







最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Python 爬取网页数据的两种方法
网络抓取是从任何网站或任何其他信息源中提取数据的过程,以你想要查看的格式保存在你的系统中;
包含格式很多,例如CSV、Excel等;文件、XML、JSON等等。Python是最常见的网页抓取语言之一;对于任何网络抓取活动,Python被认为是确保此过程无任何错误进行的最佳方法;
2. 使用pandas 爬取网页数据
2.1 打开网页
打开一个网页,将网址复制下来;

2.2 打开 PyCharm 编译器
先下载pandas库,【文件】=>【设置】=>【项目:xxx】=>【项目解释器】(【File】=>【Settings…】=>【project:xxx】=>【Python Interpreter】),点击+号,在搜索框中输入“pandas”,在下方列表中选中“pandas”,点击安装,等待提示安装完成即可;


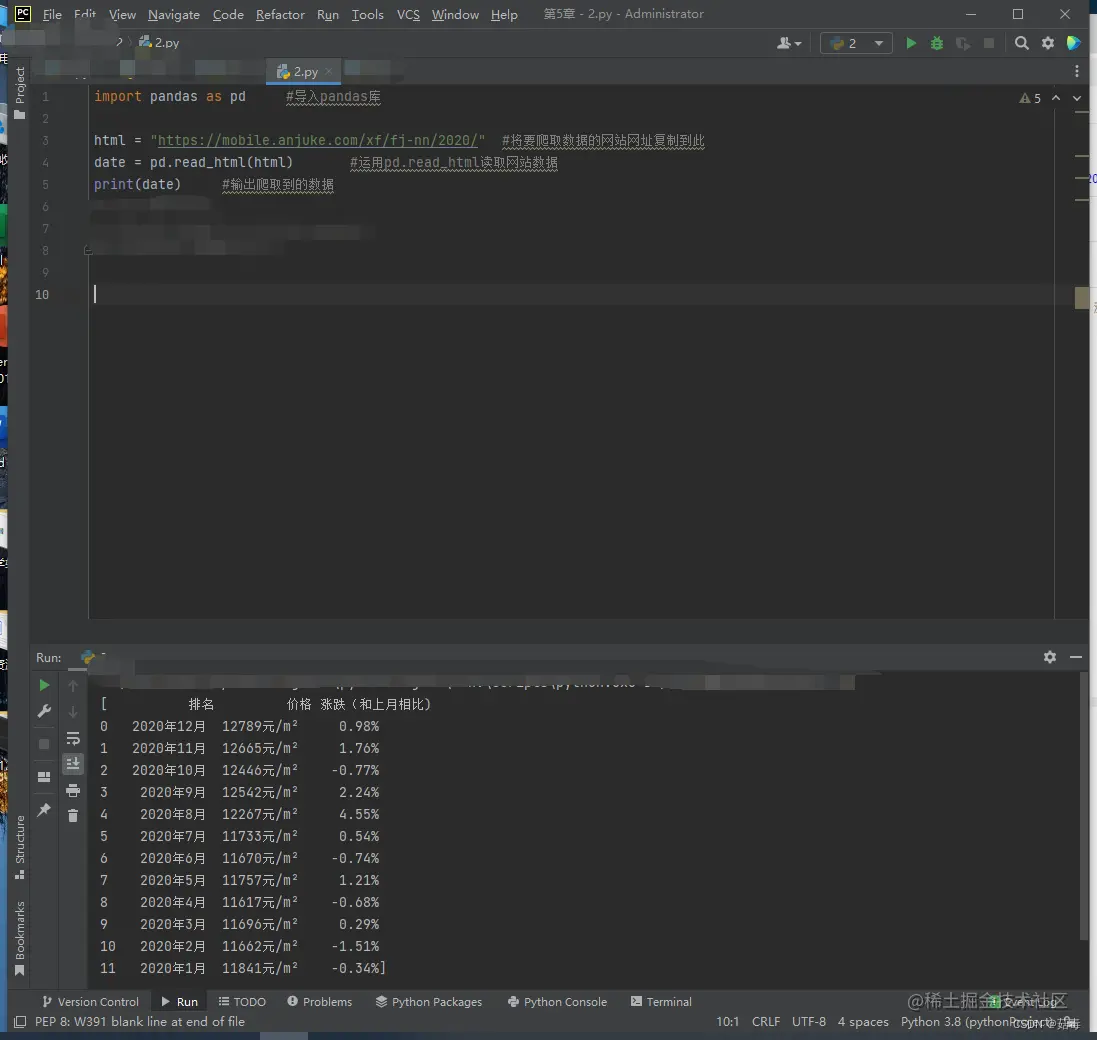
2.回到Pycharm输入以下代码
`import pandas as pd #导入pandas库
html = “mobile.anjuke.com/xf/fj-nn/20…” #将要爬取数据的网站网址复制到此 date = pd.read_html(html) #运用pd.read_html读取网站数据 print(date) #输出爬取到的数据 `
3.运行结果如下所示:
3.使用urllib爬取网页数据并写入Excel表
3.1 下载 urllib 库
与上述方法一致,这里就不赘述了
3.2 代码如下
`import urllib.request #导入urllib库
url = urllib.request.urlopen(“fangjia.gotohui.com/show-39181”…
data = url.read()
dt1 = open(“D:/Code/data/2.xls”,“wb”) #xls表的位置,会自动生成xls表
dt1.write(data) #将数据写入D:/Code/data/2.xls表中
dt1.close()
print(data)`
3.3 运行结果如下

打开目录下的2.xls表,即可看到爬取的数据;

知道你对python感兴趣,所以给你准备了下面的资料~
这份完整版的Python全套学习资料已经上传,朋友们如果需要可以点击链接免费领取或者滑到最后扫描二v码**保证100%免费**】
python学习资源免费分享,保证100%免费!!!
需要的话可以点击这里👉Python学习路线(2023修正版)附涉及资料 (安全链接,放心点击)
文末有福利领取哦~
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3111
3111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









