







目录
一、概念
随机森林是一种集成学习(ensemble learning)方法,用于解决分类和回归问题。它结合了多个决策树模型,通过投票或平均的方式来进行预测。
随机森林的主要思想是通过构建多个决策树,每个决策树都是基于不同的随机样本和随机特征集来训练的。这种随机性的引入有助于减少过拟合的风险,并提高模型的泛化能力。
具体来说,随机森林的训练过程如下:
- 从原始训练数据集中有放回地抽取随机样本,形成一个新的训练数据集(bootstrap样本)。
- 针对每个bootstrap样本,随机选择一部分特征作为决策树的输入特征。
- 构建决策树模型,根据选定的特征和样本进行划分,直到达到预定的停止条件(如树的深度)。
- 重复步骤1-3,构建多个决策树模型。
- 对于分类问题,通过投票的方式,选择多数决策树的预测结果作为最终的预测结果。对于回归问题,通过平均多个决策树的预测结果来得到最终的预测值。
随机森林具有很多优点,包括:
- 能够处理高维数据和大规模数据集。
- 对于离群值和噪声具有较好的鲁棒性。
- 可以估计特征的重要性,用于特征选择。
- 不需要对数据进行归一化或标准化。
二、随机森林所解决的问题
分类问题:随机森林可以用于解决二分类问题或多分类问题。它可以根据输入特征对数据进行分类,并输出相应的类别。
回归问题:随机森林可以用于解决回归问题。它可以根据输入特征预测输出的连续数值。
特征选择:随机森林可以用于选择最重要的特征。通过计算特征在随机森林中的重要性,可以确定哪些特征对于解决问题最为关键。
异常检测:随机森林可以用于检测异常数据点。通过比较数据点与随机森林的预测结果,可以判断数据点是否异常。
缺失值填充:随机森林可以用于填充缺失值。通过使用其他特征的值预测缺失值,可以将缺失值进行估计。
三、随机森林常用库
scikit-learn:scikit-learn是Python中最流行的机器学习库之一,提供了丰富的机器学习算法实现,包括随机森林。它提供了RandomForestClassifier和RandomForestRegressor类,可以用于分类和回归问题。
XGBoost:XGBoost是一个优秀的梯度提升框架,也支持随机森林。它提供了XGBClassifier和XGBRegressor类,可以用于分类和回归问题,并且具有较高的性能和可扩展性。
LightGBM:LightGBM是另一个高效的梯度提升框架,也支持随机森林。它提供了LGBMClassifier和LGBMRegressor类,可以用于分类和回归问题,并且具有较快的训练速度和较低的内存消耗。
RandomForest4Life:RandomForest4Life是R语言中一个常用的随机森林库,提供了RandomForest和randomForestSRC等函数,可以用于分类和回归问题。
H2O:H2O是一个分布式机器学习平台,支持多种机器学习算法,包括随机森林。它提供了H2ORandomForestEstimator类,可以用于分类和回归问题,并且具有分布式计算的能力。
四、 代码实现
1、随机森林分类
#生成分类示例数据
from sklearn.datasets import make_classification
X, y = make_classification(n_features = 2, n_informative = 2, n_redundant = 0, n_samples = 100, n_classes = 2, random_state = 0)
y[y == 0] = -1
'''二分类的数据集,n_features表示生成数据集的特征数量,n_informative表示有用特征的数量,n_redundant表示冗余特征的数量,n_samples表示生成的样本数量,n_classes表示类别的数量,random_state表示随机种子,用于保证每次生成的数据集相同。
在生成的数据集中,标签y中的0被替换为-1,这是为了方便后续使用某些分类算法。在二分类问题中,通常使用-1和1来表示两个类别。'''
#随机森林分类实现
import numpy as np
from sklearn.tree import DecisionTreeClassifier
class rfc:
"""
随机森林分类器
"""
#初始化方法,设置随机森林的大小和随机种子
def __init__(self, n_estimators = 100, random_state = 0):
# 随机森林的大小
self.n_estimators = n_estimators
# 随机森林的随机种子
self.random_state = random_state
#拟合方法,用于训练随机森林分类器。根据输入的特征矩阵X和标签y,生成决策树数组,并使用随机生成的权重拟合数据集。
def fit(self, X, y):
"""
随机森林分类器拟合
"""
self.y_classes = np.unique(y)
# 决策树数组
dts = []
n = X.shape[0]
rs = np.random.RandomState(self.random_state)
for i in range(self.n_estimators):
# 创建决策树分类器
dt = DecisionTreeClassifier(random_state=rs.randint(np.iinfo(np.int32).max), max_features = "auto")
# 根据随机生成的权重,拟合数据集
dt.fit(X, y, sample_weight=np.bincount(rs.randint(0, n, n), minlength = n))
dts.append(dt)
self.trees = dts
#predict(self, X): 预测方法,用于对新的样本进行分类预测。遍历决策树数组,依次预测每个决策树的结果可能性,并取平均值作为最终预测结果。
def predict(self, X):
"""
随机森林分类器预测
"""
# 预测结果数组
probas = np.zeros((X.shape[0], len(self.y_classes)))
for i in range(self.n_estimators):
# 决策树分类器
dt = self.trees[i]
# 依次预测结果可能性
probas += dt.predict_proba(X)
# 预测结果可能性取平均
probas /= self.n_estimators
# 返回预测结果
return self.y_classes.take(np.argmax(probas, axis = 1), axis = 0)
#随机森林分类拟合
# 随机森林分类器
rf = rfc()
# 拟合数据集
rf.fit(X, y)
#随机森林分类可视化
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
%matplotlib notebook
plt.rcParams['font.sans-serif'] = ['simhei'] # 选择一个本地的支持中文的字体
fig, ax = plt.subplots()
ax.set_facecolor('#f8f9fa')
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, .05), np.arange(y_min, y_max, .05))
Z = rf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
clist=['#ffadad', '#8ecae6']
newcmp = LinearSegmentedColormap.from_list('point_color', clist)
plt.pcolormesh(xx, yy, Z, cmap = newcmp)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
x1 = X[y==-1][:, 0]
y1 = X[y==-1][:, 1]
x2 = X[y==1][:, 0]
y2 = X[y==1][:, 1]
p1 = plt.scatter(x1, y1, c='#e63946', marker='o', s=20)
p2 = plt.scatter(x2, y2, c='#457b9d', marker='x', s=20)
ax.set_title('随机森林分类', color='#264653')
ax.set_xlabel('X1', color='#264653')
ax.set_ylabel('X2', color='#264653')
ax.tick_params(labelcolor='#264653')
plt.legend([p1, p2], ["-1", "1"], loc="upper left")
plt.show() 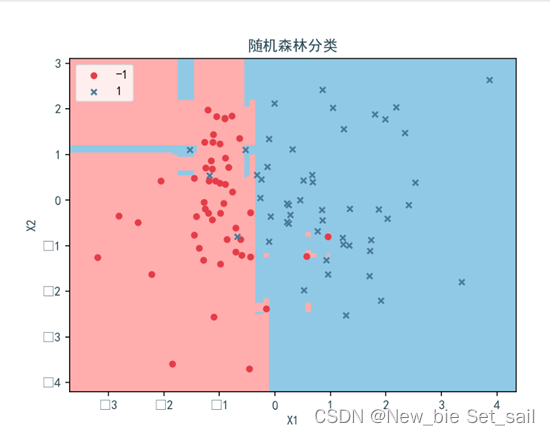
2、随机森林回归
#生成回归示例数据集
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 1, n_targets = 1, n_samples = 100, noise=5, random_state = 0)
#随机森林回归
import numpy as np
from sklearn.tree import DecisionTreeRegressor
class rfr:
"""
随机森林回归器
"""
def __init__(self, n_estimators = 100, random_state = 0):
# 随机森林的大小
self.n_estimators = n_estimators
# 随机森林的随机种子
self.random_state = random_state
def fit(self, X, y):
"""
随机森林回归器拟合
"""
# 决策树数组
dts = []
n = X.shape[0]
rs = np.random.RandomState(self.random_state)
for i in range(self.n_estimators):
# 创建决策树回归器
dt = DecisionTreeRegressor(random_state=rs.randint(np.iinfo(np.int32).max), max_features = "auto")
# 根据随机生成的权重,拟合数据集
dt.fit(X, y, sample_weight=np.bincount(rs.randint(0, n, n), minlength = n))
dts.append(dt)
self.trees = dts
def predict(self, X):
"""
随机森林回归器预测
"""
# 预测结果
ys = np.zeros(X.shape[0])
for i in range(self.n_estimators):
# 决策树回归器
dt = self.trees[i]
# 依次预测结果
ys += dt.predict(X)
# 预测结果取平均
ys /= self.n_estimators
return ys#随机森林回归拟合
# 随机森林回归器
rf = rfr()
# 拟合数据集
rf.fit(X, y)
#随机森林回归可视化
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
%matplotlib notebook
plt.rcParams['font.sans-serif'] = ['simhei'] # 选择一个电脑支持的中文的字体
fig, ax = plt.subplots()
ax.set_facecolor('#f8f9fa')
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
xx = np.arange(x_min, x_max, .05)
yy = rf.predict(np.c_[xx.ravel()])
plt.scatter(X, y, c='#e63946', marker='o', s=20)
plt.plot(xx, yy)
ax.set_title('随机森林回归', color='#264653')
ax.set_xlabel('X', color='#264653')
ax.set_ylabel('Y', color='#264653')
ax.tick_params(labelcolor='#264653')
plt.show()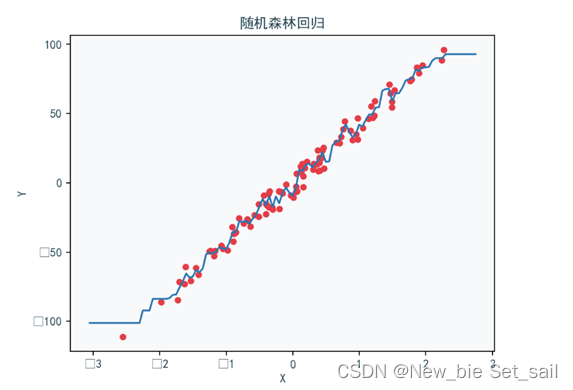
3、代码可能出现的问题
(1)汉化乱码
①如果出现可视化结果中的汉化问题,请修改途中标注红色部分,引号中表示.ttf字体文件名

②首先,从网上下载simhei.ttf文件
③将它放在C盘目录下的电脑字体文件夹中(C:\Windows\fonts)
(2)没有或正确安装代码所需要的库
①请从Anaconda文件夹中的Anaconda Prompt(anaconda3)命令符中输入
#先输入这个
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
#再输入这个
conda config --set show_channel_urls yes
#之后输入你想要安装的库的名称
conda install 库名

















 3038
3038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











