







引言
机器学习是一种人工智能的分支,旨在让计算机系统通过学习数据来改善其性能。在机器学习中,计算机系统被训练来识别模式和规律,以便能够对新数据做出预测和决策。在机器学习分类模型中,对模型性能进行合理的评估是不可或缺的,通过训练集和测试集之间的评估指标差距,可以判断出模型是否出现过拟合和模型泛化能力等。
常见的机器学习分类模型
机器学习可以分为以下几个主要类别:
-
监督学习:监督学习是指使用已知输入-输出对的数据来训练计算机系统。在监督学习中,计算机系统学习如何将输入映射到输出,以便可以对新数据进行预测。典型的有监督式分类模型有:支持向量机(SVM)、逻辑回归(LR)、决策树(DT)、随机森林(RF)、XGBoost、梯度上升和BP神经网络等。
-
半监督学习:半监督学习是介于监督学习和无监督学习之间的一种机器学习方法。在半监督学习中,部分数据是有标签的,而另一部分数据是没有标签的。通过使用有标签数据,半监督学习可以训练模型来识别和学习数据中的模式和规律。同时,使用未标记数据可以帮助模型更好地理解数据之间的关系,并提高模型的性能和泛化能力。
-
无监督学习:无监督学习是指使用没有标签的数据来训练计算机系统。在无监督学习中,计算机系统必须自行发现数据中的模式和结构,以便可以对新数据进行分类或聚类。典型的无监督学习模型有:K-Means聚类、KNN算法、高斯混合模型(GMM)和Birch聚类等。
分类模型的评估指标
常见的分类模型评估指标是通过混淆矩阵计算其准确率(AUC)、精确率(PRE)、召回率(REC)、F1-Score和AUC等指标,常见的2×2混淆矩阵如表1所示。
| 真实值 | 预测值=1 | 预测值=0 |
| 1 | TP | FN |
| 0 | FP | TN |
在多分类问题中,我们通常首先转化为一对多(One-vs-All)的二分类问题进行处理。对于每一个类别,我们都将其当做一个类别,其他所有类别当做另一个类别。可以计算每个类别的精确率、召回率、F1-Score以及AUC等指标。
-
准确率(Accuracy):准确率是所有预测正确的样本(包括真正例和真负例)占总样本的比例。
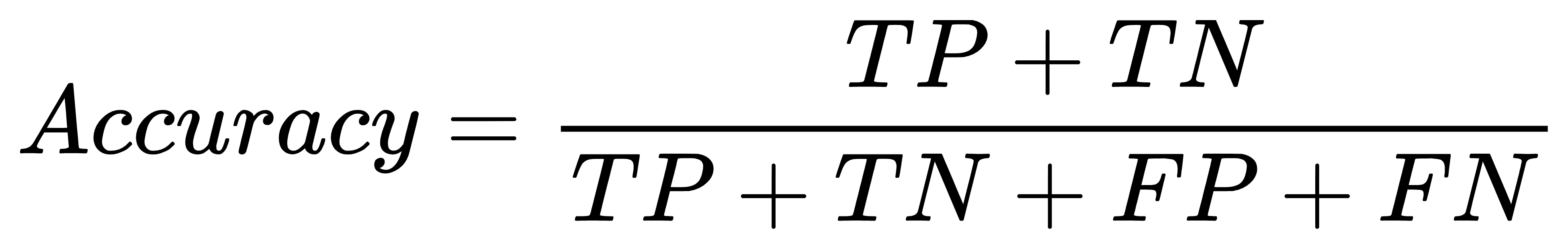
-
精确率(Precision or PRE):精确率是预测为正且预测正确的样本占预测为正的样本的比例,也称为查准率。
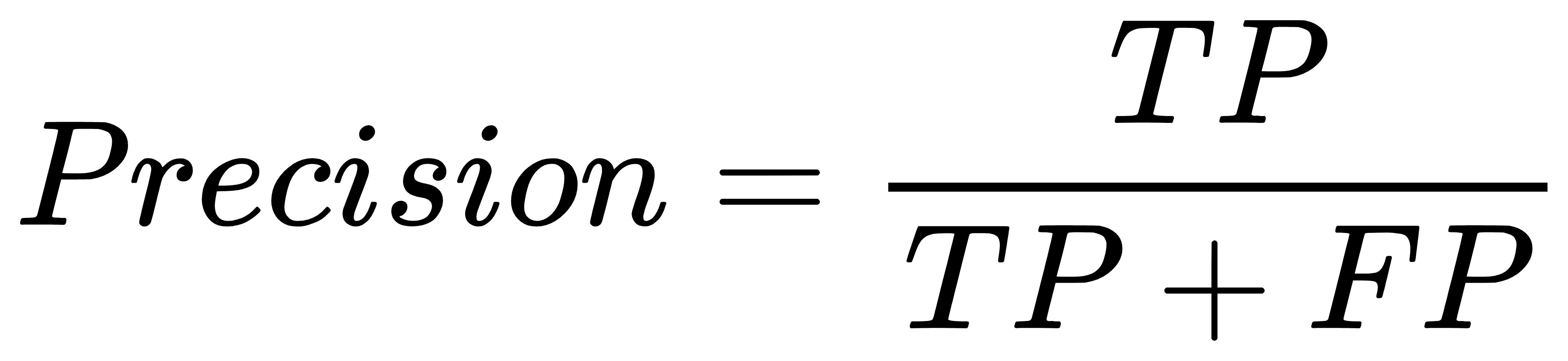
-
召回率(Recall or REC):召回率是预测为正且预测正确的样本占实际为正的样本的比例,也称为查全率。

-
F1-Score:F1-Score是精确率和召回率的调和平均值,用于综合评估模型的性能。

-
ROC和AUC:ROC曲线(Receiver Operating Characteristic Curve)下的面积就是AUC(Area Under Curve),AUC用于衡量模型的排序性能。

在ROC曲线中,横坐标是FPR(False Positive Rate,假正率),纵坐标是TPR(True Positive Rate,真正率)。FPR和TPR的计算公式如下:
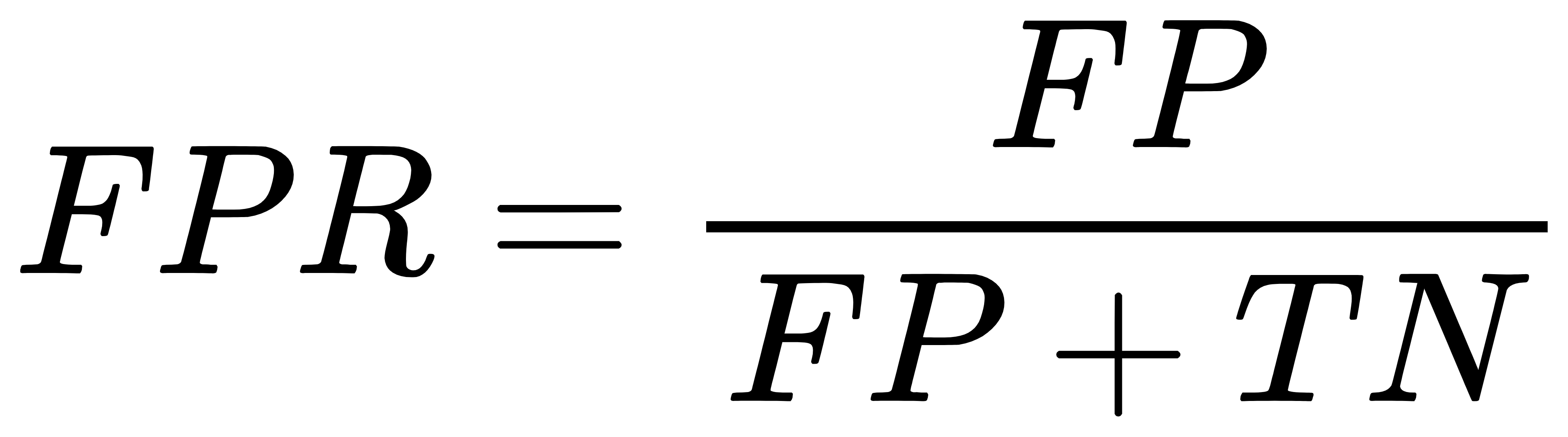

其中,TP(True Positive)是真正例,即预测为正且实际为正的样本数。FP(False Positive)是假正例,即预测为正但实际为负的样本数。FN(False Negative)是假负例,即预测为负但实际为正的样本数。TN(True Negative)是真负例,即预测为负且实际为负的样本数。
















 509
509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











