




简介
分类模型的评判指标光是图就有好多,ROC,AUC,GINI,KS,Lift,Gain,MSE,这些有些是图有些是指标,放在一起乱七八糟搞得人分不清东南西北。所以这里我先整体给大家一个直观的介绍。省的以后再遇上这么多图的时候完全分不清是谁是谁。
三句话概括版本:
Confusion Matrix -> Lift,Gain,ROC。
ROC -> AUC,KS -> GINI。
MSE独立出来。
中文,英文,简称
在介绍之前,我们先重新明确一下这些图表的名称,中文、英文、简称,全部来熟悉一下:
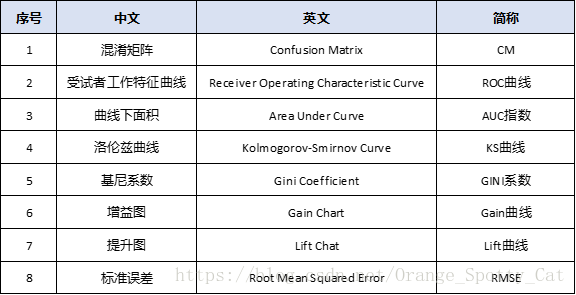
记住这个之后,我们来理解一下他们之间的关系。
拟人化概括
其实,这些图之间的关系不是很复杂。我尝试着用一个小故事概括一下8位登场人物之间的关系。
故事是这样的:
首先,混淆矩阵是个元老,年龄最大也资历最老。创建了两个帮派,一个夫妻帮,一个阶级帮。
之后,夫妻帮里面是夫妻两个,一个Lift曲线,一个Gain曲线,两个人不分高低,共用一个横轴。
再次,阶级帮里面就比较混乱。
1. 帮主是ROC曲线。
2. 副帮主是KS曲线,AUC面积
&nb
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9129
9129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









