









1.什么是DCU?
DCU(Deep Computing Unit 深度计算器)是 海光(HYGON)推出的一款专门用于 AI 人工智能和深度学习的加速卡。DCU也可以应用于密集型数值计算。
2.DCU的架构
DCU通过PCI-E总线与CPU处理器相连,它是CPU主机系统的一个硬件扩展,其存在的目的是为了对程序某些模块或者函数进行加速。一个主机系统在PCI-E总线上可以插入多张DCU与CPU进行互连,这使得一台主机的算力具有可扩展性,合理的利用多DCU程序可以获得更好的加速效果。
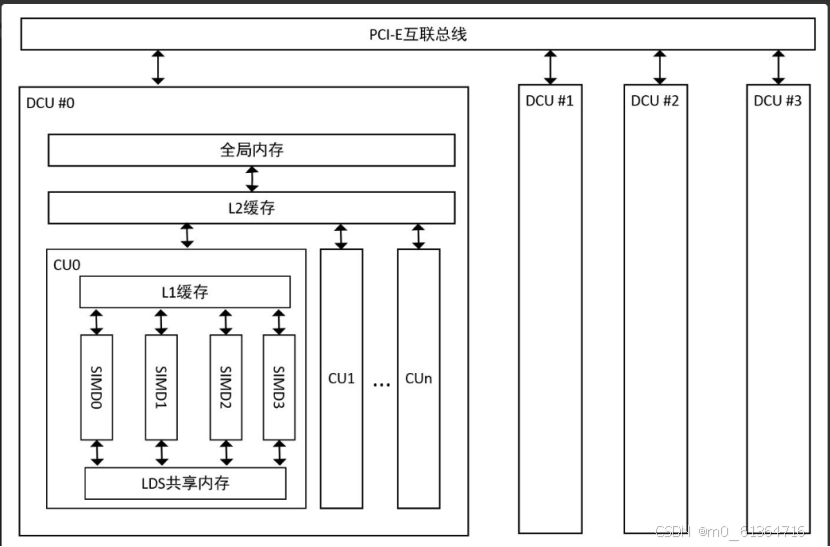
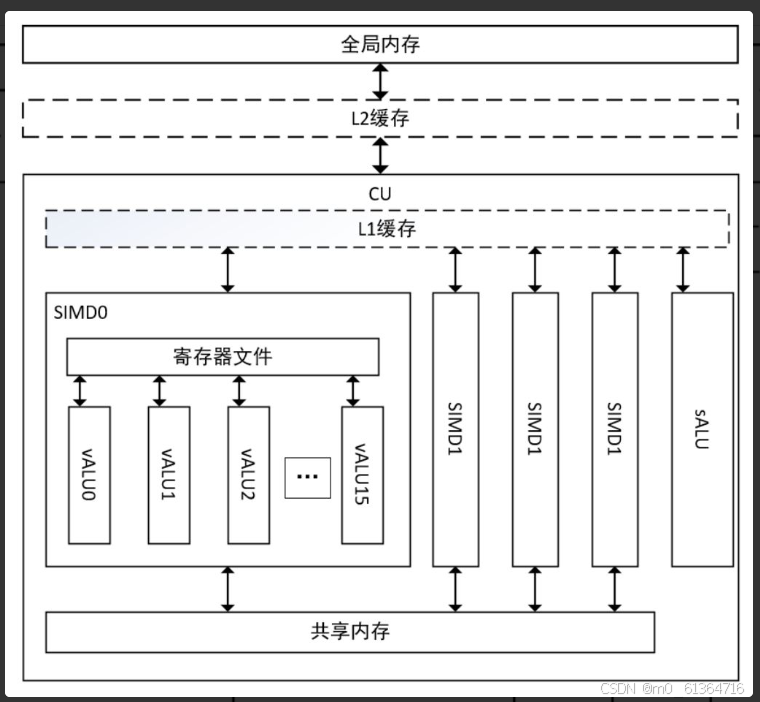
2.1计算单元
DCU里有很多个计算单元阵列(Compute Unit,CU),每个CU又包含4个SIMD(Single Instruction/Multiple Data)单元,每个SIMD单元里又有很多加减乘等流式计算部件,一块DCU卡可以有几千个流处理单元,因此DCU又称之为流处理器。由于DCU中有数千个流处理器,DCU的吞吐量就非常高,如果任务有足够的并行性,DCU可以更快地完成它。
SIMD是CU的计算核心部件,而每个CU包含4个SIMD。每个SIMD有10个wavefront,每个wavefront包含64个线程。而且每个SIMD包含多个矢量计算单元(DCU2上有16个),还有一个被多个SIMD共用的标量计算单元。 这些计算单元可以访问一个所谓的寄存器文件,里面包括矢量寄存器和标量寄存器。当DCU进行并行计算时,线程会被分配到这些计算单元ALU上,因此ALU单元是比较重要的部件。而ALU单元包括矢量计算单元和标量计算单元,其中矢量计算单元主要用于复杂计算,而标量计算单元主要用于地址计算,分支跳转等。 当很多的线程同时启动时,会出现同一个计算单元被多个线程共用的情况,在使用时需要考虑资源的分配情况,合理的将线程进行分配。(CU运行的最小的调度单位被称为wavefront(AKA:warp),每个wavefront包含64个线程。CU中每一个SIMD都可以调度10个并发的wavefront。当有些wavefront处于停滞状态(譬如读取内存),CU会停止当前wavefront,并调度其他的wavefront到前台。显然,这有助于隐藏延迟并最大限度地利用CU的计算资源)(可参考:https://zhuanlan.zhihu.com/p/552573927)
每个CU中包含一个LI缓存,cache系统虽然对用户是编程透明的,但极致性能优化时也有50%以上的影响,需要考虑数据排布和读取方式等优化方法来提升cache命中率。
2.2全局内存(global memory)
DCU有独立于主机内存的全局内存单元,用于存储CU计算时所要访问的数据。为了满足高吞吐需求,会采用相对高速的存储单元,显卡常采用GDDR内存,带宽可达500GB/s,DCU可支持更为先进的HBM2存储,单卡容量可达16GB以上,最高带宽可达1TB/s。全局内存是DCU上的片外存储,所谓片外即指位于计算单元阵列的外面,距离计算单元越远存储延迟越高。所以全局内存虽然是DCU上空间最大的存储,但是其延迟比较高,DCU程序的瓶颈往往就在于数据读取上,在编程中如何优化全局内存也是一个值得思考的问题.
2.3寄存器
寄存器是比较重要的资源,和CPU相比,DCU上的寄存器数量非常多,包括了矢量寄存器和标量寄存器,每个线程有自己的矢量寄存器,最多可以用256个,而标量寄存器是被线程组共用的,每个线程组可以分配16~102个。
寄存器的访问等待时间比较短,因此在进行密集计算时,可以将常用的数据保存在寄存器中,减少数据读取的开销。而不同线程之间也可以通过寄存器来进行数据的交互,因此数据读取延迟就可以通过多个线程来回切换来掩藏掉。
2.4共享内存——LDS
共享内存的作用是数据重用,同NVIDIA GPU架构类似,每个CU单元设计了一个只供自己使用的64KB的共享内存,线程可以通过CU上的共享内存交换数据或者把一些常用的数据放进共享内存中来减少对全局内存的读取次数。共享内存有32个bank,每个bank有4字节(Byte),因此在使用时,需要考虑bank冲突的问题。同NV架构不同点在于这部分是和L1 cache完全分离的。CUDA 修炼笔记(十) -- Bank - 知乎 (zhihu.com)
共享内存,可以用作程序可控的高速缓存,共享内存的使用是由开发者来控制的。可以将多个线程都会用到的数据放到LDS上,这样只需要从全局内存将数据读取一次到共享内存上,数据就可以被CU上的线程共享,通过数据的重用,减少全局数据读取的开销,提高效率。
共享内存和上面介绍的寄存器都是比较重要的资源,这些资源会被分配给CU上的线程,而这些资源是有限的, 所以这些有限的资源就决定了CU上可以活跃的线程数,也就是并行性。
CU是DCU的核心架构,这里需要明确一个并行的概念,DCU的并行性是真正的众核同时并发,所有的线程都会被分配到真实的计算核心(ALU),这一点与CPU是显著不同的,当CPU运行的线程多于自己的核心数目时,那么CPU会基于时间片轮换让每个线程都可以获得计算资源,给人一种众多线程同时运行的假象。一颗CPU的核心往往只有10几个,但是一个DCU的计算核心可以有数百到数千个。所以,DCU和CPU这一不同的硬件特点,决定了DCU适合做计算密集型任务,而CPU负责来做数据处理以及与外部交互的任务。

















 1940
1940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









