






An Assessment of In-the-Wild Datasets for Multimodal Emotion Recognition
摘要:
多模态情感识别意味着使用不同的资源和技术来识别和识别人类的情感。各种数据源,如人脸,语音,语音,文本和其他必须同时处理这个识别任务。然而,大多数主要基于深度学习的技术都是使用在受控条件下设计和构建的数据集进行训练的,这使得它们在具有真实的条件的真实的上下文中的适用性更加困难。出于这个原因,这项工作的目的是评估一组野外数据集,以显示它们在多模态情感识别方面的优势和劣势。评估了四个野外数据集:AFEW,SFEW,MELD和AffWild2。使用先前设计的多模式架构来执行评估,并使用诸如准确性和F1分数等经典指标来测量训练中的性能并验证定量结果。然而,用于各种用途的这些数据集的优点和缺点表明,由于它们的原始目的,它们本身不适合多模态识别,例如,面部或语音识别。因此,我们建议多个数据集的组合,以便在处理新样本时获得更好的结果,并按类别平衡样本数量。
1.introduction
识别情绪的能力在许多使用人类情绪反应作为营销,技术或人机交互信号的工作领域中至关重要[1]。已经提出了不同的模型用于情感分类或归类[2]。最常见的是建立六个类别,如喜悦,爱,惊喜,悲伤,愤怒和恐惧[3]或包括厌恶代替爱的组合[4]。其中一个最被接受的分类是埃克曼的模型。这个模型的前提是有不同的面部表情。在过去的50年里,他们的标签被大多数已发表的面部推理研究广泛使用[5]。一些作者还包括中性情绪[6,7]。
自动情感识别(ER)是一个吸引了大量兴趣的研究课题。这包括从面部表情、语音和文本等信号中识别人类情感的实践[8]。通常会考虑各种信息源,因为人们自然地以同时不同的方式表达情感,例如面部表情[9]或其他类型的手部或手臂姿势[10],或姿势[11],所有这些都与交互环境有关[12]。当使用不同的ER模态时,这种处理被称为多模态ER [13]。由于每个源本身都可以产生ER,因此这些结果的融合可以减轻某些单源方法的局限性,从而获得更准确的检测[14]。
深度架构和学习技术已经证明了多模态ER [15—17]和情感分析[18]的有效性。有效地,深度学习支持ER的可定制结构,允许高级别的数据抽象。深度学习技术,深度神经网络用于从高级数据表示中收集区别特征[19]。最常见的技术包括长短期记忆(LSTM)[13,20],卷积神经网络[21,22],全连接多层感知器(MLP)[23],递归神经网络(RNN)[24],自动编码器[25]和卷积深度信念网络[26]。
这些架构已经使用多模态信号(如面部和音频手势,音频和书面语言,生理信号以及这些模态的不同变化)进行了ER训练[27]。一些工作集中在图像(面部,姿势),音频(语音)和文本模态融合融合的融合方法[20,23,28]。
其他作品考虑生理信号[21,22,24,25],还有其他作品包括所有这些模态的组合[26]。深度学习技术在计算机视觉应用中发展迅速,以解决检测,定位,估计和分类问题[29]。[30]介绍了一种基于嵌入的深度学习方法,用于3D细胞实例分割和跟踪,以同时学习空间,时间和3D上下文信息。该方法也用于[31]中的人脸识别,使用伪RGB-D(红色,绿色,蓝色深度)框架并提供数据驱动的方法来从2D人脸图像生成深度图。在[32]中,通过一个简单的复合图形分离框架解决了从复合图形中提取和管理单个子图的问题,该框架使用来自单个图像的弱分类注释。开发了面部识别方法的深度迁移学习,以探索从不受控制的2D面部图像中识别疾病[33]。深度学习已经成功地与数据增强技术相结合,为无线电信号的频谱引入不同强度的干扰[34]。
如图所示,多模态ER在情感计算研究社区中变得越来越流行,以克服仅处理一种类型的数据所施加的约束,并提高识别鲁棒性[22]。然而,尽管在大量研究中显示了使用深度学习技术的ER的进展,但其中大多数使用在实验室环境中构建的数据集,例如IEMOCAP [20,23],AMIGOS [24],RECOLA [28],DEAP [21],SEED,SEED-IV,SEED-V,DEAP和DREAMER [25]。任何识别系统的基本问题是缺乏数据或使用真实的数据进行训练,这可能会影响其对训练过程中未见过的示例的泛化[21,35]。此外,用于ER模型训练的数据集是在受控的实验室环境中设计的,并且在亮度、噪声水平等方面与真实的条件下发生的情况显著不同。大多数现有的方法在实验室控制的数据集上显示出良好的识别准确性,但在现实世界的不受控制的环境中,它们的准确性要低得多。与之相比,来自非受控环境的数据集也被称为“野外”数据[37]。机器学习社区已经接受,当在无约束条件下收集大量数据集时,特定应用领域的进展会大大加速[38,39]。有了这些数据,多模态分析可以专注于自发行为和在无约束条件下捕获的行为[40]。
因此,这项工作的目的是评估一组野外数据集,以显示它们在多模态情感识别方面的优势和劣势。将评估四个野外数据集:AFEW,SFEW,MELD和AffWild 2。这项工作的主要贡献如下:·---回顾了使用野外数据集的不同工作。这篇综述包括近年来关于多模态情感识别方法及其实验中使用的数据集的工作。还提供了这些数据集的详细描述。·
----对我们研究所选的四个数据集进行描述性分析。该描述包括情感的频率分布、一些样本的可视化以及与原始提取源相关的细节。
·---使用一系列深度学习架构和融合方法进行性能评估。这些测试包括消融实验,根据形态和融合结果报告个别结果。
这项工作分为几个部分。第二节介绍了关于使用野外数据集进行情绪识别的不同研究。第3节介绍了选定的野外数据集。第4节简要描述了用来评估数据集的体系结构。第5节介绍了使用深度学习体系结构集成的野外数据集的训练过程的结果。第六节讨论了主要成果和建议,最后第七节给出了结论和未来的工作。
2.相关工作
情感计算主要是一个数据驱动的研究领域,以自建或公共数据库和数据集为基础。大多数可用的数据都是在实验室中收集并存储在受控条件下的。然而,现有的在现实世界条件下收集的多通道情感数据库很少,而且现有的数据库很小,通常只有有限数量的受试者,用一种语言表达[41]。这项工作的回顾主要集中在在野外条件下收集的一些最后的数据集。
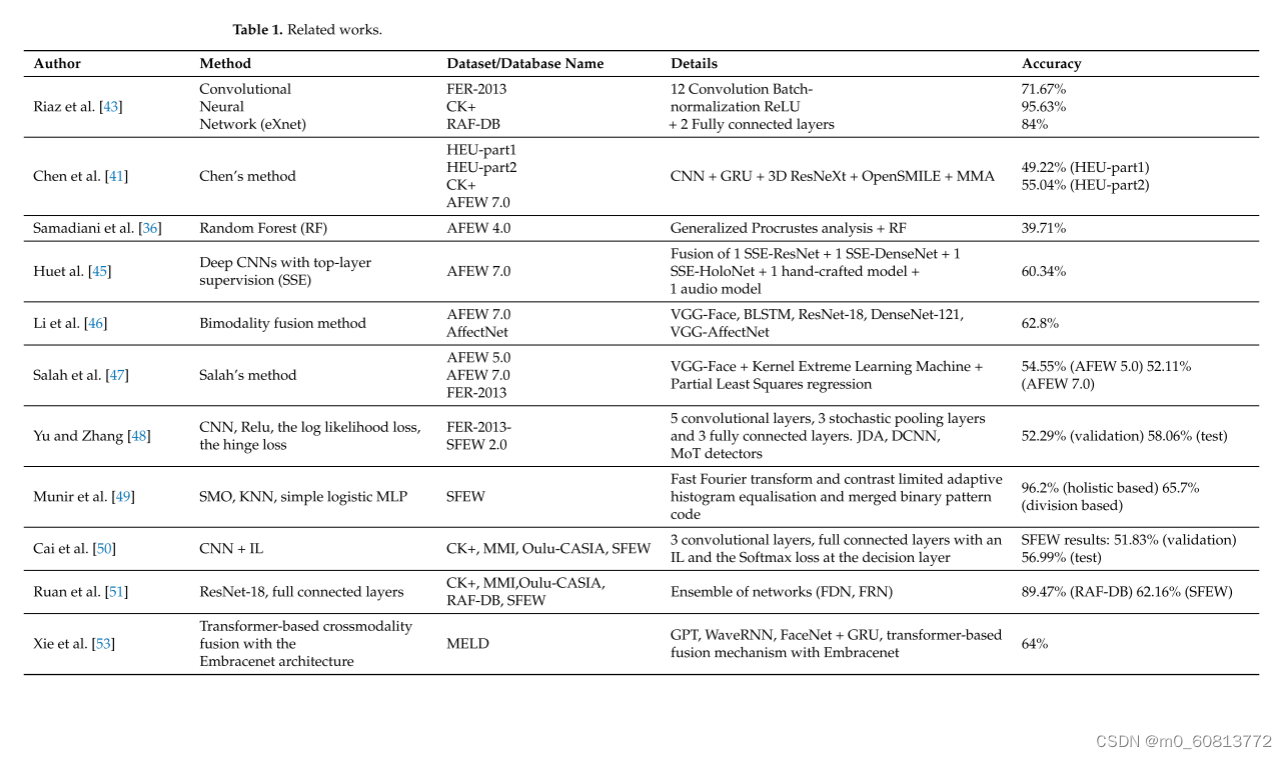
在面部情绪识别[42]和多模式方法的背景下开发的一些项目已经使用或创建了自己的数据集用于实验。Riaz等人。[43]在面部表情识别2013(FER-2013)、扩展CohnKanade数据集(CK+)和真实世界情感面孔数据库(RAF-DB)基准数据集上进行了测试。该实现被作者称为eXnet(Expression Net),由一个基于并行特征提取的卷积神经网络(CNN)架构组成,用于野外的面部情感识别(FER)。该方法在所研究的数据集上取得了较高的准确率(FER-2013为71.67%,CK+为95.63%,RAF-DB为84%),同时与其他方法相比,该方法使用的参数数量更少,磁盘空间更小。Chen等人[41]在HEU-Part 1和HEU-Part 2情感数据库上,提出了多通道注意模块(MMA)对多通道特征进行自适应融合。HEU EGM运动数据库总共包含19,004个视频剪辑,分别标记为10种情绪(愤怒、无聊、困惑、失望、厌恶、恐惧、快乐、中立、悲伤、惊讶)。用CNN+GRU、3D ResNeXt和OpenSMILE提取人脸、身体和音频的原始特征,并与MMA相结合。在AFEW和CK+数据集上进行了对比测试。对于HEU-Part 1和HEU-Part 2,使用所有模式和建议的MMA的最佳结果分别为49.22%和55.04%。
野外情绪识别挑战(EMotiW)是作为多个国际多模式交互会议的重大挑战而运行的一项标杆努力。从2012年开始的不同版本涉及到野外ER的不同任务[44]。在情感计算、计算机视觉、语音处理和机器学习方面开展了各种研究项目。下面总结了在这些领域提出的一些最好的工作。Samadiani等人。[36]提出了一种在Wild(AFEW)4.0数据集上结合视觉和音频特征的视频ER。针对野外拍摄的视频中头部所构成的挑战,提出了一种特征提取方法。采用稀疏核表示进行特征拼接,并用联合稀疏集中指数度量作为决策策略来表示通道的有效性。使用随机森林分类器对七种基本情绪(愤怒、厌恶、恐惧、高兴、中性、悲伤和惊讶)进行分类,准确率为39.71%。Hu等人。[45]使用AFEW 7.0在EMotiW 2017基于音频-视频的ER子挑战赛中进行了实验。为此,作者提出了一个监督得分合奏,它在深度CNN的不同特征层中提供密集的监督,并为二级监督的班级得分激活架起桥梁。它通过增加对深、中、浅三层的监管,扩展了深度监管的理念。之后,一种融合结构将来自不同互补特征层的分类评分激活串联在一起。此子挑战的ER任务的最高正确率为60.34%。Li等人。[46]提出了一种基于视频的自然ER框架,该框架从面部表情序列中获取视觉信息,从音频中获取语音信息。这是在基于音频-视频的EMotiW 2019 ER子挑战赛AFEW 7.0的背景下完成的。使用不同的深层网络(VGG-Face、BLSTM、ResNet-18、DenseNet-121、VGG-AffectNet),并采用基于加权和的融合方法对网络输出进行融合。此外,为了利用面部表情信息,VGG16网络在AffectNet数据集上进行训练,以学习专门的面部表情识别模型。最好的融合结果表明融合后的准确率为62.78%。Salah等人。[47]提出了一种基于深度迁移学习和分数融合的基于视频的野外ER方法,并结合2015年和2016年的EMotiW挑战赛。对于视觉通道,该方法总结了互补视觉描述符的功能;对于音频通道,提出了一种用于副语言学的标准计算流水线。将听觉和视觉特征与基于最小二乘回归的分类器和加权分数级融合相结合。使用的数据集与AFEW语料库和FER-2013相对应。该方法的准确率分别达到了54.55%和52.11%。
一些关于ER in-the-Wild Challenges(EMotiW)子挑战的研究主要集中在SFEW(Static Face Expression In Wild)数据集上将一组静态图像自动分类为七种基本情绪。SFEW是AFEW的静态子集,解决了识别更自发的面部表情的问题。Yu和Zhang[48]提出了一种基于三个人脸检测器集成的人脸检测模块和多个深卷积神经网络集成的分类模块的方法。这三个检测器是联合级联检测和比对(JDA)、基于Deep-CNN的(DCNN)和树木的混合(MoT)。预先训练的模型在2013面部表情识别(FER)挑战赛提供的一个更大的数据集上执行,然后在SFEW 2.0的训练集上进行微调。该方法在SFEW 2.0的验证和测试集上分别达到了55.96%和61.29%,超过了挑战基线的35.96%和39.13%,并获得了显著的收益。Munir等人[49]提出了一种基于快速傅立叶变换(FFT)和对比度受限自适应直方图均衡化(CLAHE)的二值模式编码方法,该方法由三个主要模块组成:(A)快速傅立叶变换(FFT)和对比度受限自适应直方图均衡(CLAHE)方法;(B)按像素生成合并的二进制模式码(MBPC);(C)利用主成分分析(PCA)和分类器进行降维。选择SFEW数据集进行实验。结果表明,整体法和基于分区的方法的准确率分别为96.5%和67.2%。蔡等人。[50]设计了一种新的孤岛损失算法(IL-CNN),同时提高了类间可分离性和类内紧致性。该方法包括三个卷积层,每个卷积层之后是PReLU层和批归一化层(BN)。在前两个BN层中的每一个之后使用最大分组层。在第三卷积层之后,包括两个全连通层(FC)和一个Softmax DRMF。Ruan等人。[51]提出了一种用于人脸ER的网络集成,由四部分组成:(A)提取基本CNN特征的骨干网络(ResNet-18);(B)将基本特征分解为一组潜在特征的特征分解网络(FDN);(C)特征重构网络(FRN),其学习每个潜在特征的特征内关系权重和特征间关系权重并重构表情特征;FRN包括两个模块:特征内关系建模模块(Intra-RM)和特征间关系建模模块(InterRM);(D)预测表情标签的表情预测网络(EPN)。实验结果在实验室内数据库(包括CK+、MMI和Oulu-CASIA)和野外数据库(包括RAF-DB和SFEW)上获得。RAF-DB和SFEW的准确率分别为89.47%和62.16%。
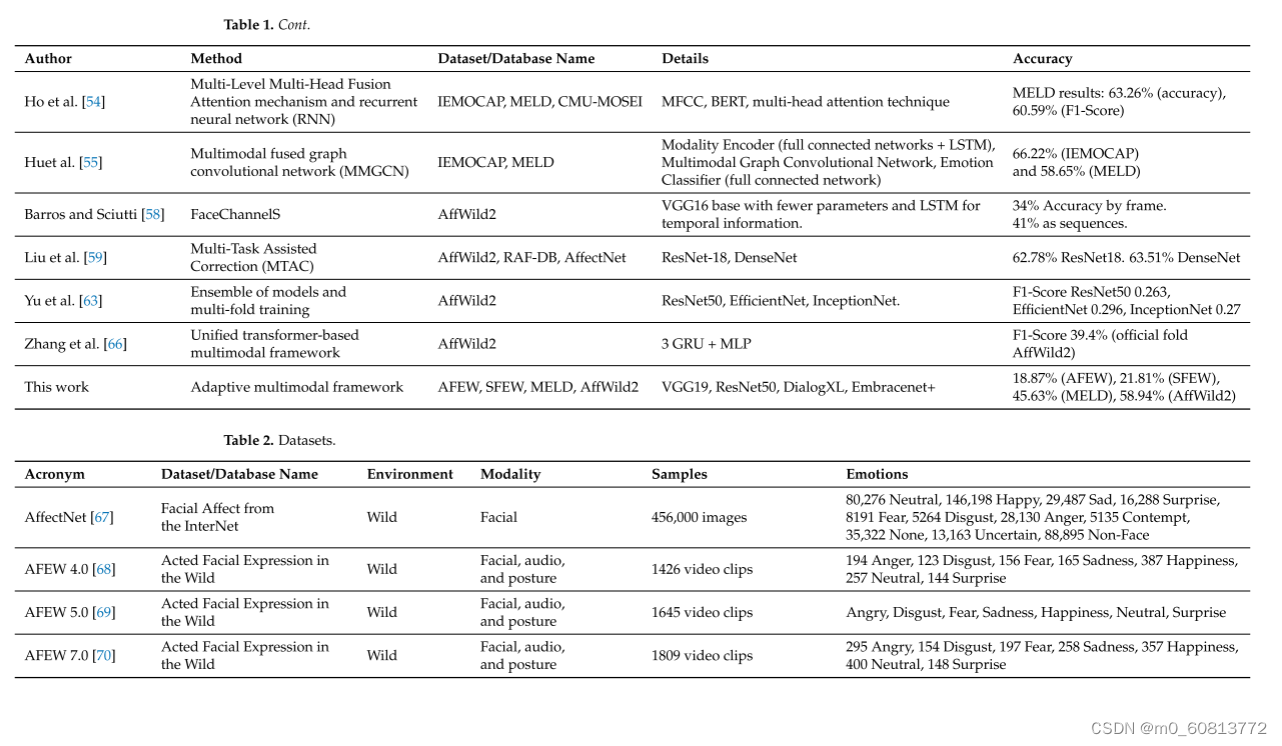
会话中的情感识别(ERC)是最近因其潜在的应用而引起人们兴趣的另一个具有挑战性的任务。自然形式的对话是多模式的。ERC提出了几个挑战,如对话语境建模、对话者的情绪变化以及其他使任务更难解决的问题[52]。谢等人[53]提出了一种基于多通道情感线数据集(MELD)的多通道情感分类框架,包括文本、音频和人脸三种通道。利用产生式预训练转换器(GPT)对文本、音频和FaceNet+GRU三种不同的预测模型进行训练。采用了一种基于变压器和环抱的融合机制来提供多通道特征融合。该体系结构既考虑了模式之间的联合关系,又融合了表示向量的不同来源。结果显示,准确率为65.0%,F1评分为64.0%。Ho等人。[54]提出了一种基于多层多头融合注意机制和递归神经网络的多通道语音情感识别方法。使用OpenSMILE工具箱从原始信号中提取的Mel频率倒频谱(MFCC)用于确定音频特征。使用来自变压器的双向编码器表示的预训练模型(BERT)来嵌入文本信息。一种融合了所有特征表征的多头注意技术。实验在三个数据库上进行,分别是交互式情绪运动捕捉(IEMOCAP)、MELD和CMU多模式意见情绪和情绪强度(CMU-MOSEI)。结果显示,准确率为63.26%,F1Score为60.59%。Hu等人。[55]提出了一种利用多通道和远距离上下文信息的多通道融合图卷积网络(MMGCN)。MMGCN由三个关键部分组成:通道编码器、多模图卷积网络和情感分类器。实验是在两个公共基准数据集IEMOCAP和MELD上进行的。结果表明,IEMOCAP和MELD的准确率分别为66.22%和58.65%。
第一次野外影响挑战(AffWild Challenges)是与2017年计算机视觉和模式识别会议(CVPR)联合举办的,使用的是AffWild数据库[56]。后来,这个数据库扩展了260多个主题和1,413,000个新的视频帧,此后它被称为AffWild2[57]。自那以后,一些研究人员对AffWild2进行了实验。Barros和Sciutti[58]实现了一个基于VGG16的深度神经网络,该网络具有一个最终的特征层,该层对唤醒、价位和情绪类别进行分类。这也被扩展到处理顺序数据,并获得了0.38的F1分数。刘等人。[59]提出了一种提取面部特征并应用正则化的框架,以聚焦于更明显的样本,同时对更不确定的表情进行重新标记。该框架使用ResNet-18[60]和DenseNet[61]架构,使用MS-Celeb-1M数据集[62]进行预训练,平均准确率达到62.78%。Yu等人。[63]提出了一种集成学习方法,使用ResNet、EfficientNet[64]和InceptionNet[65]等不同的体系结构,并在数据之间进行多折叠训练,以提高其性能。这使得F1的平均成绩达到了0.255分。张某等人。[66]提出了一种统一的基于变压器的多通道动作单元检测和表情识别框架。该框架由三个门控递归神经网络(GRU)和一个多层感知器(MLP)组成。采用基于变换的融合模块对静态视觉特征和动态多通道特征进行融合。计算了在六个不同折叠上训练和测试的模型的表达式F1分数(包括AffWild2数据集的原始训练/验证集)。结果显示,每一次的F1-得分分别为39.4、37.9、41.1、37.8、37.3和36.1。
表1总结了本节介绍的工作。表2总结了这些作品中使用的数据集或数据库。
3.野外数据集的选择
我们选择了四个野外数据集进行测试:Few[68]、SFEW[68]、MELD[52]和AffWild2[57]。之所以选择这些数据集,主要是因为它们具有可访问性。访问请求是直接向其作者提出的,访问是出于学术目的批准的。下面是对每个数据集的描述。
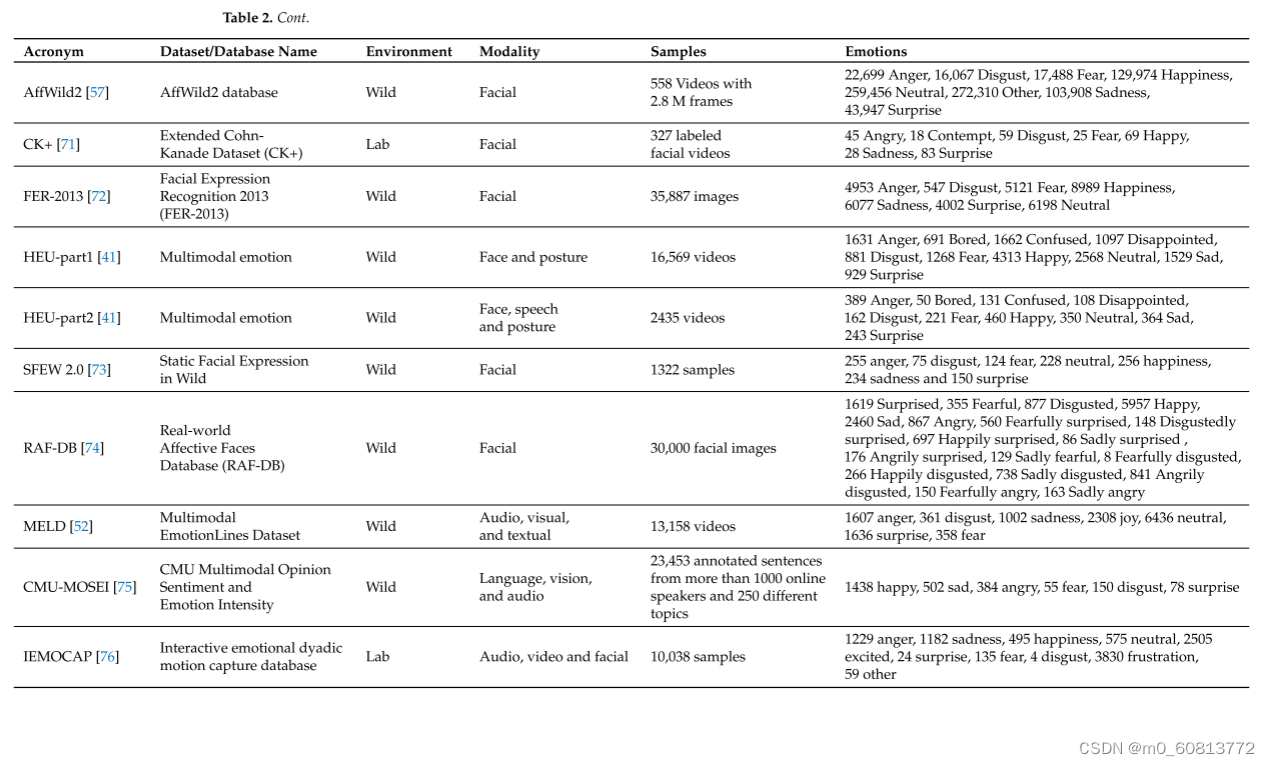
·-----AFEW:这是一个由A.DHall等人提出的动态时间面部表情数据库。2011[77]年。自2013年以来,它一直被用作野外挑战(EMotiW)中的情感识别数据库。每一次挑战每年都会出现不同的版本。为简单起见,下面将最新版本称为AFEW。它由接近真实世界的环境实例组成,从电影和真人秀节目中提取,包括1809个300-5400毫秒的视频剪辑,具有各种头部姿势、遮挡和照明。该数据库包含了从1岁到70岁的大范围的主题,来自不同的种族、性别和年龄,并且在一个场景中有多个主题。大约330名受试者被贴上了姓名、角色年龄、演员年龄、性别、姿势和个人面部表情等信息。Few由单独的训练(773)、验证(383)和测试(653)视频片段组成,其中样本被贴上不同的情感标签:六种普遍的情感(愤怒、厌恶、恐惧、高兴、悲伤和惊讶)和中性。音频和视频采用WAV和AVI格式。在这个数据库中探索的模式包括面部、音频和姿势。图1显示了此数据集中的一些示例。每种情绪都由一组短视频表示,不同的演员在不同的情况下展示这种情绪,例如,一个人的脸显示出愤怒(图2)。应该注意的是,测试文件夹不包含按情感分类的视频,并且视频的质量是不同的,有些包含具有不同图像质量级别的场景(图3)。该数据集的官方网站是澳大利亚国立大学计算学院(https://cs.anu.edu.au/few/,,2023年5月27日访问)。
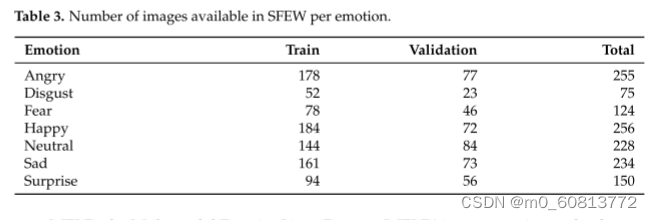
------·SFEW:创建了一个野生静态面部表情数据库(SFEW),其中包含从AFEW提取的面部表情的帧。该数据库包括不受限制的面部表情、不同的头部姿势、大的年龄范围、遮挡、不同的焦点、不同的面部分辨率和接近真实世界的光照。提取的帧根据AFEW中序列的标签使用两个独立的标签器进行标记,其中包含六个基本表情:愤怒、厌恶、恐惧、高兴、悲伤、惊讶和中立。它由1766幅图像组成,其中958幅用于训练,436幅用于验证,372幅用于测试。每个图像都被分配到七个表情类别中的一个,中性和六个基本表情。训练和验证集合的表达标签被提供,而测试集合的表达标签被挑战组织者保留。[73][中英文摘要]。图4显示了该数据库的一些示例。该语料库是在野外广泛使用的面部表情识别基准数据库。官方网站与AFEW相同。表3显示了SFEW中每个情感可用的图像数量。


· ------MELD:多模态平行线数据集(MELD)是平行线的扩展和增强[78]。MELD语料库是通过提取从每个对话的开始和结束时间戳的所有话语在predictionLines数据集,给定的时间戳的话语在对话中必须在一个递增的顺序和对话中的所有话语必须属于相同的情节和场景。在获得每个话语的时间戳之后,从源片段中提取相应的视听片段,然后从这些片段中提取音频内容。音频文件被格式化为16位PCMWAV文件。最终的数据集包括每个话语的视觉、音频和文本模态。MELD包含来自电视剧《老友记》中1433个对话的大约13,000个话语,不同的说话人参与了这些对话。它提供了多模态源,不仅包括文本对话,而且还包括相应的视觉和听觉对应物。每个话语都用情绪和情感标签进行注释。 对应于Ekman的六种普遍情绪(快乐,悲伤,恐惧,愤怒,惊讶和厌恶),并带有一个额外的情绪标签中性。对于情绪,分为三类:消极,积极和中性[52]。图5显示了该数据集的摘录。每个帧都是从视频中收集的提取物,其中大多数帧包含几个表达不同情绪的人(图6)。该数据集仅包含完整视频帧的原始数据;不会裁剪或标记单个人脸。在MELD网站(https://github.com/martre—lab/MELD,2023年5月27日访问)中,数据被结构化在不同的文件夹中。特别是在data文件夹中,有三个不同的CSV文件,分别对应于9990、1110和2611行的train、dev和test数据集。每个文件具有相同的结构,包含话语、说话者、情感和情绪信息,以及与源有关的数据。

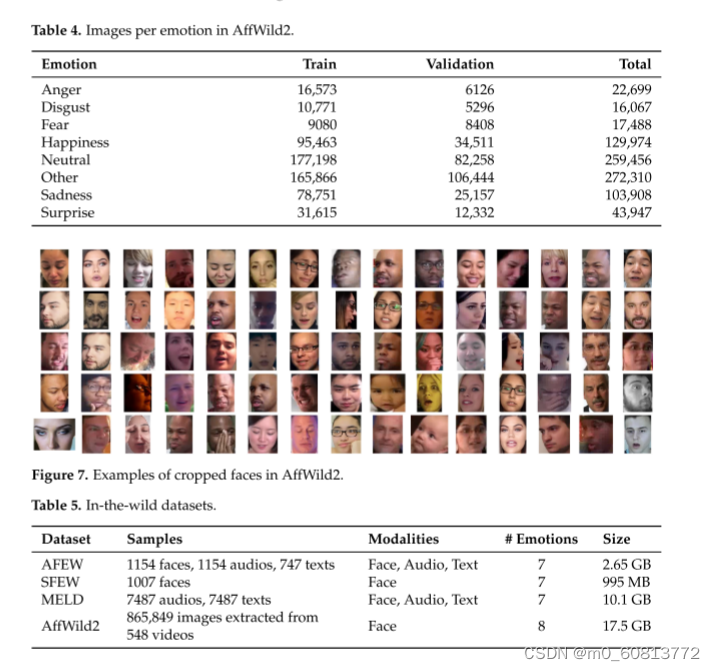
---AffWild 2:这是AffWild数据集的扩展,专为First Affect-in-the-Wild Challenge [79]设计。AffWild收集了YouTube等视频分享网站上的数据,以及显示人们情感行为的选定视频,例如,显示人们在观看预告片、电影、令人不安的剪辑或对恶作剧的反应时的行为的视频。它旨在训练和测试端到端的深度神经架构,用于基于视觉线索估计连续情感维度[56],并根据valencearousal维度进行注释。共收集了200名受试者的298个反应视频,视频总时长超过30 h。后来,AffWild 2扩展了数据,增加了260个受试者和1,413,000个新视频帧[57]。这些视频是从YouTube上下载的,在姿势、年龄、照明条件、种族和职业方面有很大的差异。该系列包含558个视频,共有280万帧,其中包括人们对事件或视听内容的反应或对着相机说话。这些视频涉及广泛的主题的年龄,种族和职业,他们有不同的头部姿势,照明条件,遮挡和情绪。视频经过处理、修剪并重新格式化为MP4。框架被注释为三个任务(效价唤醒,情绪分类和动作单元检测)[80]。该数据集也作为来自每个视频的一组裁剪帧分布,以面部为中心。可用图像数量见表4。对于情绪分类,每个帧都用六种主要情绪(愤怒,厌恶,恐惧,快乐,悲伤,惊讶,其他)之一和中性情绪进行注释。对于此任务,某些帧被标记为已丢弃(带有"—1")。AffWild2的官方网站属于伦敦帝国理工学院计算系的智能行为理解小组(iBUG)(https://www.example.com resources/aff—wild2/,于2023年5月27日访问)。图7显示了来自AffWild2数据集的一些样本。表5总结了这些野外数据集的一些见解。
3.1.预处理
在本节中,我们将按模态组描述用于预处理四个数据集的步骤。
3.1.1.人脸模态
对于这种模式,AFEW、SFEW和AffWild 2提供了每个视频帧的裁剪和居中片段,并在屏幕上显示受试者的标记面部。图1、图4和图7示出了利用面部检测算法从其原始视频源提取的一些帧。
由于AFEW和SFEW按情绪分布在不同的文件夹中,因此我们创建了一个CSV文件,其中包含每个帧的路径及其标签。在AffWild 2数据集中,每个视频都有相应的注释文件。这些文件中的一行指示每个帧的标签。这些视频中很少有超过一个人的焦点。在这些情况下,视频有几个注释文件(每个人一个),每个注释文件都有一个对应于它所指的人的标签。图8显示了一个例子。所有缺少类别标签的帧都被标注为-1,表示该帧应该被丢弃。

MELD不提供每个字符的裁剪图像,因为此数据集侧重于音频和文本分类。许多样本一帧一帧地包含多个人,因此我们从每个视频中提取每个角色的裁剪面部。然后,将每个人物的帧与对应的标记对话框进行匹配,以便标记这些帧。我们从每个视频中对少量帧进行了二次采样,获得了大约3711张图像,以便微调VGGFace架构,以识别这些作物中的每个主题(情景喜剧《老友记》中的角色)。该分类器达到了99.87%的准确率。最后,我们将视频中的每个人物与它们标记的情感进行匹配,根据其预测中超过70%确定性的分类器概率阈值,从每个样本中选择识别最好的人物。然后,我们将这些样本保存在一个文件夹中,每个图像都通过其文件名进行标识,格式为Result_dia[ID]_Utt[ID].[n].png,其中dia和utt对应于数据集标签的CSV文件上的对话和话语编号,ID是来自相应视频的ID代码,n是来自该视频的特定人物的帧数量。此裁剪过程的结果如图9所示。

为了生成一组不同的图像用于训练,我们对训练数据进行了一些随机增强操作。这些操作意味着修改图像的转换,这些转换有50%的机会被应用。变换包括翻转[-10,10]度范围内的旋转,随机对比度和亮度或添加泊松噪声;所有这些都是独立应用的。
由于用于此模态的VGG模型需要定义输入大小,因此我们必须使用Python中scikit-image库提供的双线性插值函数将原始图像(AFEW中为128 × 128像素,SFEW中为181 × 143像素,AffWild 2中为246 ± 176 × 128 ± 129像素)调整为48 × 48像素。
3.1.2.音频模态
对于音频数据,我们首先使用ffmpeg [81]在所有数据集上以22.4 kHz的采样率提取每个原始视频的音频。
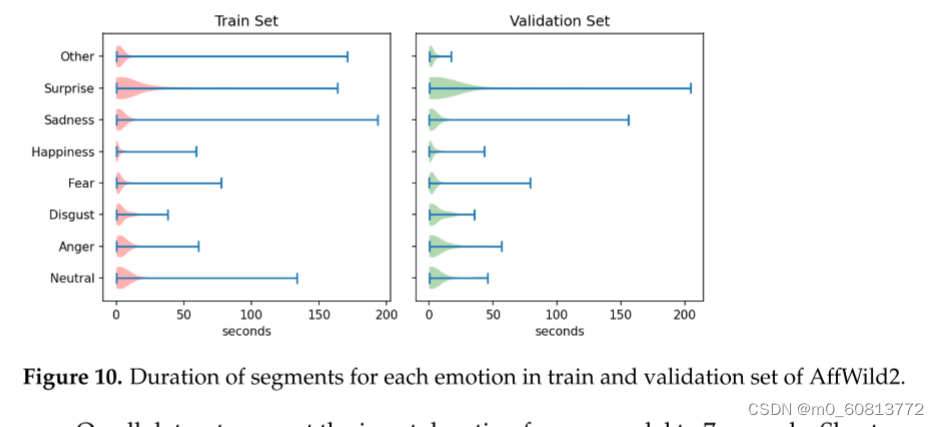
特别地,AffWild 2中的每个视频包含多个标记的情感话语,其定义视频片段。使用Librosa [82]从这些片段中提取音频片段,并使用与其对应的话语相同的情感进行标记。这些片段的平均持续时间为3.88 ± 10.18 s,长度在30 ms(一帧视频)和200 s之间。图10显示了训练集和验证集上每种情绪的长度分布。在其他数据集上,每个视频样本表示单个话语;因此,可以直接使用每个样本中的音频。每个音频项的持续时间最长为6.8 s(平均2.458 ± 1.017 s)。
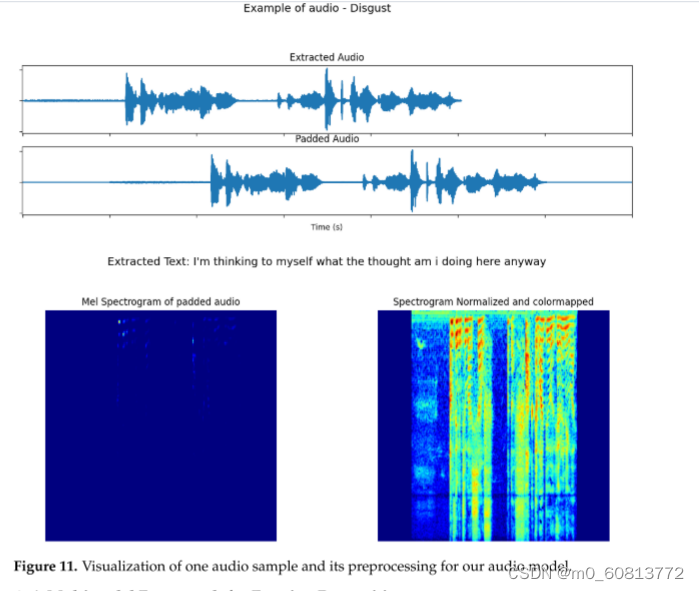
在所有数据集上,我们将模型的输入持续时间设置为7秒。较短的片段用零填充并居中(图11中的第二个图),而较大的片段从随机开始位置被剪切到7秒。然后,使用Librosa(图11中的左下角图像)将片段转换为MEL光谱图,将比例转换为分贝(使用Librosa.power_to_db()),最后将其归一化到范围[0-1]并进行颜色映射,以将幅度信息编码为图像中的颜色,如Lech等人的工作所建议的那样。[83][老外谈]。图11显示了此过程。为了进行训练,每个音频样本都增加了距填充音频中心的随机位移以及σ=1×10−5.的高斯噪声。
3.1.3文本模态
对于文本模型,我们使用先前从视频中提取的相同音频片段,不进行时长标准化,并使用SpeechBrain[84]EncoderDecoderASR Transformer模型将其转换为文本。图11显示了提取的文本的一个示例。对于MELD数据集,数据中提供了每个视频样本的音频的转录。因此,我们使用此转录作为文本模型的输入。文本模式数据未应用任何数据扩充。
4.情绪识别的多模态框架
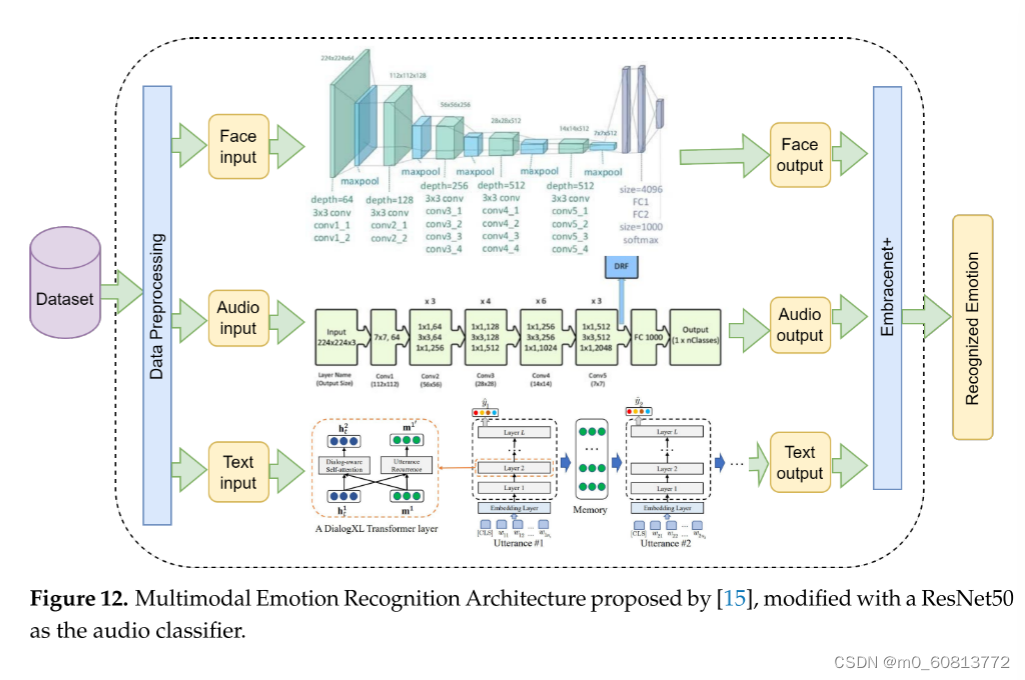
为了评估第3节中提到的野外数据集,我们采用了在以前的工作中设计和实现的架构[15],并进行了微小的修改,详细说明如下。为了支持使用不同模态的情感识别,特别是面部,音频和文本,需要多模态架构。该架构由三个单独的组件组成:基于VGG19网络的面部组件,基于ResNet50的音频组件和基于XLnet的文本组件,称为DialogXL [85]。每个组件单独识别情绪(模态输出)。然后,所有这些输出被融合,产生最终识别的情感。图12显示了该架构的配置。细节总结如下:
-----·面部模态处理。我们使用VGG19架构[86]作为分类器。该模型使用19个卷积层构建,过滤器大小为3 × 3。在每个层有64个通道的2层之后,使用大小为2 × 2的最大池化操作减少输出。这继续交替地汇集2层128个通道、4层256个通道、4层512个通道和4层512个通道。在最后的最大池化操作之后,输出进入MLP网络,该网络具有大小为4096、4096和1000的3个密集层,然后是具有Softmax激活函数的最后一层。
·------音频模态处理。我们使用了从头开始训练的ResNet50架构[60],取代了Venkataramanan和Rajamohan [87]提出的原始架构,该架构用于我们之前的工作。我们的预期输入是一个大小为224 × 224的图像,表示输入音频样本的频谱图。在滤波器大小为7 × 7和64通道的卷积层之后,输入通过许多残差块。这些残差块由滤波器大小为1 × 1、3 × 3和1 × 1的三个卷积层组成,然后将块的输入添加到 块输出,提供更高级别特征的残差信息。在若干组之后,输出被最大限度地池化,从而减小其大小。在ResNet50上,此操作发生在3、4、6和3个ResNet块之后。最后,对输出进行平均汇集,创建一个2048长度的要素矢量。然后,该向量被传递到具有Softmax激活的致密层和输出层。这最后一个输出层有许多神经元,与情绪的数量相对应。这如图12的音频片段所示。
---------·文本通道处理。我们使用了DialogXL[85],这是一个基于XLNet的用于会话中情感识别的PyTorch实现(ERC)。它由一个嵌入层、12个变压器层和一个前馈神经网络组成。DialogXL具有增强的内存以存储更长的历史背景,并具有可识别对话的自我关注组件来处理多方结构。为了更好地对会话数据进行建模,将XLNet的重现机制从语段级别修改为话语级别。此外,在XLNet中,对话感知的自我注意被用来取代普通的自我注意,以获取有用的说话人内部和说话人之间的依赖。说话人的每一句话(句子)都通过嵌入层发送,嵌入层将句子标记化为一系列向量。然后,这种表示被馈送到一堆神经网络中,其中每一层都输出一个向量,该向量被馈送到下面的层中。堆栈的每一层都有一个对话感知自我注意组件和一个话语重复组件。分类标记的隐藏状态和历史上下文在最后一层的末尾通过前馈神经网络被馈送以产生识别的情感。
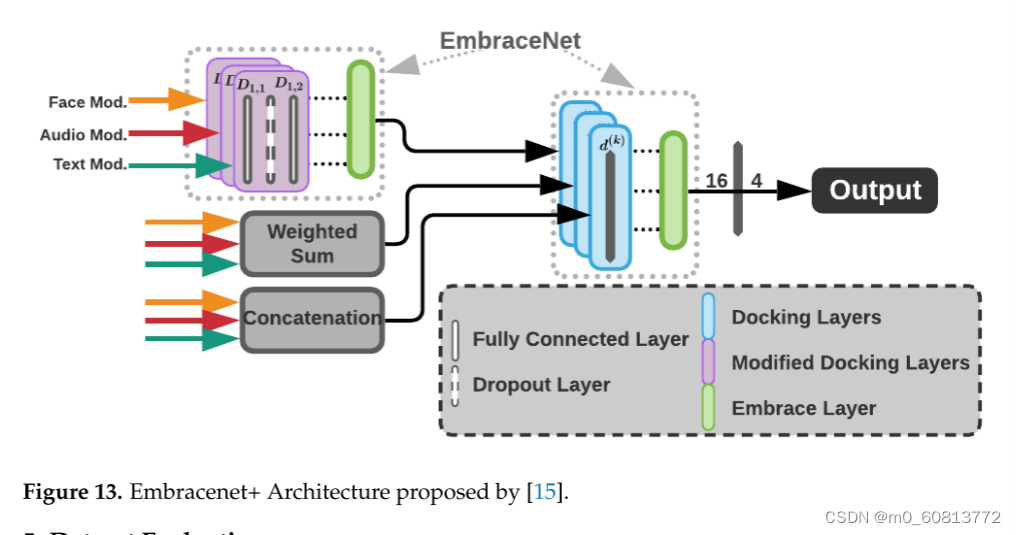
------·融合方法。使用Embrenet+融合单个模式,这是对[15]中Embrenet方法的改进。该体系结构包括三个简单的环状模型,用于改进通道的相关性学习以及最终结果。所使用的每个环带模型都有一个更多的线性层和一个丢弃层,这使得模型稍微坚固一些,以改善学习。图13显示了Embrenet+架构。在它中,一个由32个神经元组成的线性层(D1,1)、一个具有0.5衰变概率的退出层和另一个由16个神经元组成的线性层(D1,2)组成了每个改变的停靠层。此外,使用加权和和串联作为融合技术,其中加权和的输出是n个概率的矢量(n=情感类别的数目),级联的输出是3n的矢量(由于模态的数目)。之后,另一个Embrenet接收三个值为16、n和3n的向量(作为通道工作)。这些向量通过对接每个16个神经元的线性层(d(K))的层来处理,导致额外的n个神经元的线性层,从而输出最终的预测。所有的模式都被训练,批次大小为每步32个样本,20个epoch。
所有的通道都使用ADAM算法进行了优化,学习率为0.0001。该实现基于PyTorch2.0(2023年5月27日访问https://pytorch.org/,)。所有型号都使用配备12 GB VRAM的NVIDIA GeForce RTX 3070进行了图形处理器培训。
使用所描述的框架,在IEMOCAP数据集上进行测试,结果显示对于三种模式的融合,F1得分为79%,准确率为77.6%。在Face-F、Audio-A和Text-T三个独立通道上,模型的平均准确率分别为44%、58.3%和83.5%。
5.数据集评估
表6显示了我们使用AFEW数据集进行测试的结果。我们在人脸、音频和文本模式上的平均准确率分别为26.91%、21.67%和22.19%。在我们的测试中,表现最好的情绪是面部表情的55.208%,音频的33.333%和文本模式的43.750%的愤怒。我们注意到的一个主要问题是,尽管每种情绪的样本没有高度不平衡,但该架构在某些类别中表现不佳。厌恶和惊讶是每种模式中表现最差的。AFEW是用演员的脸建立的,他们有更明显的表情,因此应该更容易区分。图14显示了使用AFEW的三种模态的ROC曲线。在面孔模态中,情绪幸福的AUC为0.61。而对于音频和文本,愤怒是AUC最高的情绪(分别为0.75和0.68)。这可能是由于该集的音频呈现来自专业演员的更详细的语音音调的事实。
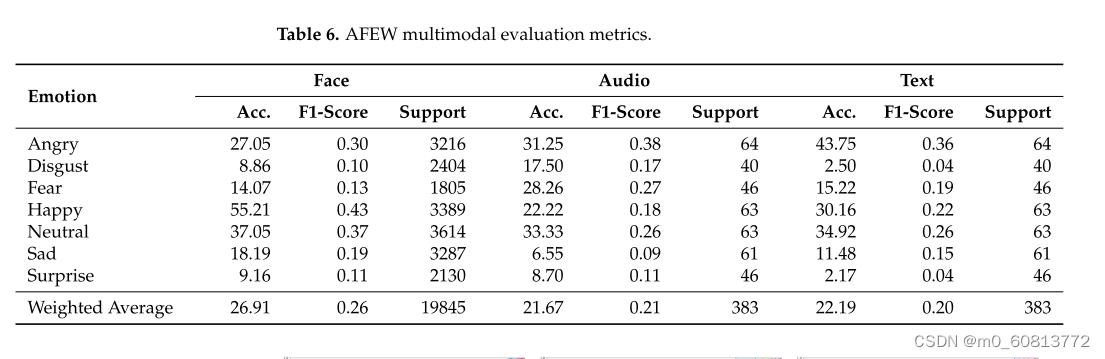
图14.AFEW数据集上每个模态的情绪ROC曲线。从左到右:面部模态:快乐显示出最高的曲线下面积(AUC),为0.76;厌恶表现最差,AUC为0.51。由于厌恶是一种更复杂的面部表情,模型很难将其与其他表情区分开来。音频模态:愤怒的AUC为0.75,而悲伤和快乐的AUC分别为0.52和0.51。文本模态:愤怒的AUC最高,为0.64。然而,大多数情绪的表现非常相似,表现最差的情绪是幸福,AUC为0.55。
表7显示了SFEW数据集的结果。我们的平均准确率为21.81%,其中快乐和愤怒被最正确地分类,准确率分别为38.889%和36.364%。类似于AFEW,它是SFEW的扩展,它在惊讶和厌恶方面表现不佳,而对恐惧没有检测。图15呈现了SFEW面部模态的ROC曲线。AUC最高的情绪是幸福,为0.72。
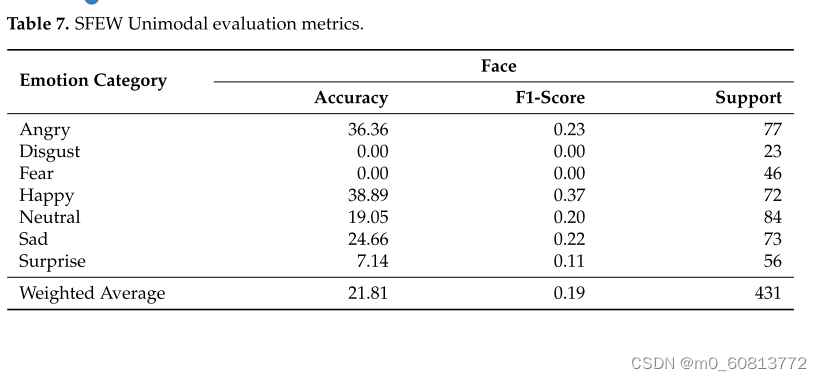
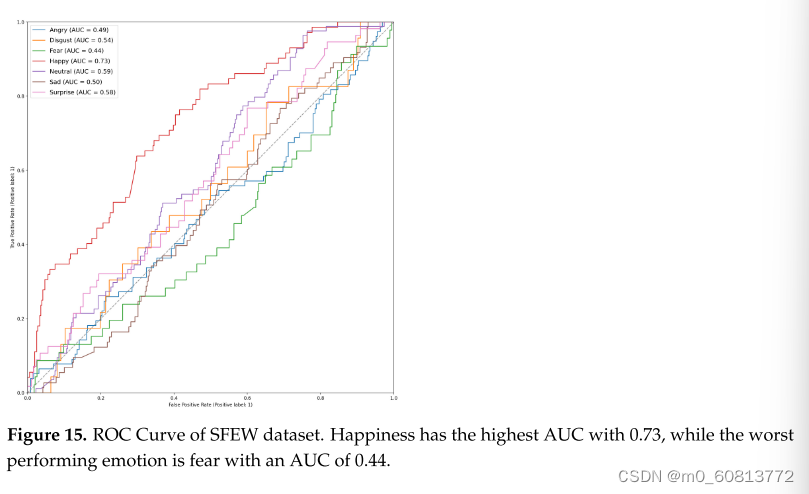
表8显示了MELD数据集的结果。面部、音频和文本的平均F1分别为15.9%、34.6%和53.7%。图16显示了这些结果的ROC曲线。表现出最佳性能的模态是文本模式,平均准确率为57.40%,这与该数据集是为会话中的情感检测而设计的事实相符。面部模态呈现最差结果。这是由于难以为图像构建新的数据集并重新标记它们。某些音频剪辑被剪切或缺少第一个音节,或者在开头或结尾可能有额外的声音。其他音频片段听起来不自然。即使文本在CSV文件中是完整的,由于这个问题,从音频文件重建它们是不可能的。
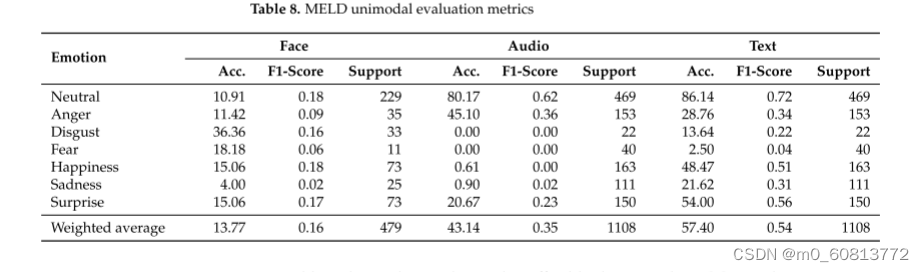
表9显示了AffWild 2数据集的结果。使用该数据集的VGG 19架构在其原始面部模态上实现了41%的加权F1分数。然而,由于数据集不是为其他形式(如音频或文本)设计的,因此这些形式的性能较低(F1-音频得分为32%,文本得分为29%)。其中一个主要原因是演讲的来源(如果产生)。数据集的很大一部分由对娱乐内容的反应视频组成。因此,情感片段中的声音可能与作为标签呈现的标记的情感不一致,因为这些情感是用面部注释的。图17显示了每种模态的每种情绪的ROC曲线。厌恶在面部和音频中都呈现出最高的曲线下面积(分别为0.94和0.69)。而在文本模态中,幸福呈现出最高的AUC,为0.57。
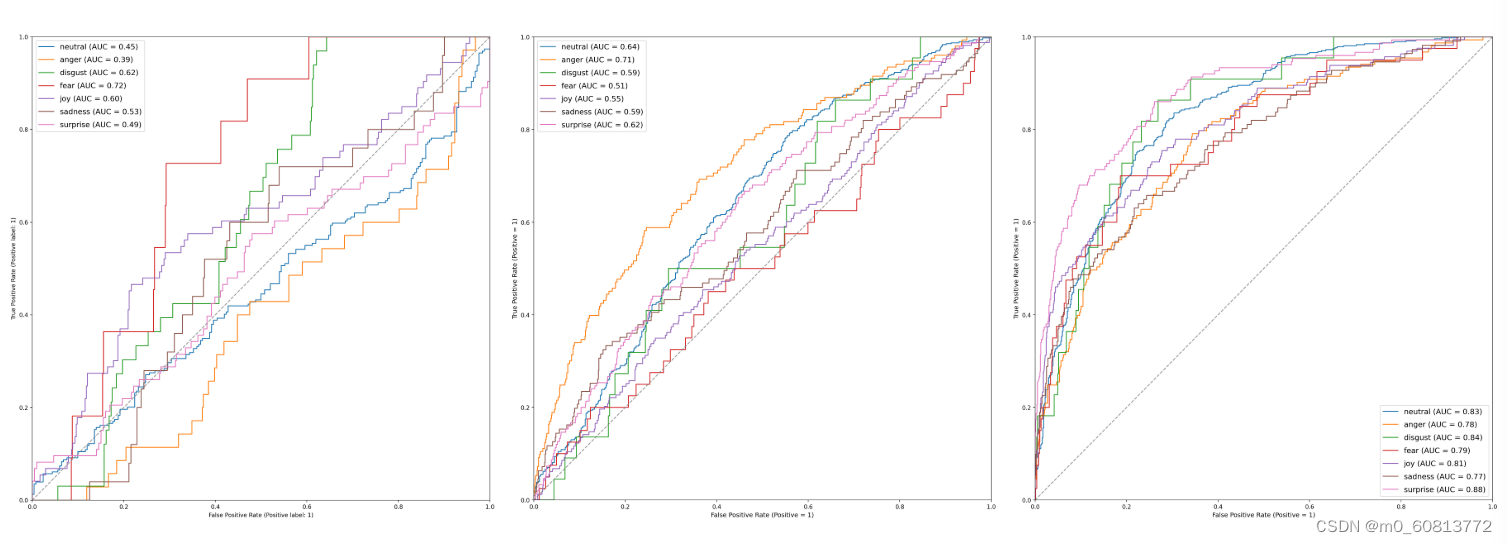
图16.MELD数据集的每个通道的ROC情绪曲线。从左到右:面孔通道:表现最高的情绪是恐惧,AUC为0.72。然而,中性和愤怒的AUC都低于0.5(分别为0.45和0.39),因此将这些例子中的大多数与其他情绪混淆了。音频通道:愤怒的AUC为0.71,中性(AUC=0.64)和惊喜(AUC=0.62)都有更好的结果。恐惧的表现最差,AUC为0.51。文本通道:表现最好的情绪是惊喜,AUC为0.88,最差的是悲伤,AUC为0.77。此高性能是预期的,因为此数据集是考虑到文本分类而设计的。
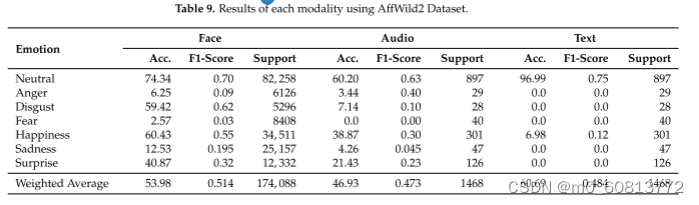
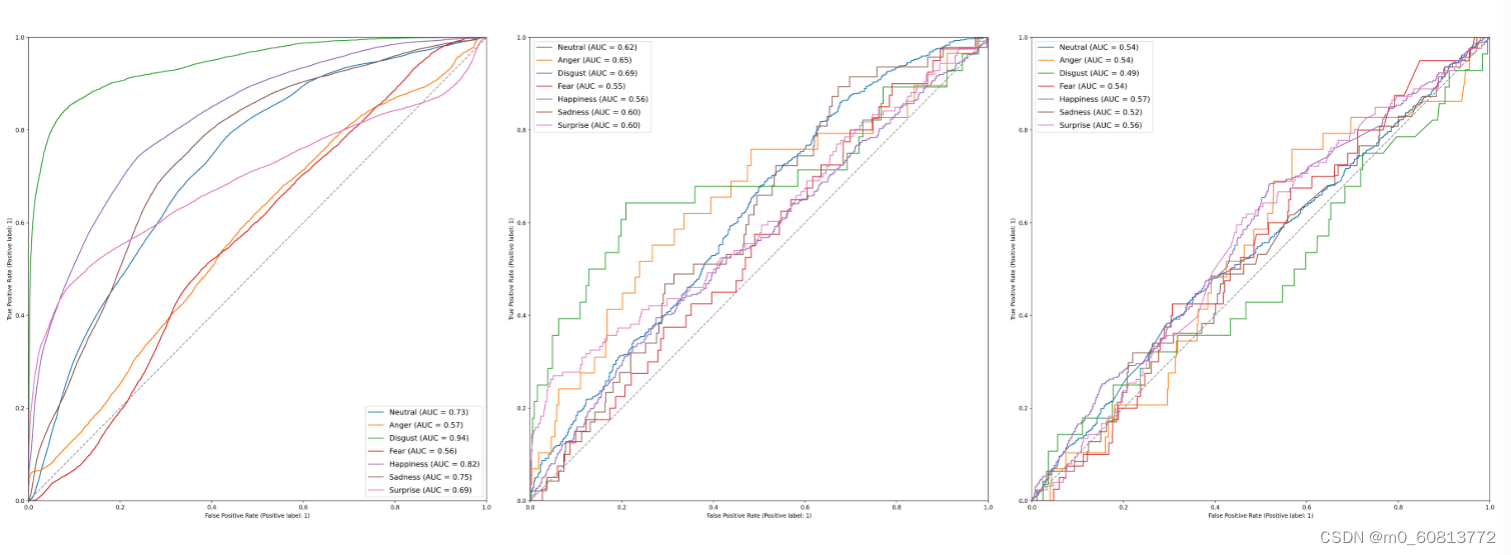
图17.AffWild 2数据集上每个模态的情绪ROC曲线。从左到右:面部模态:表现最好的情绪是厌恶,AUC为0.94,而最低的是恐惧,AUC为0.56。与其他模式相比,这种模式表现良好,因为AffWild 2是为人脸识别而设计的。音频模态:表现最好和最差的情绪分别是厌恶(AUC = 0.69)和恐惧(AUC = 0.69)。文本模态:由于AffWild 2数据集的限制,这种模式的性能很差;幸福达到了0.57的AUC,而厌恶得分最低,AUC为0.49。
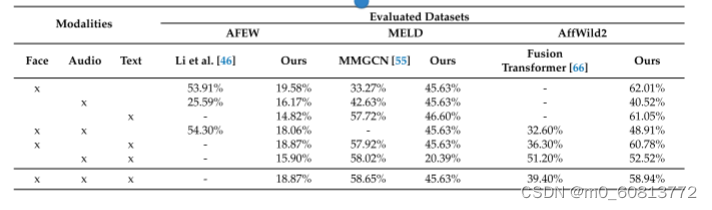
最后,我们使用Embracenet+融合方法评估了所有三种模式。表10显示了使用所有模态的准确度结果。AffWild2表现最好,加权准确率为58.64%,而AFEW的加权准确率为18.87,MELD的准确率为45.63。在AffWild2的情况下,面部和文本都显示出良好的结果,无论是单独还是融合。音频模态具有最低的性能,因为音频特征受到源数据的限制。对于AFEW数据集,面部模态本身实现了最佳性能,为19.68%。性能似乎与单峰实验的预期一致。使用MELD,只有文本模态按预期执行,因为如前所述,该数据集是为文本和音频构建的。然而,音频和文本的组合实现了20.39%的准确率。所获得的结果可能表明我们的特征存在一些问题;人脸检测器本身的性能较弱,如表8所示。与每个数据集的类似模型相比,我们的模型表现相似或更好。然而,与我们的模型相比,这些模型的评估方式存在显着差异。例如,对于AffWild2,Zhang等人。[66]报告了39.4%的多模态准确率,但他们添加了情感类别“其他”,我们没有评估,这些病例是AffWild2中高度代表性的类别。与我们相比,Li等人[46]在AFEW上的工作在音频和面部任务上表现得更好,因为他们使用了比我们用于相同任务的更复杂的架构组合。最后,在MELD数据集上,我们获得了与Hu等人类似的结果。[55]。
表10.在Embracenet+中对AFEW、MELD和AffWild2数据集的每种模态进行消融研究,考虑准确性指标。
6.讨论
文献综述和大量的论文,描述正在开发的模型显示在ER领域的兴趣和仍然存在的挑战。然而,仍然没有完全针对多模态ER设计和定向的数据集或数据库。我们可以找到专门为人脸识别而设计的数据集,但不适用于其他模式。在这种情况下,存在音频和文本不对应于面部表情的情况,从而需要重新标记这些模态的数据。在其他情况下,数据集的重点是面向对话中的文本识别,面部模态退居二线,需要额外的预处理。在原始视频数据的情况下,存在识别多个面部的组图像。这意味着需要首先执行面部识别和裁剪,并且很难将音频分配给相应的人。
大多数数据集没有良好的类平衡,因此从它们生成的模型存在重要的偏差,通过将模型过度拟合到一个类或另一个类来影响分类。因此,具有准确性的度量并不最适合指示模型的良好性能。这些模型中的许多模型都存在泛化能力受到影响的问题,因为它们在面对训练过程中没有看到的新情况时无法正确预测。虽然有多种方法来平衡类,例如,通过丢弃样本或通过生成合成样本(过采样),主要限制涉及这些情绪的记录频率。除了同一情绪中手势的差异外,某些表情根据上下文有不同的持续时间。因此需要更多的例子,以便该模型能够提高其分类能力。
AFEW和SFEW基于演员明显地用手势表达他们的情绪的图像,这可能会损害他们对现实的适应。由于其庞大的情感和多样性,与使用其他数据集训练的网络相比,AffWild 2数据集提高了所有使用它训练的网络的性能。然而,它的重点是面部,在音频和文本模式中留下不一致。事实上,因为这个数据集是用面部标记的,所以情绪反应可能会根据上下文发生的事情而有所不同。另一个问题是每个话语的平均长度,因为大多数标记的样本太短而不能表达完整的单词。这可能会造成对简短的情感表达的偏见,如尖叫或大笑。
在AffWild 2中,提供的大多数视频都是对多媒体内容或与其他人在镜头外互动的反应;标记的情感可能与音频中发生的事情不同。例如,一个孩子可能会微笑,但在背景中,母亲正在谈论她的问题。因此,从音频中提取的特定短语可能具有相反的情绪,增加模型中的混乱并降低性能。这个问题的解决方案是简单但昂贵的,需要在上下文中手动标记音频情感。
在AFEW和AffWild 2中,相同集合的音频转录丢失,限制了文本模型的性能。这是因为它依赖于自动转录系统的能力及其在野生环境中的性能。因此,文本可能与主体实际说出的内容不一致。另一方面,MELD数据集是为会话中的ER而设计的,因此面部模态需要更多的预处理。大多数视频包含多个人,因此我们可以从中提取的图像除了相应的标签外,还需要首先分离和裁剪面部。
由于低质量的源和提供的文件上的数据损坏,一些音频项目从我们的测试中被丢弃。这影响了实际可用于训练的样本数量。音频项存在的其他问题与源质量的问题有关。由于一些视频,特别是在AffWild 2中,是从互联网和社交媒体平台提取的,其中一些对应于人们对互联网内容或其他视频,电影等的反应。这些情况的另一个示例是人们在镜头外与其他人交互的视频,这增加了与这些视频相关联的情感识别的难度。
文本模态通常缺少所需的音频自动转录(MELD除外)。由于视频的数量和长度以及数据集中存在的口音范围,手动转录不具有成本效益。
我们使用Embracenet+架构的多模态策略表明,与单峰策略相比,来自不同来源的多个信息项可以用于提高情感识别。然而,有些结果与预期的结果相矛盾。例如,当使用专为音频和文本情感识别而设计的MELD数据集时,我们预期使用这些模式会有良好的性能,但加权准确率达到了20.39%。然而,音频和文本的多模态测试分别达到45.63%和46.6%,43.14%和57.4%作为一个单峰模型。
尽管如此,数据集取得的结果与其设计目标一致。在AFEW的情况下,该模型在面部模态中的表现优于AffWild 2。AffWild 2中大量的样本有利于面部模态的性能。在MELD的情况下,它优于文本中的其他数据集。
这些问题的一个可能的解决方案似乎是多个数据集的组合。这将允许在不同的背景下,无论是在行动场景和日常生活的情况下,样本的更大的多样性。关于图像以外的模态的测试数据集的改进可以提高野外情感识别任务的性能,包括正确标记不同的数据源。
拟议的方法是一个简单而不那么复杂的模型集合,因此,培训和部署所需资源较低。最初,Heredia等人的框架被设计为在人机交互环境中执行[15]。这种环境的限制恰恰有利于不太复杂和更轻的模型。然而,该框架是在实验室数据集IEMOCAP上训练的,IEMOCAP与本工作中报告的野外数据集具有非常不同的特征。尽管这个框架必须进行优化,并且必须测试新的组件,但该框架建立了一个起点,并允许我们对野外数据集所呈现的关键条件进行评估。此外,结果表明,为了获得更好的性能,必须执行额外的预处理任务。
7.结论
有各种各样的数据集,已被设计用于情绪识别。在这项工作中,我们使用先前设计的架构和四个野外数据集评估了ER性能:AFEW,SFEW,MELD和AffWild 2。在文献中,基于深度学习的情感识别架构很常见。我们使用预先训练的网络和一些性能指标,如准确性和F1分数。结果表明,我们的模型可以有效地识别情绪,使用裁剪的图像,音频和正在说什么的transparency。然而,现有的数据集没有被设计用于多模态ER任务。将所获得的结果与所研究的数据集进行比较,
对于面部模态,我们表现最好的数据集是AffWild 2,平均准确率为53.98%,平均F1分数为0.514。这主要是因为数据集中提供了大量可用的图像样本,从而可以更好地泛化。对于音频模态,我们的模型在AffWild 2数据集上表现最好,平均准确率为46.93%,F1得分为0.473,略好于MELD,其次是平均准确率为43.14%,平均F1为0.356。虽然MELD是为音频和文本模态设计的数据集,但每个类的可用示例数量有些不平衡,特别是在厌恶或恐惧等不太可用的类中,这是可以理解的,因为原始来源是喜剧节目。在文本模态中,AffWild 2的平均性能最好,准确率为60.69%,但这个结果是倾斜的,因为对于这个数据集,我们的模型由于大量的中性和幸福类样本而过度拟合。这项任务的最佳数据集是MELD,平均准确率为57.40%,F1分数为0.537。由于该数据集是为该特定任务设计的,并且包括采样对话的转录文本,因此与AffWild 2和AFEW相比,我们的模型能够以更高的确定性进行分类。这两个数据集的传输依赖于存储的声音质量和使用的语音识别模型。
当比较所有三个数据集的多模态融合时,AffWild 2的整体性能最好,尽管有更多的数据可用性偏差。这可以通过更多的标记数据来进一步改进,特别是来自不同来源和环境的数据,以及对最少表示的示例的数据增强。
本研究的下一步包括从现有的野外数据集配置一个新的数据集,改进每个数据源的预处理及其多模态任务的标记,并在结合一些优化技术以实现单峰和多模态性能的目标后,对我们的网络集进行再训练。















 2748
2748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









