







numpy和pandas相关内容
输入如下代码:
import numpy as np
a = np.arange(12)
print(a)
print(type(a))
print(a.shape)
a.shape = (3, 4)
print(a)
print(a.strides)
print(a[1])
运行结果:
[ 0 1 2 3 4 5 6 7 8 9 10 11]
<class ‘numpy.ndarray’>
(12,)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
(16, 4)
[4 5 6 7]
最后两行可以看到,因为数据是int型,一个数据存储占了4字节,因此a.strides返回(16,4),a[1]指的是a进行shape后的第1行。
将代码的第3行换成a = np.arange(12, dtype=np.int64),则一个数据占8个字节。还可以换成float等格式。
输入如下代码:
import numpy as np
import pandas as pd
a = np.arange(1, 21)
print(a)
b = a.reshape((4, 5))
print(b)
c = b[[1, 3], [0, 1]]
print(c)
c = pd.DataFrame(b)
结果如下:
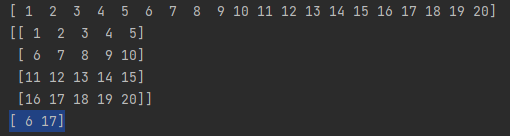
注意第8行,c = b[[1, 3], [0, 1]]输出的是b[1,0]和b[3,1]
在刚才的代码后面添加:
import pandas as pd
c = pd.DataFrame(b, columns=list('春夏秋冬年'), index=np.arange(2021,2017,-1))
print(c)
c.to_excel('result.xlsx')
c.to_csv('result.csv', encoding='ansi')
c.to_json('result.json')
可以将nparray转换为DataFrame的格式,可以添加行、列名称,并存储成不同的形式。
在这个例子中,可以看到,在json格式下,'春夏秋冬年’是字典的key,而下面的数据是每个key对应的value。

输入如下代码:
import numpy as np
import pandas as pd
col_names = '性别', '年龄', '姓名'
sex = list('男男女男女男男女男')
age = 11, 22, 33, 44, 55, 66, 77, 88, 99
name = list('并存储成不同的形式')
d = {col_names[0]: sex, col_names[1]: age, col_names[2]: name}
print(d)
t = pd.DataFrame(d)
print(t)
t['身高'] = 1
print(t)
t['身高1'] = 2*np.arange(9)
print(t)
我们可以看到,在t中可以根据字典的方法添加新的列,在代码t['身高'] = 1中,只添加了一个值,则身高t这一列所有值都为1;而在t['身高1'] = 2*np.arange(9)中,添加了9个值;如果添加的值于行数不相等,则系统报错。
数据集分析
下面我们对网络上的真实数据进行分析。我们在uci数据集官网上找到鸢尾花数据集,下载里面的iris.data和iris.names,放到python我们的项目目录下。
输入如下代码:
import numpy as np
import pandas as pd
data = pd.read_csv('iris.data', header=None)
print(data)
可以在csv文件里看到数据内容,该数据集共150行,每行1个样本。每个样本有5个字段,分别是:
- 花萼长度(单位cm)
- 花萼宽度(单位:cm)
- 花瓣长度(单位:cm)
- 花瓣宽度(单位:cm)
- 类别(共3类)(Iris setosa 山鸢尾、Iris versicolor 杂色鸢尾、Iris Virginica 维吉尼亚鸢尾)
注意上述代码第4行data = pd.read_csv('iris.data', header=None),后面需要添加header=None,因为这个数据是没有数据头的,如果不添加的话,python会把第一行数据认为是数据头。
使用describe对数据进行分析:
import pandas as pd
col_names = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度', 'Type']
data = pd.read_csv('iris.data', header=None, names=col_names)
print(data)
desc = data.describe()
print(desc)
得到结果,其中重点看一下平均值(mean)、中位数(50%)以及标准差(std),根据这三个值可以看出数据是否合理:
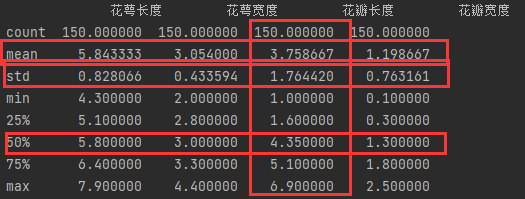
其中,我们需要判断是否所有数据(最大值和最小值)都在均值±3倍标准差这个范围内,如果在的话,就说明这组数据相对比较合理。在上述数据中,我们可以看到花瓣长度(第3列)和花瓣宽度(第4列)数据不太合理,因此我们对花瓣宽度的数据进行分析。
在刚才的代码基础上添加以下代码:
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['simHei']
mpl.rcParams['axes.unicode_minus'] = False
t = data['花瓣宽度']
plt.hist(t, bins=10, edgecolor='k')
plt.xlabel('花瓣宽度')
plt.ylabel('样本个数')
plt.title('鸢尾花数据集花瓣长度直方图')
plt.show()
运行可以看到,这个数据的确是有问题的,偏小的花瓣宽度很多:

我们姑且认为,这些比较小的花瓣宽度,是因为花还未长大,并且它们最终都会长大到花瓣宽度的中位数大小,因此添加以下代码,将数据中前25%的数据全部变为1.3:
a = np.percentile(t, 25)
sel = t < a
print(sel)
result = pd.value_counts(sel)
print(result)
print(t[sel])
t[sel] = 1.3
得到数据:

这个赋值方式比较简单粗暴,同样也可以用高斯分布的方式给小花瓣宽度赋值,运用代码:
t[sel] = 0.763161*np.random.randn(np.sum(sel))+1.3
这句代码的意思是生成一组标准差为0.763161,中位数为1.3的高斯分布随机数,运行得到结果:

这里python报了一个warning:
A value is trying to be set on a copy of a slice from a DataFrame
原因是我们在修改t[sel]的值的时候,python不知道我们是改的data中拷贝出来的t的值还是想改变原始数据值,这里把t[sel]改成data.loc[sel, '花瓣宽度']就不会报warning了,不过原始的data数据也会被改变。
事实上,观察原始数据我们会发现,所有的小花瓣长度和宽度,都集中在第一种花中,因为原始数据事实上是合理的。所以说我们在进行数据分析的时候,使用合适的方法也十分重要,否则有可能将正确的数据分析错误。
仍然基于鸢尾花数据进行分析,输入以下代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
col_names = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度', 'Type']
data = pd.read_csv('iris.data', header=None, names=col_names)
d = data['花萼长度']
data['花萼长度_cut'] = pd.cut(data['花萼长度'], bins=10, labels=np.arange(10))
print(data)
result_L = pd.value_counts(data['花萼长度_cut'])
print(result_L)
result_L.sort_index(inplace=True, ascending=True)
print(result_L)
可以看到,我们新建了一列,对花萼的长度做了一个分割,分成了10份(第9行),然后对这10份中的内容进行了统计(第11行)并排序(第13行)。
在后面添加以下代码将数据可视化:
plt.bar(result_L.index, result_L.values, width=0.6)
plt.show()
同理,我们可以添加代码将花萼宽度、花瓣长度也都添加到我们的图形上,同时将花萼宽度、花瓣长度的bar添加到花萼长度上面,代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['simHei']
mpl.rcParams['axes.unicode_minus'] = False
col_names = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度', 'Type']
data = pd.read_csv('iris.data', header=None, names=col_names)
data['花萼长度_cut'] = pd.cut(data['花萼长度'], bins=10, labels=np.arange(10))
data['花萼宽度_cut'] = pd.cut(data['花萼宽度'], bins=10, labels=np.arange(10))
data['花瓣长度_cut'] = pd.cut(data['花瓣长度'], bins=10, labels=np.arange(10))
result_L = pd.value_counts(data['花萼长度_cut'])
result_W = pd.value_counts(data['花萼宽度_cut'])
result_L2 = pd.value_counts(data['花瓣长度_cut'])
result_L.sort_index(inplace=True, ascending=True)
result_W.sort_index(inplace=True, ascending=True)
result_L2.sort_index(inplace=True, ascending=True)
plt.bar(result_L.index, result_L.values, width=0.6)
plt.bar(result_W.index, result_W.values, bottom=result_L.values, width=0.6, label='花萼宽度')
plt.bar(result_L2.index, result_L2.values, bottom=result_L+result_W.values, width=0.6, label='花瓣长度')
plt.legend(loc='best')
plt.show()
bar的参数分别为:x坐标、高度、宽度、y坐标(bottom)
注意第26行,bottom=result_L+result_W.values,bottom需要是下面讲个数据相加。
运行结果:

同样,我们也可以让柱状图并列摆放:
width = 0.2
plt.bar(np.array(result_L.index), result_L.values, width=width)
plt.bar(np.array(result_W.index)+width, result_W.values, width=width, label='花萼宽度')
plt.bar(np.array(result_L2.index)+2*width, result_L2.values, width=width, label='花瓣长度')
这里要注意np.array(result_W.index)+width,添加了np.array是因为result_W.index不是int型,不能和width直接相加。
运行结果:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









