







一、编码问题
#文件读写常见问题探索
fo = open("dict.txt","r")
txt = fo.read()
print(txt)
fo.close()
dict.txt编码为utf-8,open时未指定编码,直接读取时有可能报错
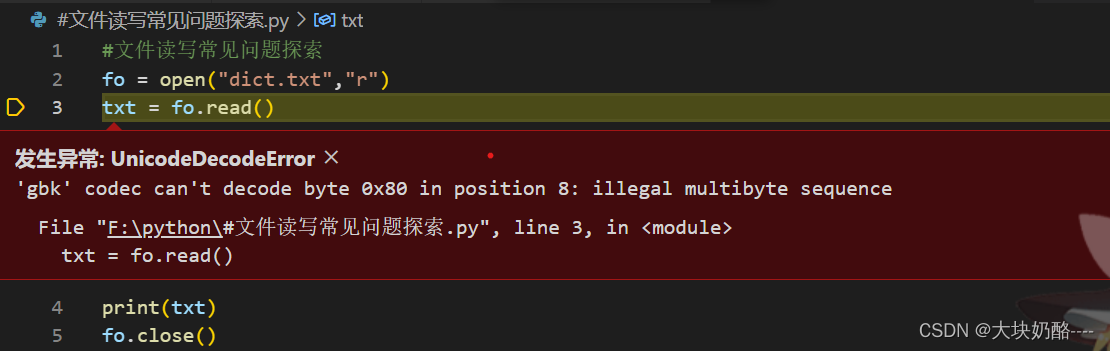
文件内容显示乱码,如下图
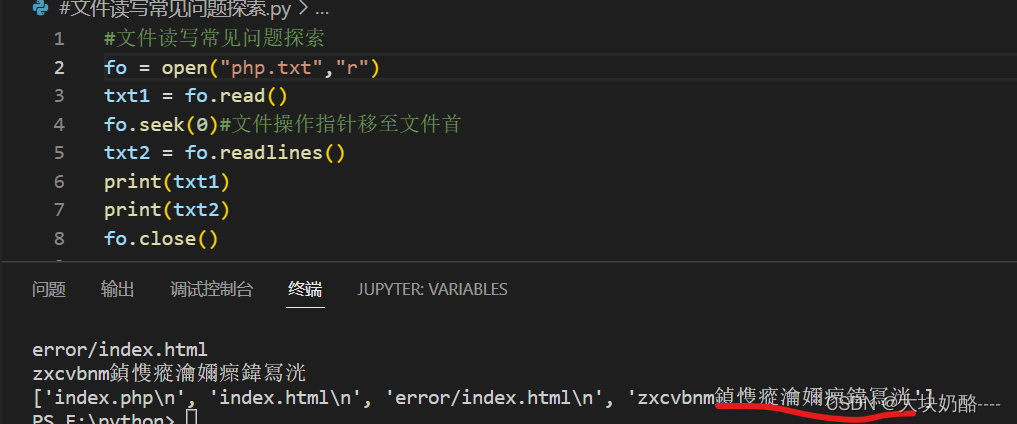
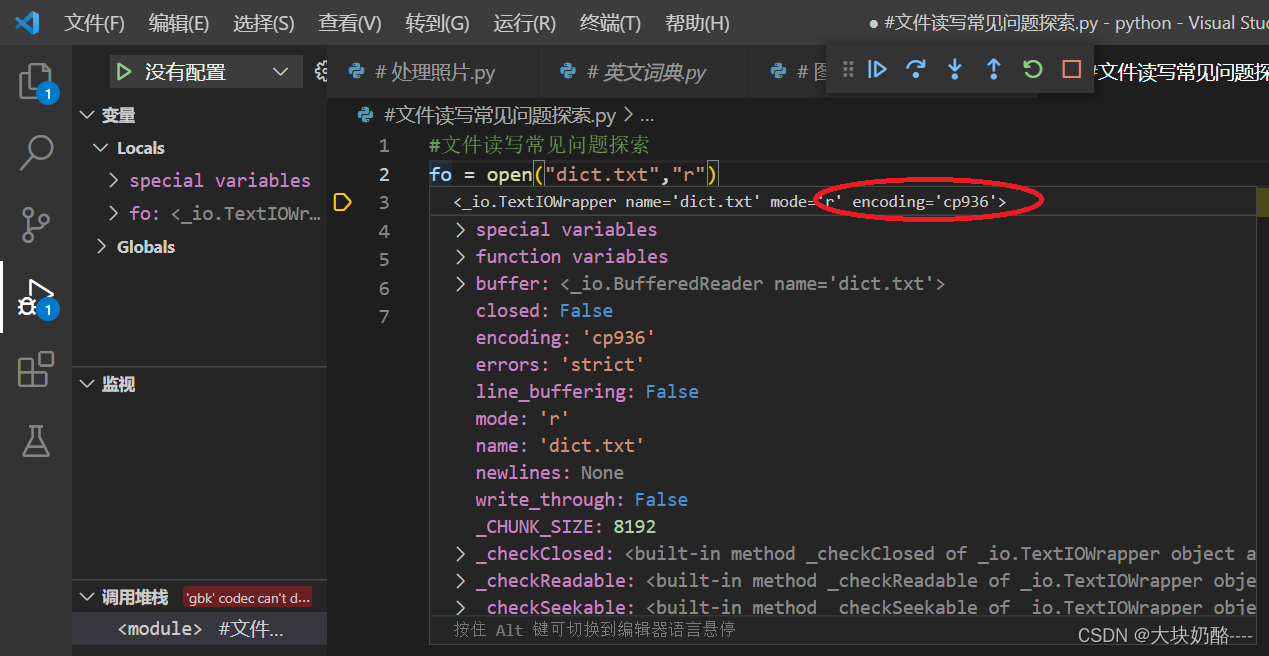
鼠标移至fo变量,可以看到默认编码方式为cp936
GB2312是中国规定的汉字编码,也可以说是简体中文的字符集编码
GBK 是 GB2312的扩展 ,除了兼容GB2312外,它还能显示繁体中文,还有日文的假名
cp936是指系统里第936号编码格式,即GB2312的编码((当然有其它编码格式:cp950 繁体中文、cp932 日语、cp1250 中欧语言),中文本地系统是Windows中的cmd,默认codepage是CP936
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
UTF-8 (8-bit Unicode Transformation Format)是最流行的一种对 Unicode 进行传播和存储的编码方式。它用不同的 bytes 来表示每一个代码点。ASCII 字符每个只需要用一个 byte ,与 ASCII 的编码是一样的。所以说 ASCII 是 UTF-8 的一个子集。ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码。中文操作系统中ANSI编码其实是GBK编码,而韩文系统中ANSI编码其实是EUC-KR编码等。
2.将dict.txt另存ANSI格式,重新执行以上代码,可以正常打开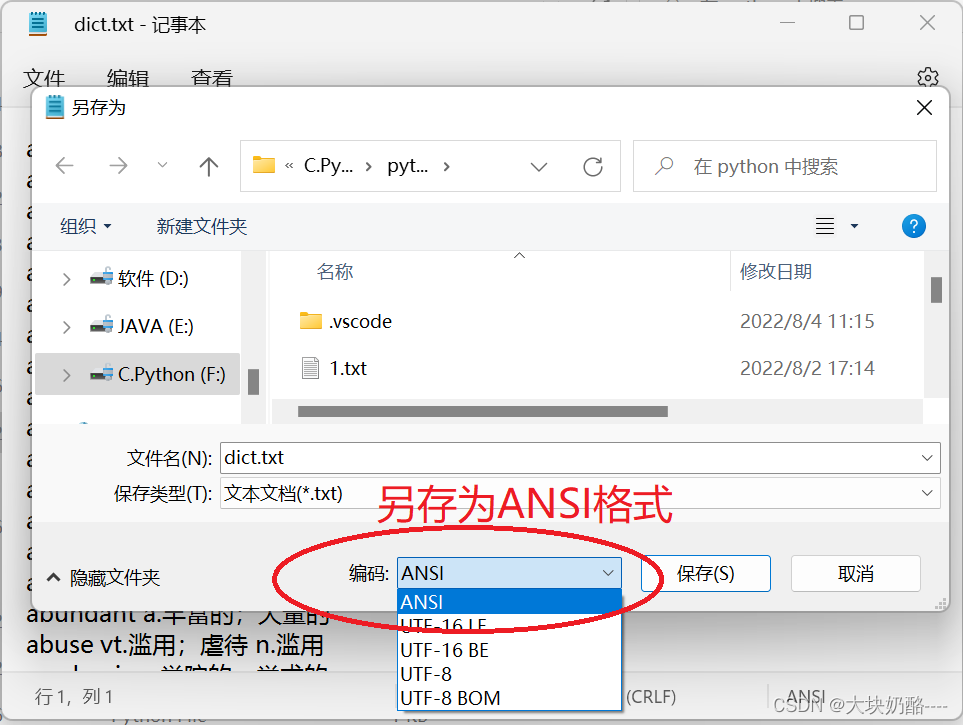
3. 以fo = open("dict.txt","r",encoding='utf-8')方式读取ANSI格式文本,同样报错 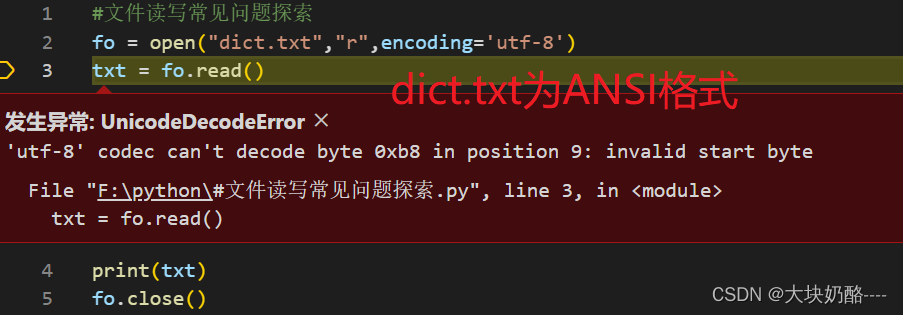
结论:open()函数打开文件的编码格式必须要与文件的编码格式一致!二进制方式打开任意文件,转码需要注意编码方式。文本文档建议保存为ANSI
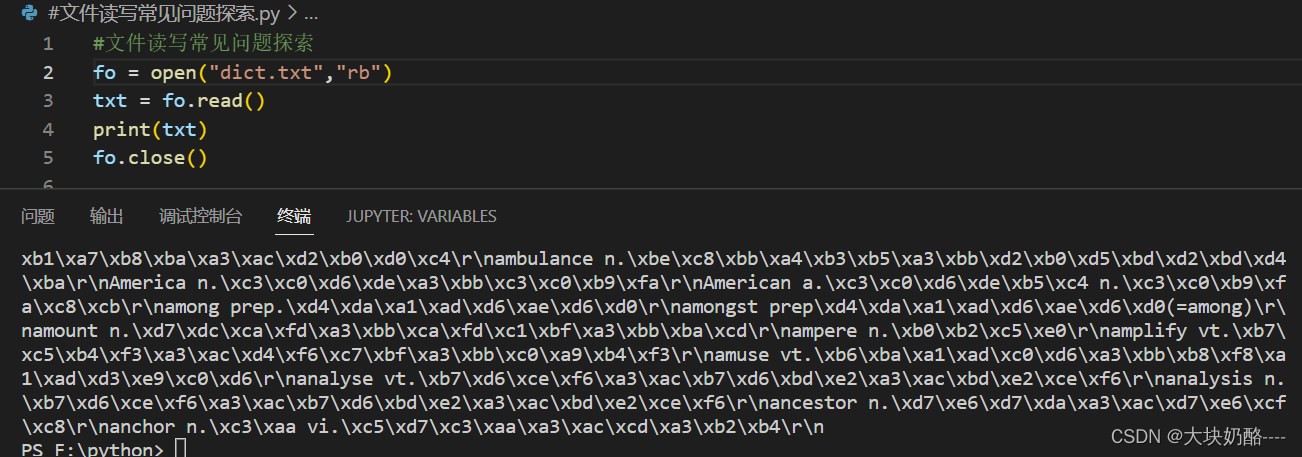
二、read和readlines读取结果的差异
#文件读写常见问题探索
fo = open("php.txt","r")
txt1 = fo.read()
fo.seek(0)#文件操作指针移至文件首
txt2 = fo.readlines()
print(txt1)
print(txt2)
fo.close()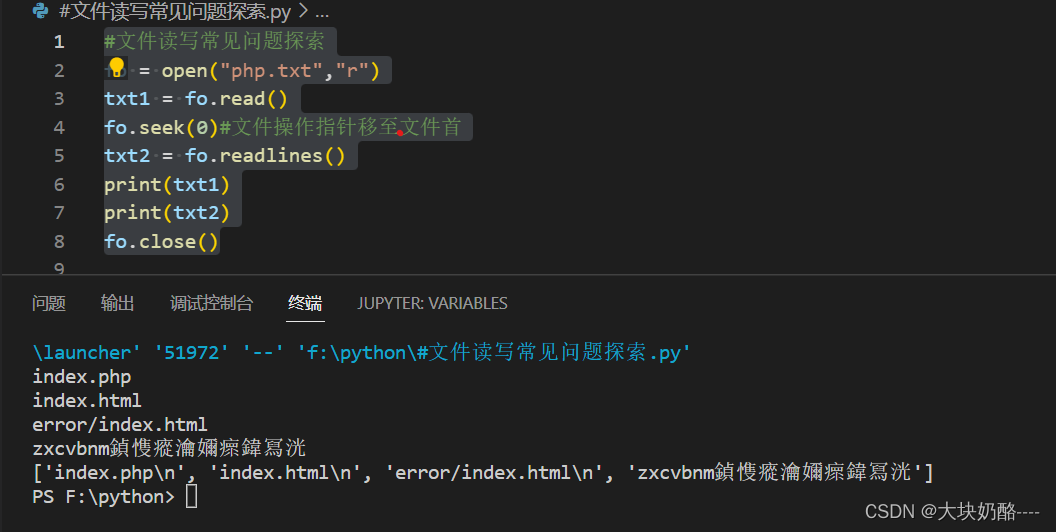
read()读取的结果为文本文档的原样输出
redlines()读取结果为以文本文档的每一行为字符串元素的列表形式的字符串(如何转为列表、字典,详见笔记九)
三、read读取不全问题
测试中发现read()读取文件,print(fo.read()),结果显示不完整!经分析发现:并非read()读取不全,而是print()函数问题,导致显示不全!
四、a+模式,先read后无法write问题
文件以a+模式打开后,执行read()函数后,即使使用seek(0)重定位到文件头,seek(2)重定位到文件尾,均无法再执行write()写文件,原因为文件打开后需要关闭以释放对文件的控制,使文件回复存储状态,此时另一个进行才可以操作这个文件!
五、使用正则格式化字符串
详见笔记九















 2980
2980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









