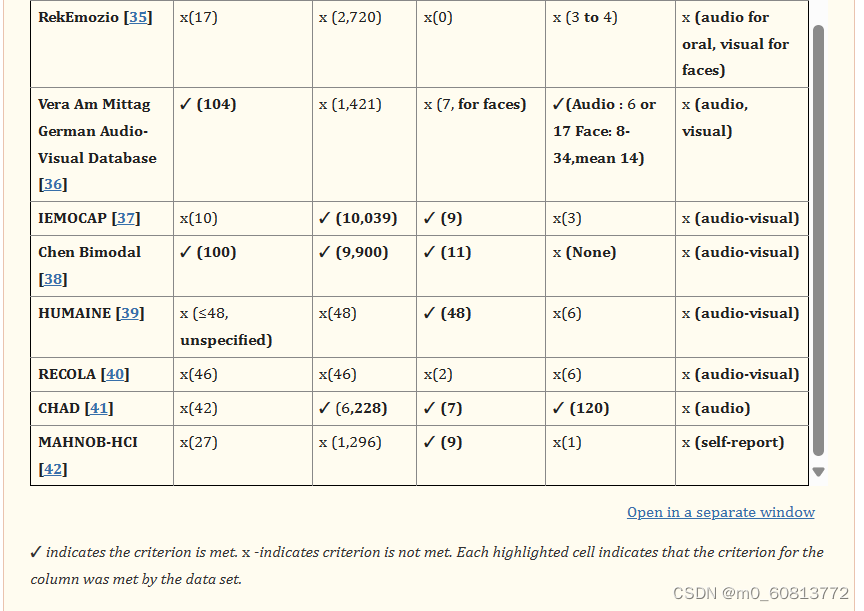
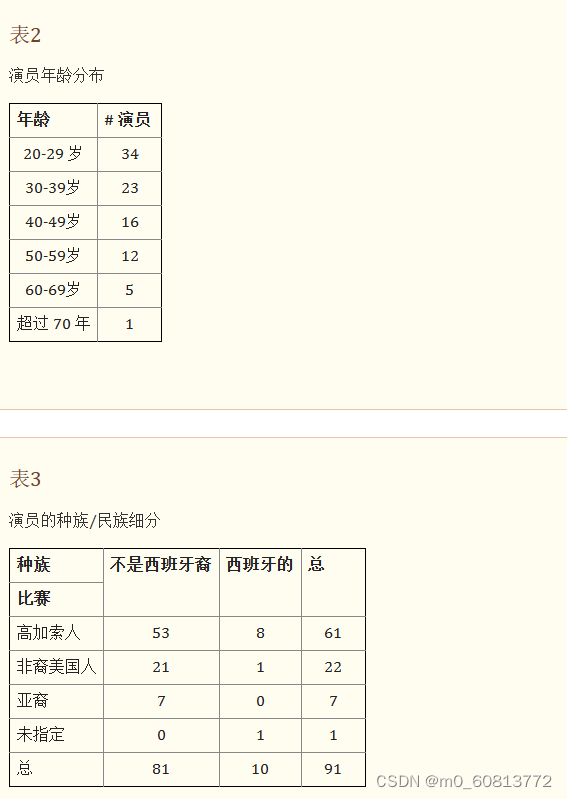
有91名演员,48名男性和43名女性(51名演员与一位导演合作,40名与另一位导演合作)。演员的年龄在20至74岁之间,平均年龄为36岁。表2提供详细的年龄信息。演员组中代表了几个种族和民族背景:白种人、非裔美国人、西班牙裔和亚洲人。表3提供了种族和族裔群体的详细分类。
每次表演通常持续约三个小时,整个表演被记录在视频中。录音是在带有专业灯箱的消声环境中进行的。演员们坐在绿幕前,以便于后期制作剪辑。视频是在松下AG-HPX170上以960x720的DVCPRO HD格式录制的。定向远场麦克风用于收集音频信号。最终的情绪视频剪辑是从原始数字视频文件的完整录制中手动提取的,并使用 H.264/MPEG-4 Part 10 压缩对视频进行压缩,对音频进行 48 kHz 的 AAC 压缩转换为 MP4。视频被进一步转换为Adobe Flash视频,从宽屏裁剪为全屏宽高比(4:3)。
目标情绪是快乐、悲伤、愤怒、恐惧、厌恶以及中性。有 12 个句子,每个句子都是在所有情绪状态下呈现的。演员被指示以三个强度级别表达第一句话:低、中、高。对于其余11个句子,强度级别没有具体指定。如果录制三个强度的所有句子,成本高得令人望而却步;所以,我们只录制了一句话的三个强度,用于试点研究,或用于情绪表达相关特征的特征分析,或作为分层测试数据来量化不同强度下的情绪识别能力。
在先前的一项研究中,以下12个句子的语义内容均被评为情绪中性[44]。这12句话是:
-
现在是十一点。
-
事实正是如此。
-
我正在去开会的路上。
-
我想知道这是关于什么的。
-
飞机几乎满员了。
-
也许明天会很冷。
-
我想要一个新的闹钟
-
我想我有医生预约了。
-
别忘了穿夹克。
-
我想我以前见过这个。
-
表面光滑。
-
我们几分钟后就停下来。
根据数据采集设计,数据应由 7,462 个片段组成,其中片段是演员 A 在说出句子 S 时对目标情绪 E 的演绎。然而,由于技术问题, 有20 个片段无法从原始视频中提取;其中三句话缺少一个演员的所有六个情绪片段,即缺失 18 个片段;此外,有2句话缺少一个演员的中性片段。
2.2 众包的感知评级
译者注:为了语句通顺和容易理解,原文的rating,有时翻译为标注,有时翻译为评级,有时翻译为平分,含义都是标注者观看和/或聆听预先录制的Video和/或Audio,感知演员的情绪,提交情绪分类和情绪强度。
该数据集收集了三个剪辑版本的感知评级:原始视音频剪辑、纯音频剪辑和纯视频剪辑。每个版本都对应一种感知模态。有 7,442 个原始剪辑,总共有 22,326 个标注样本。目标是为每个样本收集 10 个评分,总共有 223,260 个单独的评分。
我们使用 Adobe Flash 创建了一个感知调查工具,并利用众包来获得评级。我们通过国际调查抽样组织(SSI)聘请了标注员,该机构专门为调查研究提供支持,并为此目的招募受试者。SSI 向他们的参与者群体宣传了这项任务,并招募了完成我们任务的 2,443 名标注者。
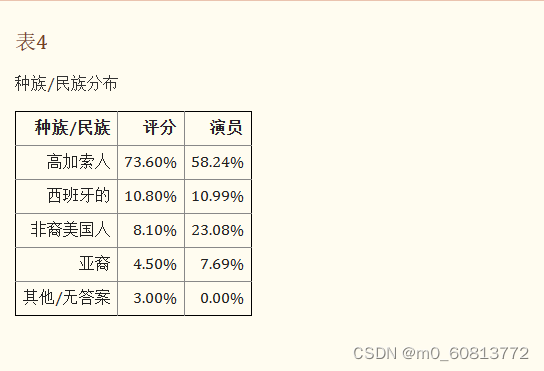
标注者年龄在18至89岁之间,平均年龄为43岁。其中男性占40.5%,女性占59.5%。他们大多是白种人,但也有一些非裔美国人、西班牙裔和亚洲人也参与其中。表4显示标注者和演员的种族和民族分布,以便进行比较。
每个标注者只允许做一个标注批次。标注者被要求使用耳机。在正式开始评分前,参与者需要先完成音量校准和听力测试任务,以确保标注者可以听清演员小声的讲话,大声讲话又不觉得刺耳。听力测试任务包括以低、中和高强度记录的单词测试样本。低强度测试样本接近剪辑中演员最小声的讲话。高强度测试样本接近剪辑中演员最响亮的语音的水平和质量。中等强度测试样本在高强度和低强度之间。
首先,参与者被要求完成音量校准任务。三个单词样本用作剪辑中低、中、高音量的示例,如图1的左边。参与者被要求根据多次聆听这三个单词样本并调整耳机的音量设置,以便能听清最低声音的单词,而且最高声音的单词不刺耳。一旦他们对耳机的音量设置感到满意,参与者就会从音量校准任务转移到听力测试任务。听力测试允许多达三个试验来识别低、中和高级别的三个新单词样本;每个试验都从三个样本的单个音频演示开始。然后,参与者必须从界面上显示的 12 个单词列表中选择他们听到的单词,如图1的右边。当参与者在试验中正确选择三个目标词时,他们就通过了听力测试,可以继续进行感知评分任务。三次声音试验失败的参与者不得继续进行感知评级。

使用12个单词作为目标单词,以便在音量校准任务或听力测试中的任何试验中都不会重复使用同一个单词。此外,还选择了 27 个闪词,以便每个试验在多项选择界面有 9 个独特的替代选择。目标词和闪词是从WRAT4阅读清单中选出的[45],以便所有参与者都能知道这些单词。对于每个参与者,12 个目标词和 27 个闪词是伪随机排序的,每个参与者每个词只使用一次。
在完成声音测试后,评分者将获得对评分任务的描述,即指定在呈现给他们的每个片段中表达的两种情绪评级。第一个评级是情绪类别。标注者可以从目标情绪(愤怒、厌恶、恐惧、快乐、悲伤)中选择一种情绪,或者如果他们没有感知到任何特定情绪,则选择“无情绪”。第二个评级是一个连续值,它对应于识别情绪时情绪状态的强度;如果选择“无情绪”,则对应于没有可感知情绪的置信度。
然后向标注者展示三个部分,这些部分由具有单一模态的剪辑组成:首先是纯音频,然后是纯视觉,最后是视听(原始剪辑)。每个部分都以对各自模态的简短描述开始,然后是两个练习题,以便标注者能够熟悉演示的形式以及选择情绪和强度的界面。练习题完成后,屏幕将指示开始正式标注。一个待标注片段被呈现出来,然后显示黑屏以产生视觉刺激,并要求标注者选择一种情绪分类。选择情绪分类后,所选情绪下方会显示强度评级选项。如图2所示。强度等级使用连续滑动条,评分范围为 0 到 100。如果有人想更改他们的选择,他们可以按重置按钮返回情绪选择对话框。按下“继续”按钮后,将显示下一个剪辑。这将一直持续到一个标注批次的结束。

每个标注者完成一个批次的任务列表,每个批次有 105 个样本。每个批次列表有三个部分,分别对应一种模态,它们始终以相同的顺序呈现:35 个纯音频、35 个纯视频、 35 个视音频。在每种模态下,开始的2个样本用于练习,随后的30个样本用于CREMA-D 数据集,还有3个重复样本用于测试评级的一致性。3个重复样本随机穿插在30个正式样本之间;其中,重复样本的第一次评级用于数据集,第二次评级仅用于检查一致性。在同一批次的任务列表中的多个模态之间,没有与同一原始视音频剪辑相关联的样本。然而,在不同模态的样本中偶尔会看到同一个演员。
我们创建了 2,490 个批次的任务列表,以保证每个样本至少评分 10 次。每个句子都被分配了一个从 1 到 7,442 的编号。每个标注批次都从剩下可用的句子编号中挑选 90 个(30 个编号只取纯音频样本、30 个编号只纯视觉样本, 30 个编号只取视听样本)。每个批次的三个模态子列表中的样本顺序伪随机排列。然后在预先指定的位置选择9个文件编号(每个模态3个)进行复制,并将重复的样本插入到预先指定的位置。这些重复的样本用于一致性测试。
一些标注者没有完成分配的标注批次。他们要么因为遇到了技术困难,仅完成部分样本的评分停止了工作,要么没有通过听力测试。考虑到未完成的批次的标注者可能对情绪标注缺乏兴趣,因此丢弃了未完成批次的情绪评级,并将该批次样本全部回收到可用样本池。这需要人工干预,最终留下了 47 个未完成的批次。
数据在Adobe Flash调查工具传输到服务器的过程中,我们又丢失了大约 1% 的评分(平均每种模态丢失 733 个评分)。尽管如此,只有大约 1,700 个刺激在每种模态下的评级少于 10 个。这是由于传输过程中丢失数据和未完成的47个批次的综合原因。由于这种数据丢失,在数据被清理之前,仍有超过 95% 的剪辑具有 9 个或更多的评级,而在数据被清理后,仍有 8 个或更多的评级。数据清理将在下一节中介绍。
3 数据清理
3.1 生成可靠的数据集
众包数据采集中的一个问题是“作弊”或“糟糕”的响应[46,47,48,49,50,51]。我们的研究旨在降低Eickhoff和de Vries[48]所述的对作弊者的吸引力。在我们的任务中作弊不会为标注者节省多少时间;并且每个标注者都被分配了唯一的演示顺序,因此标注者之间没法相互复制评分。
为了消除由于分心而导致的不良响应,我们删除了初始响应超过 10 秒的评分。所有响应的平均响应时间为 3 秒,中位数为 1.7 秒。以中位数和平均值为参考点,可以安全地假设回答时间超过 10 秒的参与者在回答问题时很可能分心。结果,7,687 个响应作为分心响应被删除,占 2,443 名参与者的 219,687 个响应的 3.6%。没有很好的方法来评估评分动作是否太快,因为好的标注者能在观看和/或聆听视频和/或音频的过程中就准确地感知到了演员的情绪并准备好答案。如果标注者能熟练地定位鼠标,他们可以在视频和/或音频停止后立即点击。
我们选择保留所有标注。在传统的数据标注工作中,量化统计标注者的自身一致性、标注者之间的一致性,被认为是必不可少的。然而,评估我们的数据集的标注可靠性,带来了许多挑战。首先,甚至在开始标注之前,我们就已经预料到一些刺激是模糊的,因为他们表达了微妙情绪或复杂情绪。我们的目标是,将模糊的刺激,识别为标注者不能取得共识的刺激。我们关注的这一问题使标注者之间一致性的评估变得复杂化,因为对这些刺激的分歧并不是标注者的问题。
使用标准可靠性度量指标存在另一个困难,剪辑之间的评分者几乎没有重叠---大多数剪辑由不同的评分者组标注。这是通过设计完成的,以增加每个剪辑由一组好的标注者评分的机会,并最大限度地减少同一组糟糕的评分者标注多个刺激的可能性。
尽管存在这些挑战,我们仍以两种方式进行可靠性分析。首先,我们分析了个体评分者在情绪强度上的标注的可靠性。我们根据单个评分者的标注与“参考”标签之间的相关性来调查评分者的可靠性,参考标签为所有标注者的平均强度等级。这些计算是按标注者进行的,并计算了该特定标注者评定的所有刺激的相关性。我们的标注者表现出了合理的可靠性。它们中的大多数与参考标签具有中等或高度相关性。具体来说,当我们考虑所有 6 种情绪的平均相关性得分时,2443 名标注者中只有 20 名(~1% 的标注者)表现出弱相关性(相关性< 0.4);888 名(~36% 的标注者)达到中等相关性(0.4 <相关性< 0.7);其余 1535 名(~63% 的标注者)获得强或高相关性(相关性> 0.7)。根据刺激的方式,评估者与参考标签的一致性存在明显差异。在视听剪辑中与参考标签的平均相关性最高,为0.75,,仅视频剪辑降至0.72。仅音频剪辑平均相关性最低,为 0.62。我们在论文增补中提供了直方图,用于详细描述标注者在每种模态每种情绪的相关性。
接下来,我们研究注释者之间的综合一致性。在这里,我们将标注者分组。分组的方法是,每个分组内的所有标注者至少标注了同一个剪辑,而且每个剪辑至少有2个标注者给出了评分。我们分析了整个数据集、模态子集的情绪标注一致性,发现了 80% 的标注者在模态情绪标签上获得了共识;我们因此认为模态子集上的标注是对情绪状态的清晰描述。所以,我们将不到 80% 的标注者给出多数情绪标签的刺激视为模糊的情绪,正如我们在后面的章节中讨论的那样,因此模糊的刺激造成标注者之间的一致性是不可预期的。我们还分析了情绪强度等级的标注一致性。
我们使用 Krippendorff 的 alpha 作为标注可靠性指标 [53,54],因为它可以处理分类响应(选定的情绪标签)和比率响应(其中 0 是最低值,表示缺失,就像我们的情绪强度评级一样)。它还可以处理缺失的响应,这在本节开头讨论的数据集中很常见。我们的分析方法在论文增补中给出了充分的定义。结果总结为表5,列出了用于计算可靠性分数的平均剪辑数,以及这些剪辑中该组的平均标注者数量,以及 alpha 值。
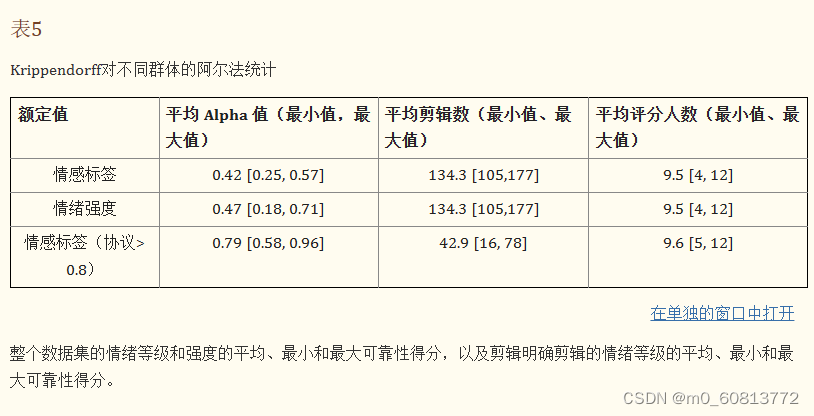
全集的平均 alpha 可靠性得分为 0.42。当仅评估至少 80% 的标注者识别出相同情绪的数据子集的可靠性时,平均 alpha 可靠性得分为 0.79。鉴于这种对标注者间一致性的分组分析,每个剪辑被赋予了一个新的标签,来表示该剪辑的标注可靠性。在对可靠性有特定要求的研究中,研究人员可以选择标注为高一致性的刺激,生成需要的子集。我们在论文增补中提供了对 Krippendorff 的 alpha 的详细分析。
除了可靠性分析外,我们还根据标注者如何标注重复的剪辑来衡量标注者的自身一致性。在我们的研究中,选择了 9 个剪辑(每种模式 3 个)进行复制。标注者的自身一致性定义为在所有重复剪辑中分配了相同标签的剪辑占所有重复剪辑的比例。CREMA-D数据集中将提供每个评分者的详细一致性信息,以便数据库用户可以根据自己的应用程序决定如何使用这些数据。一般来说,如果单个评分者的一致性很高,则总体一致性会接近 70%。随机选择的情绪标签,恰好与第一次评分给出的情绪相同的概率为 16%。此外,我们观察到低强度刺激的一致性较低,注释者更有可能改变这些剪辑上的标注。具体来说,对于具有一致评级的剪辑,我们注意到强度较高(mean 65.5,std 23.6),而标注者难于取得共识的剪辑的强度要低得多(mean 54.5,std 24.9)。我们在第 5.1 节中讨论了标注者对三种模式的一致性。
3.2 对响应进行分组
清理数据后,我们按句子和模式将响应制成表格。表格中的响应包括剪辑被识别为给定情绪的次数、响应总数、每个情绪标签的平均强度值、中性响应的平均置信度值以及强度和置信度值的归一化版本。强度和置信度值对每个评分者进行标准化,以跨越 0 到 100 的整个范围,与原始评分的等级相匹配。具体来说,纯音频的平均情绪强度,除愤怒接近60外,其它约为 50。纯视觉的平均情绪强度除快乐接近70外,其它情绪都在60左右。视听模态的平均情绪强度,除愤怒略高于纯视觉外,其它情绪都介于纯视觉强度和纯听觉强度之间。
我们将情绪明确的剪辑定义为那些具有多数一致的群体感知情绪的剪辑。模糊情绪的剪辑是那些没有多数一致的群体感知情绪的剪辑。尽管导演在录制时已经验证了演员的情绪表演,但有一些情绪明确的剪辑,小组感知的情绪标注仍然与演员的目标情绪不匹配。因此,我们进一步将明确的剪辑拆分为匹配子集和不匹配子集;匹配子集中,群体感知的情绪与演员的目标情绪相匹配;不匹配的子集中,群体感知的情绪与演员的目标情绪不同。
划分的结果是匹配子集、不匹配子集和模糊子集。匹配子集对应于群体识别,通常被视为黄金标准;但是,多数一致评级与演员目标情绪不匹配的剪辑,还有很多用途。我们将所有三个子集都包含在数据集的最终版本中,以便研究人员可以基于模糊情绪/基本情绪选择最适合其研究目标的数据。
二项式多数用于定义多数识别。与传统多数不同,传统多数被定义为超过 50% 的标注者选择了特定的情绪。当二项式检验在 95% 的置信水平上拒绝了从六个可能的标签中随机选择最常选择的标签的零假设时,就实现了二项式多数。
对已清理数据,显示了具有 4 到 12 个分类标注的剪辑数。超过 99.9% 的剪辑具有超过 6 个类标注。超过 95% 的剪辑具有超过 8 个分类标注。这些值在表中带有阴影。我们还列出了使用二项式多数选择情绪标签所需的最低票数。与严格多数相比,对于具有 8 个及以上评级的剪辑,我们需要更少的二项式多数票。在这种情况下,我们将把更多的剪辑放在一个明确的类别中。表7给出每种模态的三个子集(匹配子集、不匹配、模糊子集)的比例。CREMA-D 中大量带标注的剪辑确保了 9 个子集中的每个子集都具有足够数量的剪辑以发挥作用。最小的一组是情绪模糊的视听子集,有超过 590 个标注剪辑。
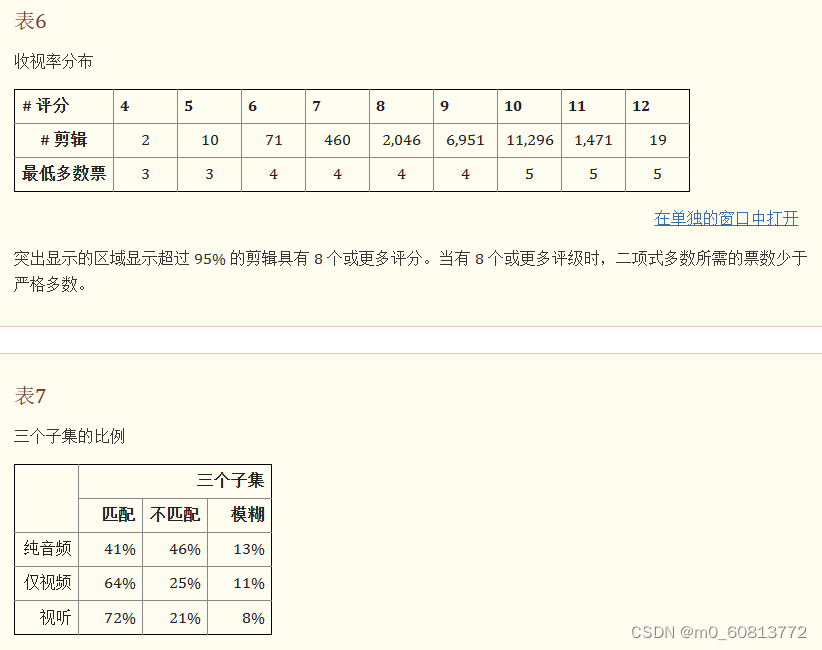
另一方面,我们还分出了一个具有 10 个或更多分类标注的剪辑子集(称为MAIN set)。从统计学/心理学的角度来看,这个MAIN set有望在未来的感知研究中可靠地使用。
4 数据集的变异因素和模糊性
在感知调查的基础上,我们首先探讨了CREMA-D数据集的变异因素和模糊性。
4.1 感知和模态
首先,我们提出的CREMA-D数据集展示了其变异因素,包括从各种来源的大量录制和模态独立的人工标注。
纯音频、纯视频、视频+音频,这种多模态情绪表达的录制,允许未来对情绪交流的多种研究,无论是关注任何单模态,还是关注更复杂的多模态。与许多其他情绪表达的多模态数据集不同,这些数据集仅包含一个反映多模态刺激产生的情绪印象的整体标签,我们的数据集在每种模态中提供单独的人工标注。所有三种模态的标注可用性,使我们能够进一步研究单模态和多模态感知之间的关系和差异。
4.2 不同强度的情绪表达
CREMA-D 数据集中的刺激也显示出所有三种模态下情绪表达强度的变异。
表8总结了每种模态下不同情绪强度的分布以及相应的识别率。如表所示,强度分为三个级别,其中温和情绪位于强度等级的下25%,极端情绪落入强度等级的上25%,中等情绪是介于两者之间。为了更好地理解表达强度与相应识别率之间的关系,我们在同一表中列出了相应的群体感知率。群体感知率,是群体多数一致的标签与演员的目标情绪相匹配的剪辑的百分比。
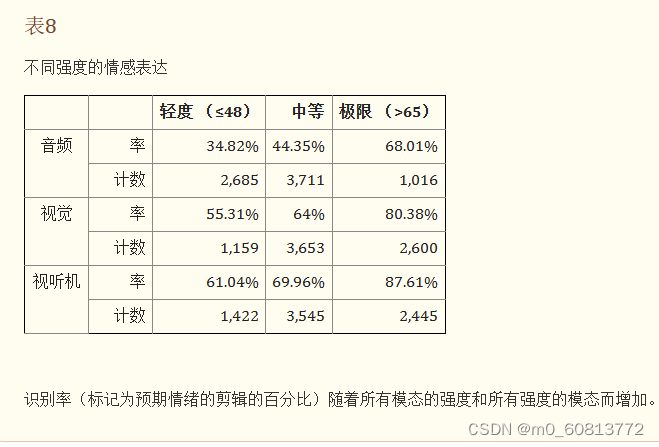
在我们的数据集中,有很大一部分情绪表达在所有三种模式中都是中等强度。这一发现证明了这样一个事实,即一般来说,演员在导演的指导下,在许多情况下表达了微妙的情绪状态,而不是极端夸张的表情。视觉和视听表达在极端强度的描绘中比例最大,这些仅占给定模态中所有刺激的三分之一左右。相比之下,对于音频来说,很大一部分获得的表情实际上被认为是温和的,只有不到15%的刺激被评为极端强度。
最重要的是,每种模态的每个强度级别至少包含 1,000 个剪辑。因此,如果研究人员只想使用数据集的一部分,例如只使用温和的、更模糊的表达,或者只使用基本情绪、易于识别的情绪表达,那么该子集仍将大于许多目前存在的情绪表达数据集。基于前一个子集构建的模型可能更适合应用于自然对话,而基于后者的模型可能更适合于情绪生成应用程序。
情绪表达的强度与人类的识别率密切相关。在每种模态下,识别率随着强度的增加而增加。此外,Busso等[52]发现,每个情绪强度水平的识别率对于纯音频最差,而对于视听效果最好。所有这些观察结果都表明,人类可以通过更明确的信息更正确地感知情绪,例如,更高的强度水平和更完整的表达模态。
4.3 混合情绪的表达
自然的情绪表达往往是混合的或模糊的。因此,人工评分者对清晰和基本情绪的表达有很高的一致性,但对于模糊的混合情绪,当被要求选择一种情绪时,不同的标注者者可能会给出不同的答案。我们将标注者对每个片段的反应分布制成表格,作为情绪概况。剪辑的情绪概况显示了评分者感知到的情绪的混合状态。
图3描绘了我们数据集中刺激的平均情绪特征,显示了当愤怒、厌恶、恐惧、快乐、中立和悲伤是每种模式中的主要感知情绪时的反应分布。
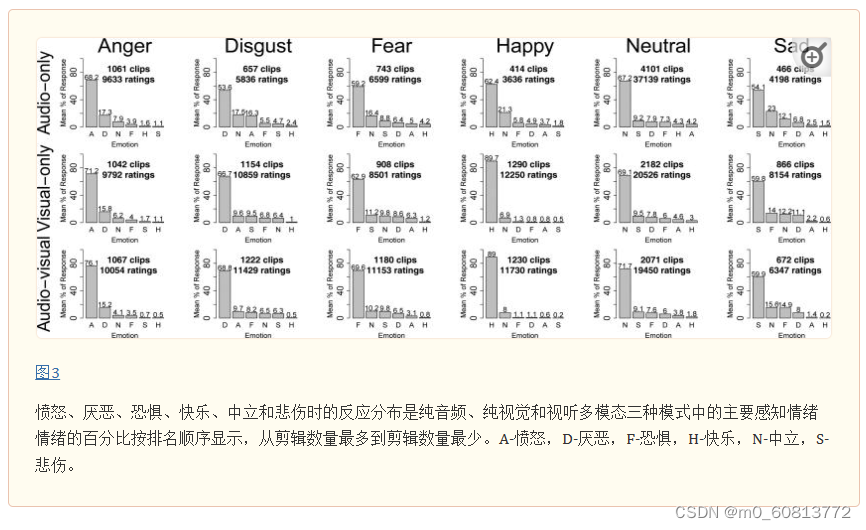
情绪表达的清晰度因不同情绪的不同表达模态而异。一般来说,情绪表达在声音表达方面最模糊,而基于多模态视听表达最清晰。在情绪方面,愤怒是最明显的感知情绪。在所有三种模态中,厌恶都是第二明确的感知情绪。另一方面,悲伤是最模糊的情绪,其主情绪峰值最低,并且相对于第二情绪分量的优势不够明显。我们还注意到,各种模式在表现不同的情绪方面显示出不同的优势。例如,面部表情非常明确地传达了快乐。大约90%的标注者在面部或视听表情方面对快乐的看法一致。
我们之所以包含具有模糊情绪的剪辑,是因为有些应用程序可能需要处理模糊的情绪。例如,有时模糊的表达可能更接近现实生活中的自然情绪。与许多仅包含清晰和基本情绪表达的录制的情绪数据集不同,我们的数据集中匹配、不匹配和模糊三个亚组的划分可以支持未来研究的更广泛的应用。
5. 人类对情绪表达的感知
到目前为止,我们的分析已经证明了我们数据集中的表达方式种类繁多。在这里,我们对情绪感知中各种模式之间的差异和相关性特别感兴趣。在第 5.1 节中,我们首先讨论了人们如何在纯音频、纯视频和视听三种模态中以不同的方式感知情绪。然后,在第 5.2 节中,我们进一步讨论了不同情绪感知中模态的相互作用。
5.1 各种模态的情绪感知
为了更好地了解人们如何以不同模态感知情绪表达,我们在这里研究了不同模态的感知响应时间、识别率和强度、标注一致性和标注者个体之间的差异。
图4将三个直方图(每种模态一个直方图),描述了为每个剪辑选择情绪分类时标注者的平均响应时间。直方图形状的差异表明,人们在不同模态中具有不同的情绪感知速度。一般来说,人们通过纯声音来感知情绪时,需要更长的时间;而他们过面部表情和视听来感知情绪时,反应速度会更快。与纯视频相比,视听模态的响应速度非常快,更多样本的反应时间不到 1 秒。这表明在某些情况下,视音频结合可能有助于提高情绪感知的速度。
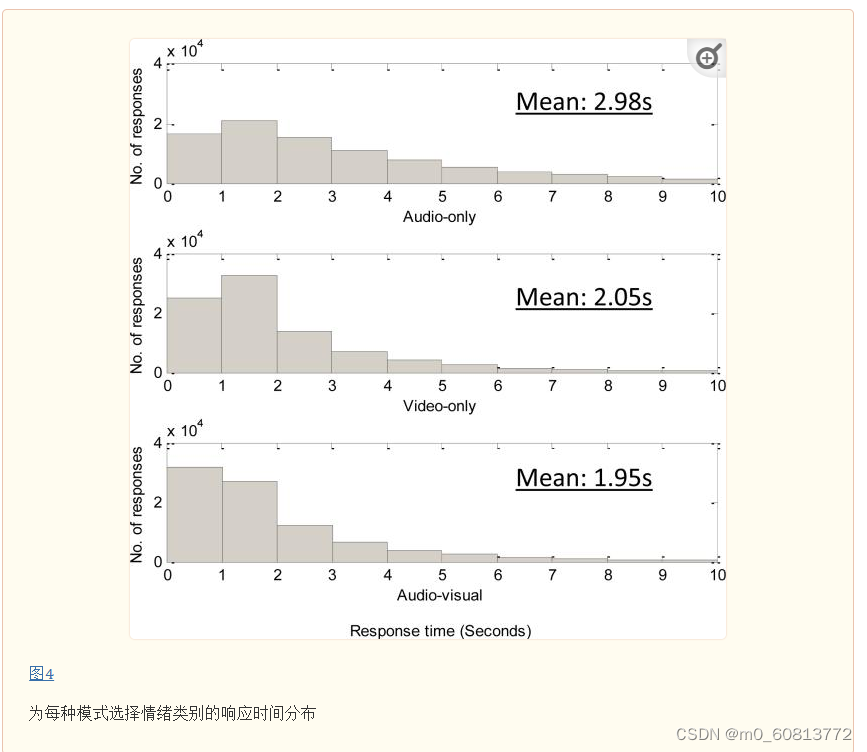
接下来,我们分析了标注者个体在以下方面的不同表现:1)相对于演员的目标情绪,标注者能够正确识别的准确率(即正确识别为目标情绪的百分比);2)一旦标注者选择了一种情绪,他接下来选择的情绪强度。
我们发现在多种模态之间,情绪感知的准确率存在显著差异。平均而言,来自各个标注者的纯音频、纯视觉和视听评分与目标情绪的匹配度分别为 40.9%、58.2% 和 63.6%,组间差异方差分析检验的 p < 0.001。这表明,与纯音频表达相比,纯视觉表达中描绘的与情绪相关的信息更多,并且视听组合进一步提高了情绪感知的准确率。
此外,在情绪类别之间,情绪感知的准确率存在显著差异。各模态下的总体情绪感知准确率,从高到低分别是中性、快乐、愤怒、厌恶、恐惧和悲伤。图5显示了各模态下,情绪之间情绪感知准确率的比较。
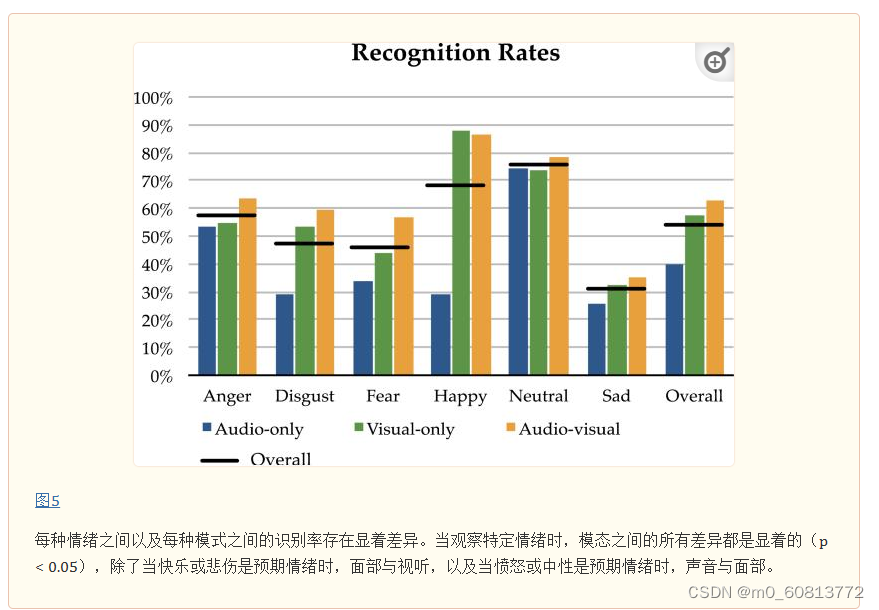
很明显,不同模态更适合表达特定的情绪。纯视频模式和视听模式显示出类似的趋势,但它们与纯音频模式明显不同。例如,面部表情最清楚地传达了快乐,而声音表情比其他情绪更好地传达了愤怒。
我们还测试了模态对平均情绪强度的影响,如图6所示。情绪强度和中性可信度,在不同模态之间存在显著差异。各种模态下的平均强度,从高到低依次为纯视觉、视听和纯听。相比之下,中性标签的置信度,最高的是视听,然后是纯视觉,纯音频刺激的中性置信度最低。
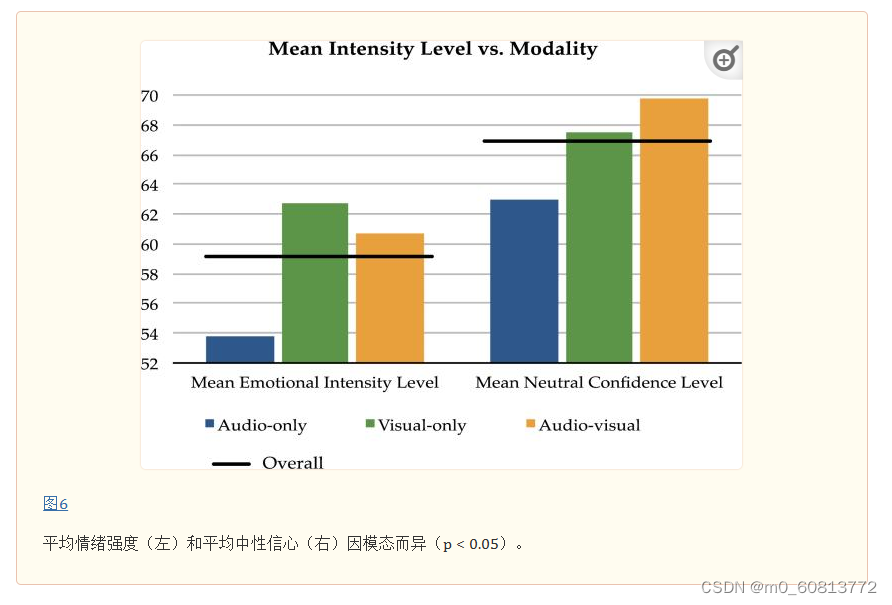
我们还检查了重复刺激时,标注者对测试样本的反应一致性。在我们的数据集中,每个标注者每种模态接受3个重复刺激。表9显示了标注者在三种模态上的感知一致性。整体感知一致性相当高,接近70%,表明相同的表达触发了对情绪内容的相同感知。此外,视听刺激的感知一致性最高,为76%,纯音频刺激的感知一致性最低。

除了根据标注者的平均感知目标情绪准确率和情绪强度分析总体趋势外,我们还对标注者之间的差异感兴趣。图8显示了每种模态中所有标注者的情绪识别准确率的箱线图。箱的中心标记是中位数(50%的标注者的识别准确率在此线以下),箱的下边缘是第 25百分位数(25%的标注者的识别准确率在此线以下), 箱的上边缘是第 75个百分位数(75%的标注者的识别准确率在此线以下)。箱上T字线表示最价识别准确率,箱下倒T字线表示最差识别准确率,红色标记表示识别准确率的异常值。
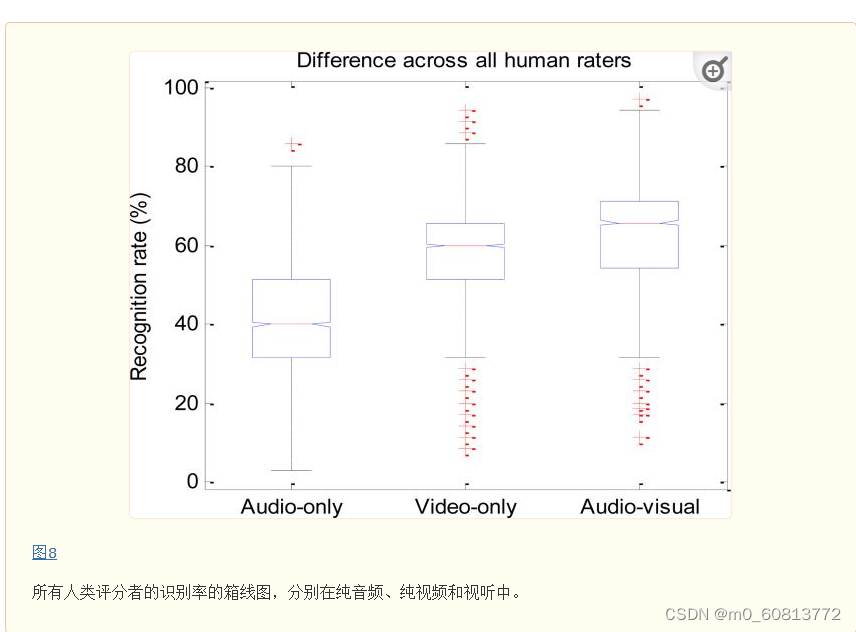
总体而言,在所有三种模态中,标注者之间都存在相当大的差异。例如,在纯声音表达方面,最佳标注者的识别准确率高于 80%,而最差标注者的识别准确率低于 10%。在所有标注者中,纯视频模态的识别准确率差异最小,其次是视听模态,而纯音频模态的识别准确率差异最大。
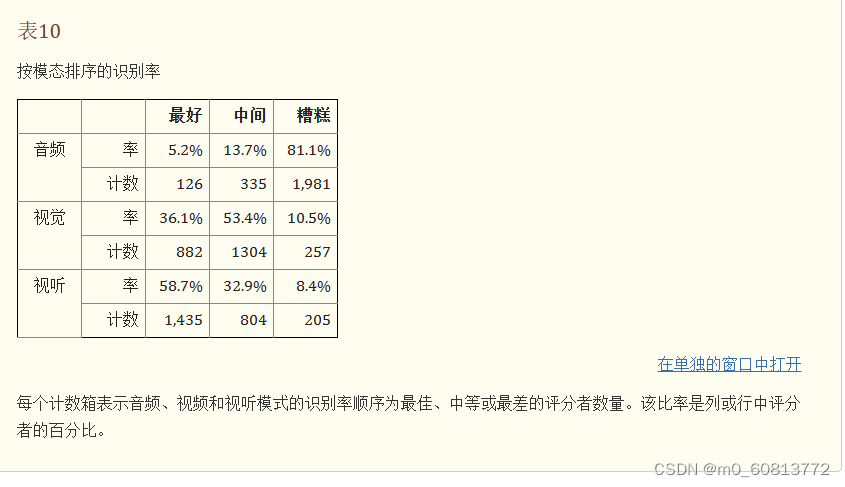
箱线图分析表明,在所有人工标注者当中,视听表达比纯面部表情和纯语音表情更清楚地传达了情绪状态。然而,这种总体趋势并不总是适用于标注者个体。逐条样本的情绪识别过程,潜在地对标注者的情绪识别能力可能形成学习效果;先播放纯音频,然后播放视频,最后播放音频+视频,这样的固定播放顺序可能会影响以上评估结果;为了验证这个猜想是否存在,我们做了两个试验。第一个试验是,检查个人情绪识别准确率高-中-低的模态顺序。由于有三种模态,因此有6种排列顺序,V-A-VA、V-VA-A、A-V-VA、A-VA-V、VA-V-A、VA-A-V。这些情绪识别准确率模态顺序列在表10,按模态汇总了标注者情绪识别准确率的分布。(例如,假设某个标注者情绪识别准确率高-中-差的顺序是纯视觉、纯音频、视觉+音频,这将增加纯视觉最佳、纯音频中等、视觉+音频最差的计数)。视觉+音频最佳的标注者最多,为58.7%。假设存在学习效果,对于所有的标注者,视觉+音频应该都是最好的,视觉应该都是中间的,音频应该都是最差的;但实际情况是,每个柜(bin)都有至少有 5% 的标注者。此外,对于单个标注者,纯音频并不总是识别度最差的模态:近 20% 的标注者在纯视频或视频+音频模态上的识别率较差。不存在学习效应的另一证据是,有5%的标注者,音频刺激的识别率实际上是最好的。同样,36%的标注者对纯视觉刺激表现出最好的识别准确率。这些发现表明,视听刺激被识别得最准确,而纯音频刺激被识别得最不准确的总体趋势不是由于学习效应造成的;个别评分者在个人表现中不遵循这样的趋势。有些人最擅长的模态最先播放,有些人最擅长的模态中间播放;有些人最不擅长的模态最后播放,有些人最不擅长的模态中间播放。
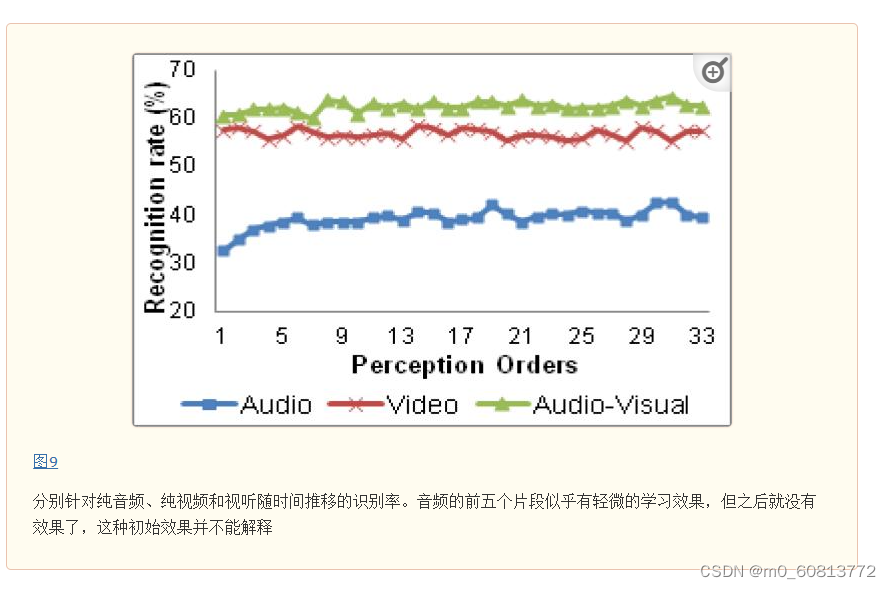
第二个试验是,检查了每个刺激编号(刺激编号对应于标注者看到它们的时间顺序)的所有标注者的平均识别率,并将结果绘制在图9.识别率与刺激呈现的先后顺序之间似乎没有直接关系。对于纯视频模式和视听模式(始终最后呈现)的不同刺激,识别率具有可比性。音频刺激总是首先呈现,我们确实观察到前 5 个刺激响应能稳步改善,但是其余 30 个响应的表现趋于稳定。
5.2 模态间的相互作用
现在我们研究不同情绪感知模态之间的相互作用。我们根据群体感知评级进行分析。
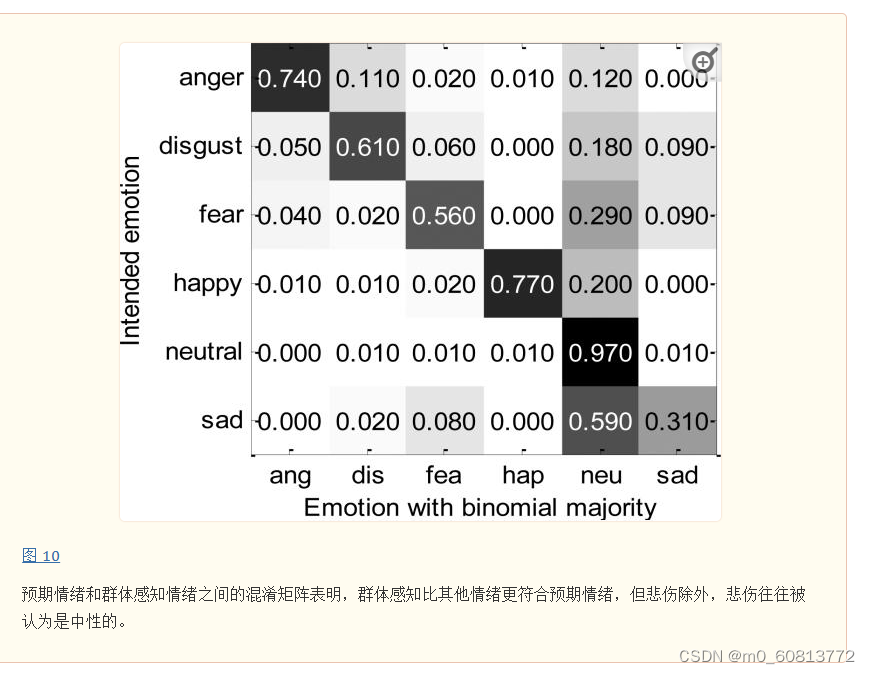
首先,我们研究了演员目标情绪与群体感知情绪之间的混淆矩阵,每种情绪在所有模态中具有二项式多数。图 10显示了所有情绪明确剪的辑的演员目标情绪与群体感知情绪之间的混淆矩阵。标注者明显偏向于选择中性neutral。除了对角线的演员目标情绪外,在所有五个情绪类别中,中性是最常感知的情绪。此外,超过 95% 的中性话语被正确识别为演员目标情绪,只有少数例外。实际情绪类别之间最常见的混淆是有意的愤怒,被感知为厌恶(11%);有意厌恶分别被感知为悲伤(9%)、恐惧(6%)和愤怒(5%),并呈下降趋势。有意的恐惧被感知为悲伤(9%),反之亦然(8%)。快乐大多被正确感知。
接下来,为了梳理纯音频和纯视频对情绪感知的贡献,我们检查了基于单模态(纯音频或纯视觉)与音频+视觉评级相比的感知一致性。为此,我们计算了在每种模态组合中具有相同感知标签的剪辑数量。我们在Venn图中显示了这些计数,如图 11所示。
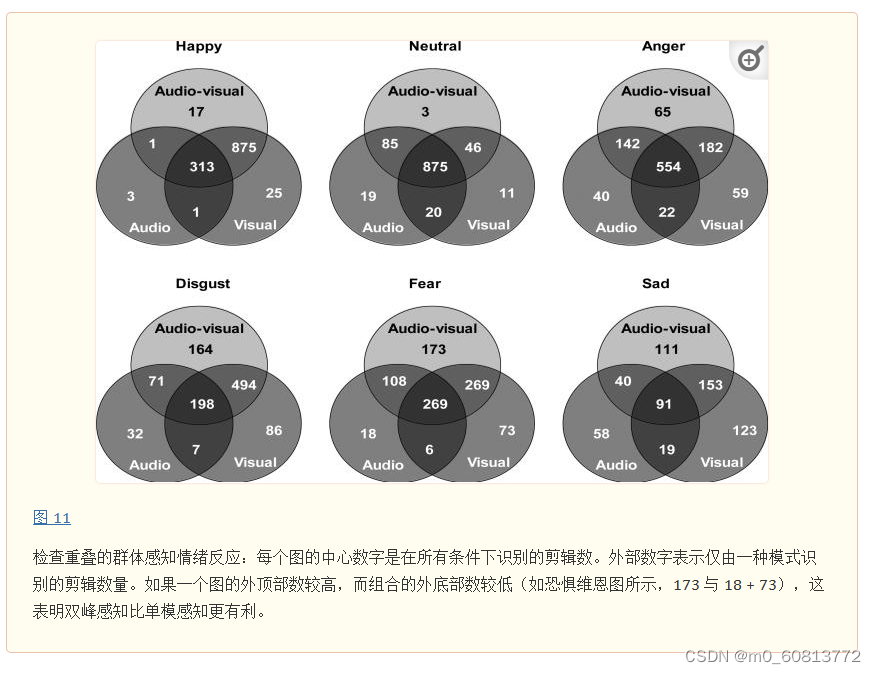
对于每种情绪,都有一个维恩图,见图 11。每个圆圈内的4个数字之和,是该模态剪辑的总数。例如,分别有 318、952 和 1206 个剪辑在纯音频、纯视觉、音频+视觉模态中被感知为快乐。此外,在 1235 个感知为快乐片段中,只有 45 个仅在一种模态中被感知到。
参考图 11,我们首先注意到视觉模态对于准确感知快乐的情绪至关重要。然后,中性和愤怒,大部分剪辑(每个图的中心编号)在所有模态中都被检测到了,这表明用于感知中性和愤怒的大部分信息在多模态中存在冗余。另一方面,厌恶和恐惧从多模态感知中受益最大,因为它们在所有模态中都能检测到的剪辑比例要小得多,而只能在视听模态中检测到的剪辑比例相对较大。最后,每种模态对 sad 都很重要,因为 三个模态都能检测到sad的剪辑数量与只在单个模态中能检测到sad的剪辑数量几乎相同。
6. 讨论与结论
CREMA-D是用于多模态情绪研究的最新数据集。我们已经描述了这个数据集的创建,其中包含演员目标情绪和标注者感知情绪的评级。我们使用众包作为收集感知评级的一种方式。CREMA-D 在每种模态(纯音频、纯视频、视听)中都有超过 7 个标注者,在 7,442 个剪辑中,超过 95% 的剪辑涵盖了 12 个句子,涉及 6 个不同的情绪类别(快乐、悲伤、愤怒、恐惧、厌恶和中性)。这使得 CREMA-D 在考虑情绪的视听感知问题时成为极好的资源。每个片段都提供了群体感知的情绪,我们使用二项式多数检验群体感知,并将演员目标情绪与群体感知情绪进行比较,进一步创建了三个子集(匹配、不匹配、模糊)。
在这三个子集中,该数据集包含了从模糊情绪到基本情绪,从微妙情绪到极端情绪的广泛情绪表达。我们还根据个人评级、不同模态、群体评级提供了详细的情绪感知分析。
以多种方式测试了每种模态下的情绪识别。音频是最难识别的,视觉在中间,视听是最容易识别的。当我们考虑个体标注者、群体情绪感知的整体表现时,这两者都成立。但是,当我们考虑个别情绪或个别标注者时,也有一些例外。例如,音频和视觉在愤怒时表现出相似的表现,而视觉和视听在快乐和悲伤方面没有显着差异。另一方面,就不同标注者的情绪识别表现而言,我们也注意到大约20%的标注者对音频刺激的识别率最高。
在观察个体情绪感知的一致性时,可以看到纯音频、纯视觉和视听的低-中-高顺序是一贯的。情绪识别准确率与情绪表达强度之间似乎也存在相关性。在每种模态下,具有极端强度情绪的剪辑比那些温和强度的剪辑识别准确率高25%以上。同样地,低-中-高顺序(音频-视觉-视听)在每个强度箱中都保持不变。
在标注者的响应时间方面,我们观察到视听和视频模式的响应速度明显快于音频。尽管视频和视听的平均响应速度相当,但我们注意到视听感知的特快速响应(<1s)的比例更大。最后,对于每种模态中的感知,我们没有观察到刺激的先后播放顺序对识别率的影响。
我们进一步研究了各种模态的相互作用。我们观察到,某些模态最擅长传达特定的情感。对于快乐来说,超过70%的片段由视觉模态主导,其余30%的片段要靠音频和视觉的冗余信息来识别快乐。对于中性,大多数剪辑都具有冗余信息(参考图 11的中性情绪的中心计数),并且少数剪辑的视觉模态占主导地位(视觉和视听重叠)或音频模态占主导地位(音频和视听重叠)。对于愤怒、厌恶、恐惧和悲伤,所有模态都会做出一些贡献,我们没有观察到明显的首选模态。也存在不同程度的冗余、视觉优势、音频优势和互补性的情况。跨模态检查单个剪辑,可以进一步深入了解这些问题。这是为未来预留的,可用于特定情绪驱动假设的研究。
这个最新开发的数据集,有应用于更多情绪研究的潜力,比如量化研究性别、年龄、种族等对情绪表达的产生和感知的影响。我们进行了一些试点研究,并观察到女性在清楚地表达情绪和准确识别演员目标情绪方面都优于男性。这与早期的一项研究结果一致,该项目使用语音模态研究了情绪检测中的性别差异[4]。将来可以进行更详细的研究。
总之,我们呈现了可以在 CREMA-D 上进行的情绪分析的示例,并发现了每种模态下与情绪表达相关的差异。这些差异允许该数据集的用户根据需要分离数据。标签包括演员目标情绪和群体感知情绪以及群体感知的情绪强度。标签和模态的多样性旨在使该数据集易于访问并可用于各种目的。这种情绪分析肯定不是面面俱到的,其目的是展示数据集的应用范围以及可以基于它的大量情绪分析。我们计划很快将数据集发布给学术界,用于研究目的。研究人员可以根据研究的需要自由地将他们选择的最佳方法应用于该数据集。

















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









