






【项目简介】
PyTorch是利用深度学习进行数据科学研究的重要工具,在灵活性、可读性和性能上都具备相当的优势,近年来已成为学术界实现深度学习算法最常用的框架。考虑到PyTorch的学习兼具理论储备和动手训练,两手都要抓两手都要硬的特点,我们开发了 《深入浅出PyTorch》课程,期望以组队学习的形式,帮助大家从入门到熟练掌握PyTorch工具,进而实现自己的深度学习算法。学习的先修要求是,会使用Python编程,了解包括神经网络在内的机器学习算法,勤于动手实践。
我们的愿景是:通过组队学习,大家能够掌握由浅入深地PyTorch的基本知识和内容,经过自己的动手实践加深操作的熟练度。同时通过项目实战,充分锻炼编程能力,掌握PyTorch进行深度学习的基本流程,提升解决实际问题的能力。
【教程地址】
在线教程链接:https://datawhalechina.github.io/thorough-pytorch/
Github在线教程:https://github.com/datawhalechina/thorough-pytorch
Gitee在线教程:https://gitee.com/datawhalechina/thorough-pytorch
b站视频:https://www.bilibili.com/video/BV1L44y1472Z
目录
序
之前学过一遍课程,没有安装好jupyter notebook和pytorch实操,这次重点实践练习,
Task01课程笔记链接如下: http://t.csdn.cn/uEw0c
从上次出bug的检验是否安装完成开始
进入所在的虚拟环境,紧接着输入python,在输入下面的代码。
import torch
torch.cuda.is_available()>>>False
这条命令意思是检验是否可以调用cuda,如果我们安装的是CPU版本的话会返回False,能够调用GPU的会返回True。一般这个命令不报错的话就证明安装成功。

检验成功
PyTorch基础知识复习
Pytorch简介
- pytorch是由Facebook开发
- 利用深度学习进行科学研究的重要工具
- 学术界最常用的深度学习框架
- 简洁、高效、扩展性好
张量 - 现代机器学习的基础(类似多维数组)
它的核心是一个数据容器,多数情况下,它包含数字,有时候它也包含字符串,但这种情况比较少。因此可以把它想象成一个数字的水桶。
这里有一些存储在各种类型张量的公用数据集类型:
-
3维 = 时间序列
-
4维 = 图像
-
5维 = 视频
创建张量
几种常见的创建tensor的方法 | |
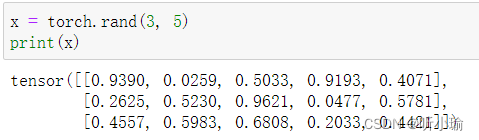
| 随机初始化矩阵 通过 torch.randn_like可转换为随机矩阵 | import torch x = torch.rand(4, 3) print(x)
|
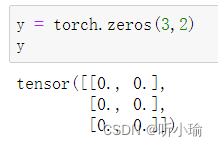
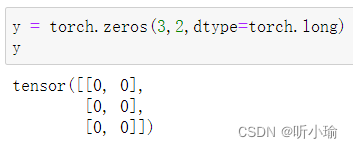
| 全0矩阵的构建 通过 |
|
| 全1矩阵的构建 | 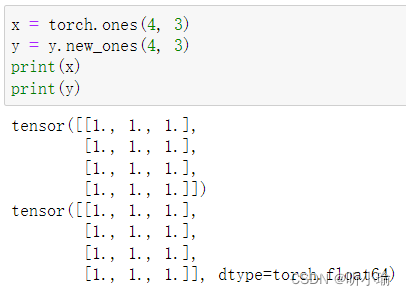 |
| 通过 | 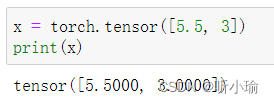  |
| 基于已经存在的 tensor,创建一个 tensor : | 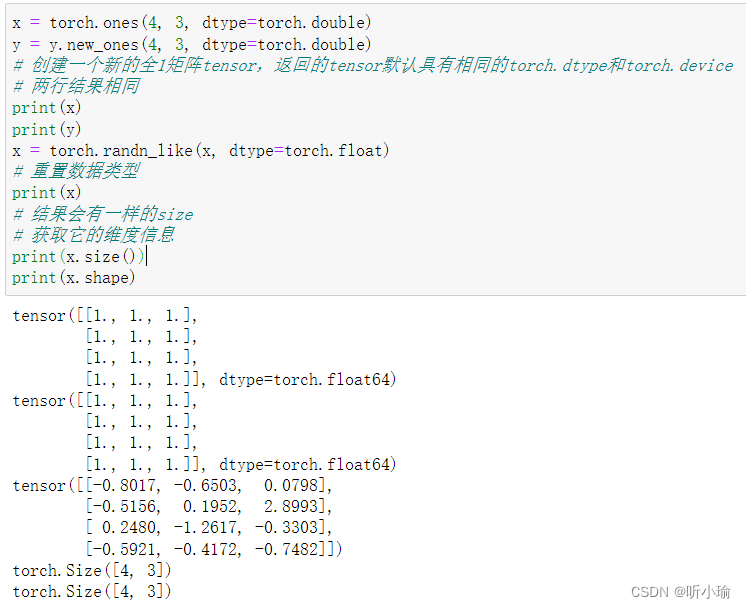 |
常见的构造Tensor的方法:
| 函数 | 功能 |
|---|---|
| Tensor(sizes) | 基础构造函数 |
| tensor(data) | 类似于np.array |
| ones(sizes) | 全1 |
| zeros(sizes) | 全0 |
| eye(sizes) | 对角为1,其余为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀分成step份 |
| rand/randn(sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| randperm(m) | 随机排列 |
张量的操作
| 加法操作 |  |
| 索引操作:(类似于numpy) 需要注意的是:索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用copy()等方法 |
|
| 维度变换 张量的维度变换常见的方法有 注: torch.view()会改变原始张量,但是很多情况下,我们希望原始张量和变换后的张量互相不影响。为为了使创建的张量和原始张量不共享内存,我们需要使用第二种方法 | 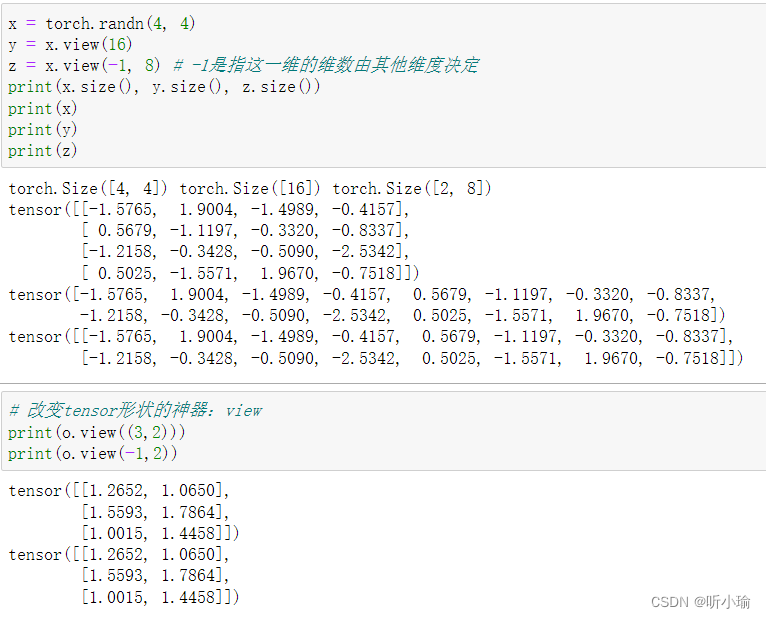 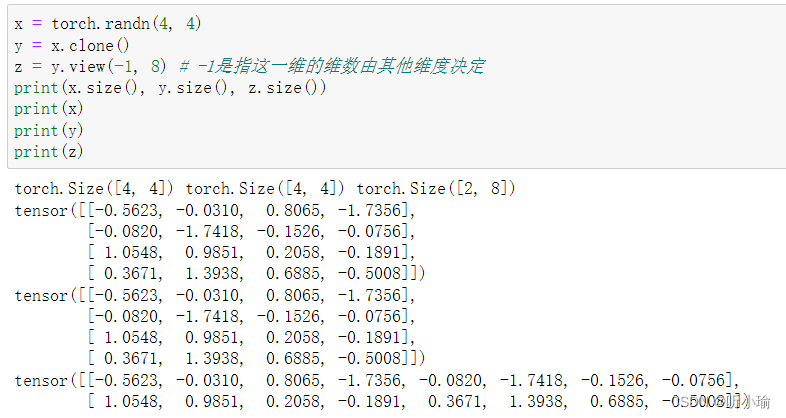 |



PyTorch中的 Tensor 支持超过一百种操作,包括转置、索引、切片、数学运算、线性代数、随机数等等,具体使用方法可参考官方文档。
广播机制 (理解为复制机制)
当对两个形状不同的 Tensor 按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算。

【拓展】
arange函数
arange()函数有四个个参数,分别是start(开始值)、stop(终值)、step(步长)和dtype(数组类型)。
| (1) start:开始值 | (2) stop:终值 | (3) step:步长 参数类型:可选 | (4) dtype:数组类型 参数类型:可选 |
自动求导
PyTorch 中,所有神经网络的核心是 autograd 包。autograd包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义 ( define-by-run )的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的。
并行计算
在利用PyTorch做深度学习的过程中,可能会遇到数据量较大无法在单块GPU上完成,或者需要提升计算速度的场景,这时就需要用到并行计算。
这两部分内容还需要多多研究下,上次做过笔记就不赘述了。
课程笔记链接: http://t.csdn.cn/uEw0c















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









