







目录
简介
深度学习在目标检测领域的目标是通过训练模型来识别图像或视频中的特定目标,例如人脸、汽车、动物等。目标检测的任务通常包括定位目标的位置和确定其类别。深度学习模型通过学习大量标注数据来提高目标检测的准确性和鲁棒性,可以应用于许多领域,如智能监控、自动驾驶、医学影像识别等。随着深度学习技术的不断发展,目标检测的性能和效率也在不断提升。
数据集
VOC数据集
VOC数据集是一种常用的用于目标检测和图像分割任务的数据集。该数据集包含了20个类别的图像,包括人、动物、车辆等常见的物体。VOC数据集由伦敦帝国学院计算机视觉实验室创建,每年发布一次,用于评估计算机视觉算法的性能。该数据集被广泛应用于目标检测、图像分割和图像分类等任务的研究和开发中。
COCO数据集
COCO(Common Objects in Context)数据集是一个广泛使用的计算机视觉数据集,用于目标检测、图像分割和其他相关任务的训练和评估。该数据集包含超过330,000张图像,其中包括超过200,000张标注了80个不同类别的对象的图像。这些对象包括人、动物、交通工具、家具等。COCO数据集还包括了每个图像的详细标注,包括对象的边界框和像素级的分割。
COCO数据集的广泛使用使得它成为了计算机视觉领域中的重要基准数据集之一,许多研究和算法的性能都是在COCO数据集上进行评估和比较的。这个数据集的丰富性和多样性使得它适用于各种不同的视觉任务和算法的评估。
目标检测的Ground Truth
Ground Truth(GT)是计算机视觉和机器学习中的术语,用于指代用于训练和评估机器学习模型的实际真实数据或观察结果。训练过程的目标是学习输入数据(图像)与相应的Ground Truth数据(实际图像)之间的关系。这有助于模型根据从Ground Truth数据中学到的模式和特征准确预测输出或对输入数据进行分类。

- YOLO(TXT)格式:
(x,y,w,h)
分别代表中心点坐标和宽、高
x,y,w,h均为归一化结果
- VOC(XML)格式:
(Xmin,Ymin,Xmax,Ymax)
分别代表左上角和右下角的两个坐标。
- COCO(JSON)格式:
(Xmin, Ymin, W, H),
其中x,y,w,h均不是归一化后的数值,
分别代表左上角坐标和宽、高
目标检测的评估指标
IoU:Intersection over Union
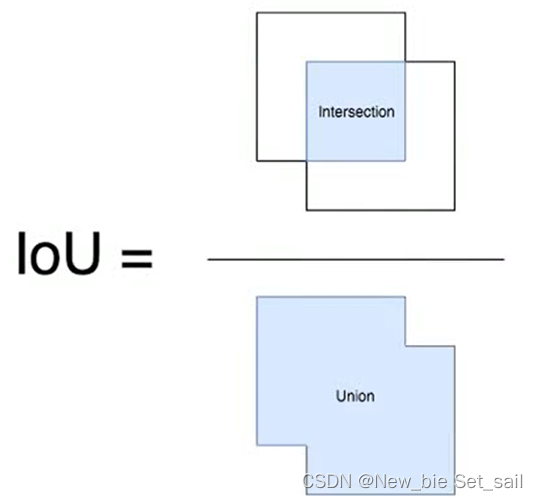
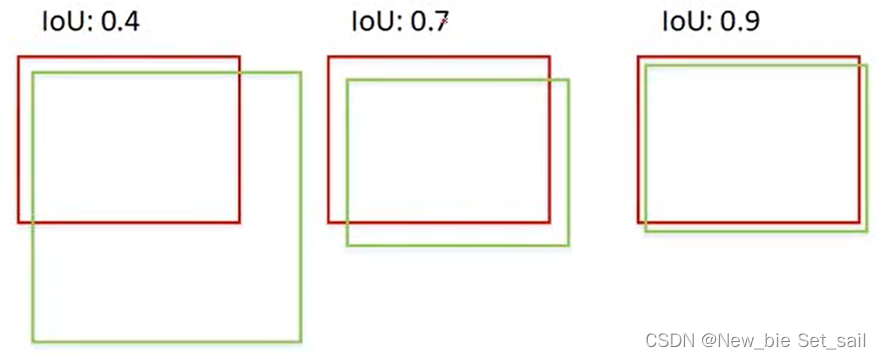
- 生成的预测结果会非常多
- 首先过滤掉低类别置信度的检测结果
- 使用IoU作为边界框正确性的度量指标
检测结果的类别
| 评价指标 | 解释 | Ground Truth | 预测结果 | 目标检测中的解释 |
| TP | 真的正样本 | 正样本 | 正样本 | IoU>阈值 |
| FP | 假的正样本 | 负样本 | 正样本 | IoU<阈值 |
| TN | 真的负样本 | 负样本 | 负样本 | |
| FN | 假的负样本 | 正样本 | 负样本 | 漏检目标 |


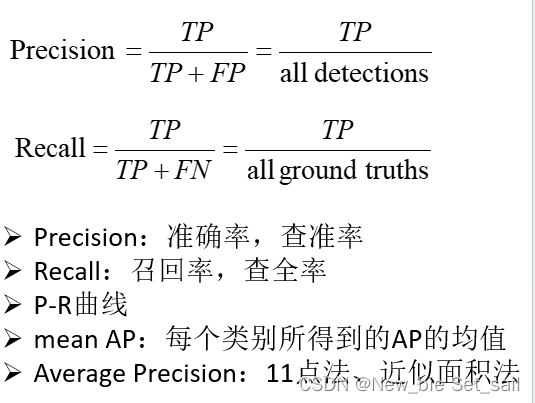
· mean与average

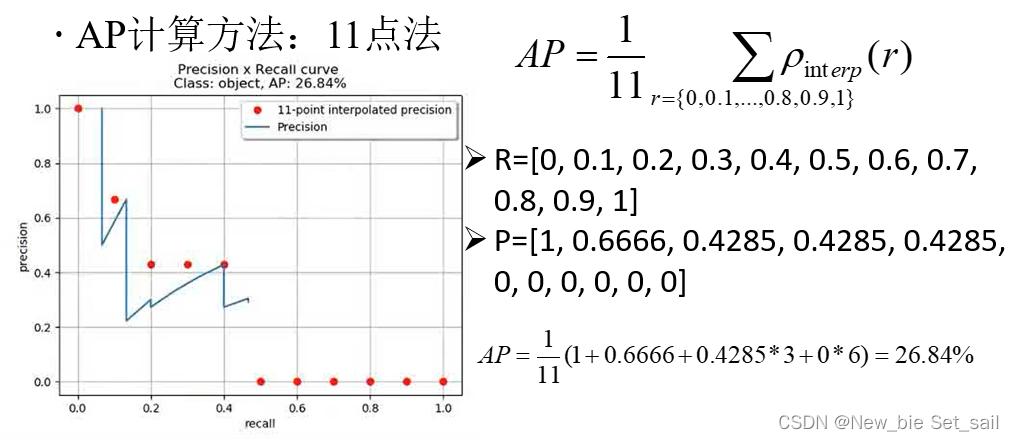
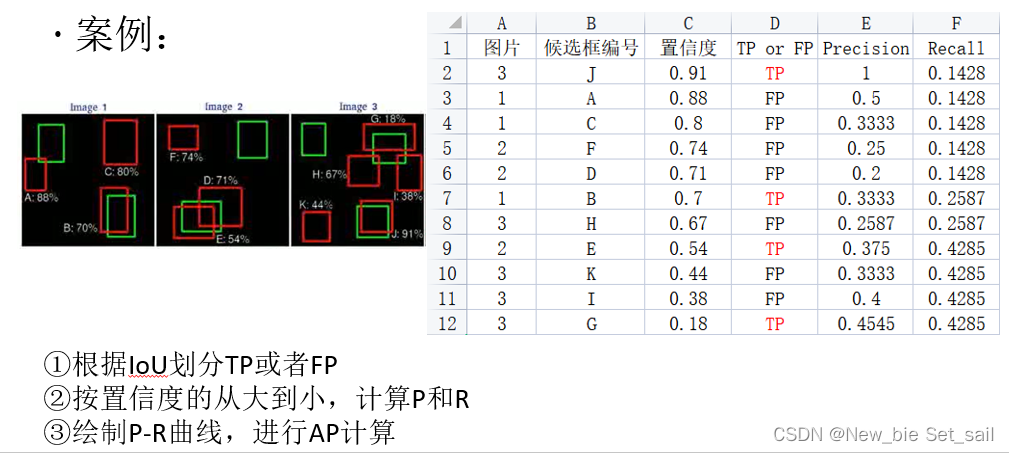
案例
YOLO系列
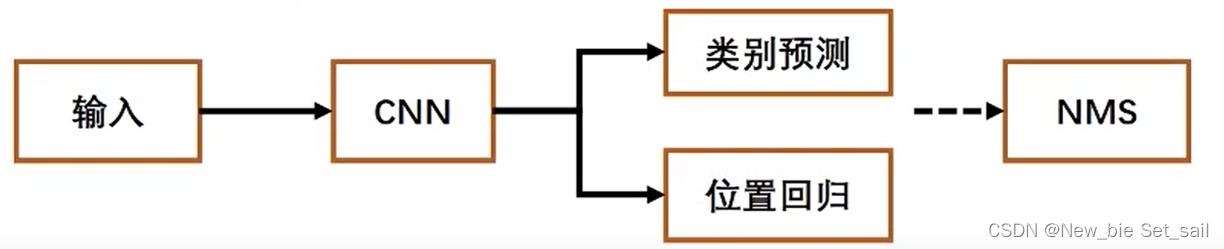
one stage算法流程
· 常见one stage算法
- YOLO系列:YOLO v1-v5
- SSD系列:SSD、DSSD、FSSD
- 其他经典:RefineDet
two stage算法流程

· 常见two stage算法
- 经典发展线:R-CNN、SPP-Net、Fast R-CNN、 Faster R-CNN
- 其他:Cascade R-CNN、Guided Anchoring
















 2704
2704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











