







 本文通过大数据分析和可视化,探讨高中教学系统的概况,包括各年级人数统计、住宿生分布、学生政治面貌和家庭类型。数据显示高一人数最多,住校生在高一占比最高,大多数学生为共青团员,家庭类型均为城镇。此外,食堂人流可视化揭示了早晚高峰期,而学业成绩分析显示数学、英语和语文成绩突出。
本文通过大数据分析和可视化,探讨高中教学系统的概况,包括各年级人数统计、住宿生分布、学生政治面貌和家庭类型。数据显示高一人数最多,住校生在高一占比最高,大多数学生为共青团员,家庭类型均为城镇。此外,食堂人流可视化揭示了早晚高峰期,而学业成绩分析显示数学、英语和语文成绩突出。
目录
前言
教育行业中大数据分析的主要目的包括改善学生成绩、服务教务设计、优化学生服务等。而学生成绩中有一系列重要的信息往往被我们常规研究所忽视。通过大数据分析和可视化展示,挖掘重要信息,改善 学生服务,对于教学改进意义重大。美国教育部门构建“学习分析系统”,旨在向教育工作者提供了解学生到底是在怎样学习的更好、更好、更精确信息。利用大数据的分析学习能够向教育工作者提供有用的信息,从而帮助其回答众多不易回答的现实问题。未来学生的学习行为画像、考试分数、发展潜力方向等所有重要信息的数据价值将会持续被显现出来,大数据将帮助我们革新学生的学习、教师的教学、教育政策制定的方式与方法等。
比赛官网链接:“数智教育”数据可视化创新大赛
本案例数据来源于天池大数据竞赛中宁波教育局提供的“数智教育”数据可视化创新大赛数据集,数据集共7个CSV文件,所含数据字段如下:
- 1_teacher.csv:包含了近五年各班各学科的教师信息
| 字段名 | 字段含义 |
| term | 学期 |
| cla_id | 班级ID |
| cla_Name | 班级名 |
| gra_Name | 年级名 |
| sub_id | 学科ID |
| sub_Name | 学科名 |
| bas_id | 教师id |
| bas_Name | 教师名 |
- 2_studentinfo.csv:包含了当前在校学生详细信息
| 字段名 | 字段含义 | 字段名 | 字段含义 |
| bf_StudentID | 学生ID | Bf_ResidenceType | 家庭类型 |
| bf_Name | 学生姓名 | bf_policy | 政治面貌 |
| bf_sex | 性别 | cla_id | 班级ID |
| bf_nation | 民族 | cla_term | 班级学期 |
| bf_BornDate | 出生日期(年) | bf_zhusu | 是否住校 |
| cla_Name | 班级名(与teacher.csv的cla_name对应) | bf_leaveSchool | 是否退学 |
| bf_NativePlace | 家庭住址(省市或省) | bf_qinshihao | 宿舍号 |
- 3_kaoqin.csv: 包含学生考勤信息
| 字段名 | 字段含义 | 字段名 | 字段含义 |
| kaoqin_id | 考勤ID | control_task_order_id | 对应考勤类型表里的control_task_order_id |
| qj_term | 学期 | bf_studentID | 学生ID,对应学生信息表 |
| DataDateTime | 时间和日期 | bf_Name | 学生姓名 |
| ControllerID | 对应考勤类型表里的ControllerID | cla_Name | 班级名 |
| controler_name | 考勤名称 | bf_classid | 班级ID |
- 4_kaoqintype.csv:考勤类型
| 字段名 | 字段含义 |
| controler_id | 考勤类型id |
| controler_name | 考勤类型名称 |
| control_task_order_id | 考勤事件id |
| control_task_name | 考勤事件名 |
- 5_chengji.csv:学生成绩
| 字段名 | 字段含义 | exam_type | 考试类型(对应考试类型表) |
| mes_TestID | 考试id | exam_sdate | 考试开始时间 |
| exam_number | 考试编码 | mes_StudentID | 学生id |
| exam_numname | 考试编码名称 | mes_Score | 考试成绩(-1为作弊,-2为缺考,-3为免考) |
| mes_sub_id | 考试学科id | mes_Z_Score | 换算成Z-score(Z-score、T-score、等第 是一种学生成绩评价方式,可以参考网络百科) |
| mes_sub_name | 考试学科名 | mes_T_Score | 换算成T-score |
| exam_term | 考试学期 | mes_dengdi | 换算成等第 |
- 6_exam_type.csv:考试类型
| 字段名 | 字段含义 |
| EXAM_KIND_ID | 考试类型id |
| EXAM_KIND_NAME | 考试类型名称 |
- 7_consumption.csv:本学年学生消费信息
| 字段名 | 字段含义 |
| DealTime | 消费时间 |
| MonDeal | 消费金额 |
| bf_studentID | 对应学生信息表studentid |
| AccName PerSex | 姓名 性别 |
特别说明:
- 1.由于人为登记等不可避免原因,某些字段可能存在缺失或者异常值
- 2.从班级名可以看出,从2017年开始学校陆续启用了新校区,2018年新校区统一命名为型为“白-高二(01)”和“东-高二(01)”的班级名
- 3.考勤类型中的“校服[移动考勤]”指的是没穿校服3.考勤类型中的“校服[移动考勤]”指的是没穿校服
导入库
import pandas as pd
import numpy as np
import os
import pyecharts
from pyecharts import options as opts
from pyecharts.charts import *
import seaborn as sns
import matplotlib.pyplot as plt
from pyecharts import *
from pyecharts.faker import Faker
sns.set(font='SimHei', style='white', ) # 解决Seaborn中文显示问题
import warnings
warnings.filterwarnings('ignore')读取数据 (path为文件目录地址)
teacher = pd.read_csv(path+"/1_teacher.csv")
student = pd.read_csv(path+"/2_student_info.csv")
kaoqin =pd.read_csv(path+"/3_kaoqin.csv")
kaoqintype = pd.read_csv(path+"/4_kaoqintype.csv")
chengji = pd.read_csv(path+"/5_chengji.csv")
exam_type = pd.read_csv(path+"6_exam_type.csv")
consumption = pd.read_csv(path+"/7_consumption.csv")概况信息分析
本案例首先对学校数据进行基础的概况描述,通过可视化图形来对原始数据进行直观的表达,利用基础图形如柱状图、饼状图、旭日图、水滴图等对各年级的人数分布,住宿情况、生源地、政治面貌、家庭类型等进行数据可视化。
1)各年级人数统计分析
首先,通过绘制条形图对学校各年级人数进行统计分析,如图14-42所示,可以看到该学校高一人数最多为702人,高二人数和高三人数为555和508,高三人数最少。
#统计高一高二高三的人数
list1 = ['高一','高二','高三']
list2 = [702,555,508]
s = sns.barplot(x = list2,y = list1)
for container in s.containers:
s.bar_label(container)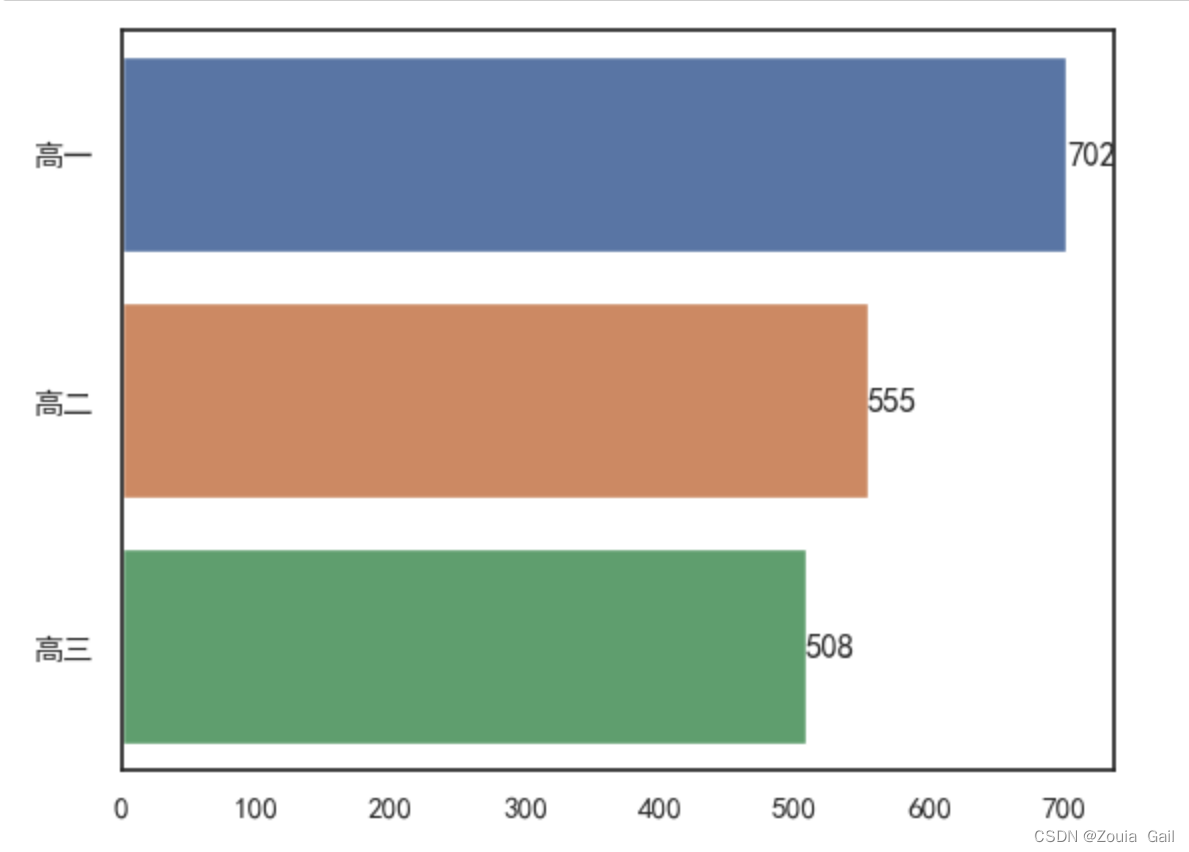
其次通过绘制环形图可以更加清晰地表现出各年级人数占比情况。可以看到高一占比为40%,为全校人数最多的年级,高二和高三占比相似,各占30%左右。可以看出该学校处于扩招状态。
c = (
Pie(init_opts=opts.InitOpts(width="800px", height="500px")) # 图形的大小设置
.add(
series_name="学校人数分布",
data_pair=[list(z) for z in zip(list1, list2)],
radius=["30%", "50%"], # 饼图内圈和外圈的大小比例
center=["30%", "40%"], # 饼图的位置:左边距和上边距
label_opts=opts.LabelOpts(is_show=True), # 显示数据和百分比
)
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", orient="vertical")) # 图例在左边和垂直显示
.set_series_opts(label_opts=opts.LabelOpts(position="outside",formatter="{b}:{c}({d}%)"),
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
)
)
c.render_notebook()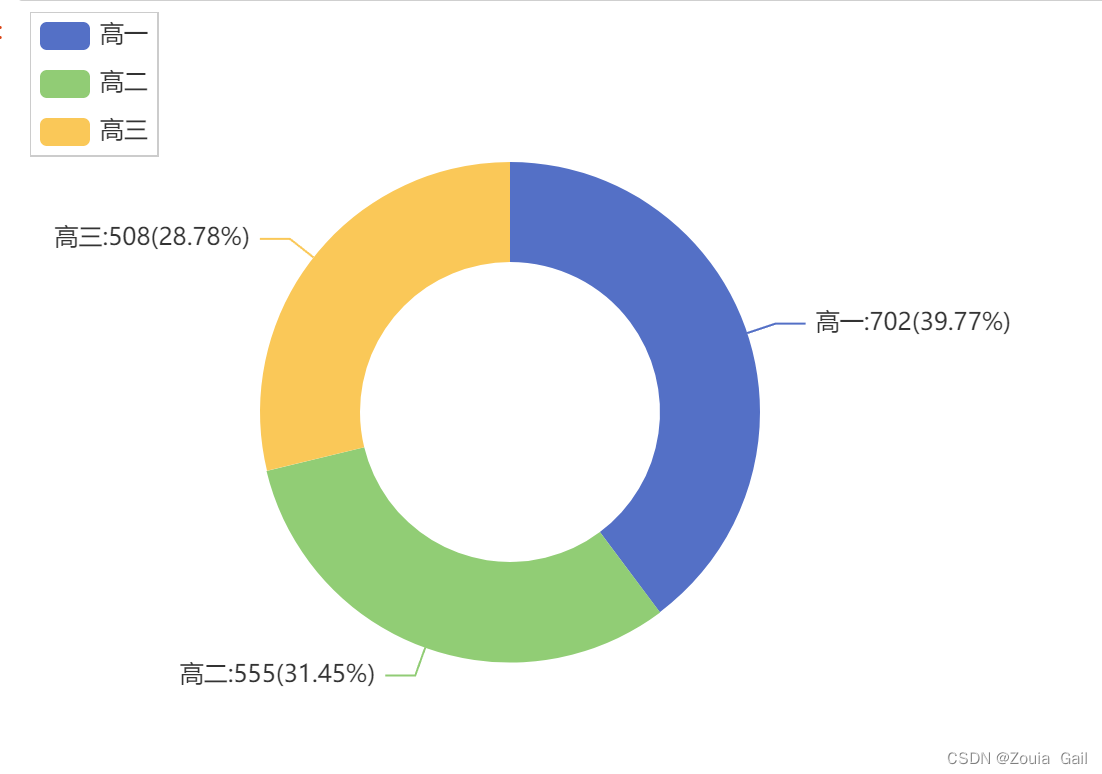
进一步绘制各班级占全校人数之比的饼图,可以看到饼图每个部分都较为均匀,说明每个班级的人数差不多都在40左右,可能不存在尖子班。
attr = student['cla_Name'].value_counts().index.tolist()
v1 = student['cla_Name'].value_counts().values.tolist()
c = (
Pie()
.add("", [list(z) for z in zip(attr,v1)],center=["40%","50%"]) # zip函数两个部分组合在一起list(zip(x,y))-----> [(x,y)]
.set_global_opts(title_opts=opts.TitleOpts(title="各班级占全校人数之比的饼图"),legend_opts=opts.LegendOpts(type_="scroll",pos_left="80%",orient="vertical")) # 标题
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")) # 数据标签设置
)
c.render_notebook()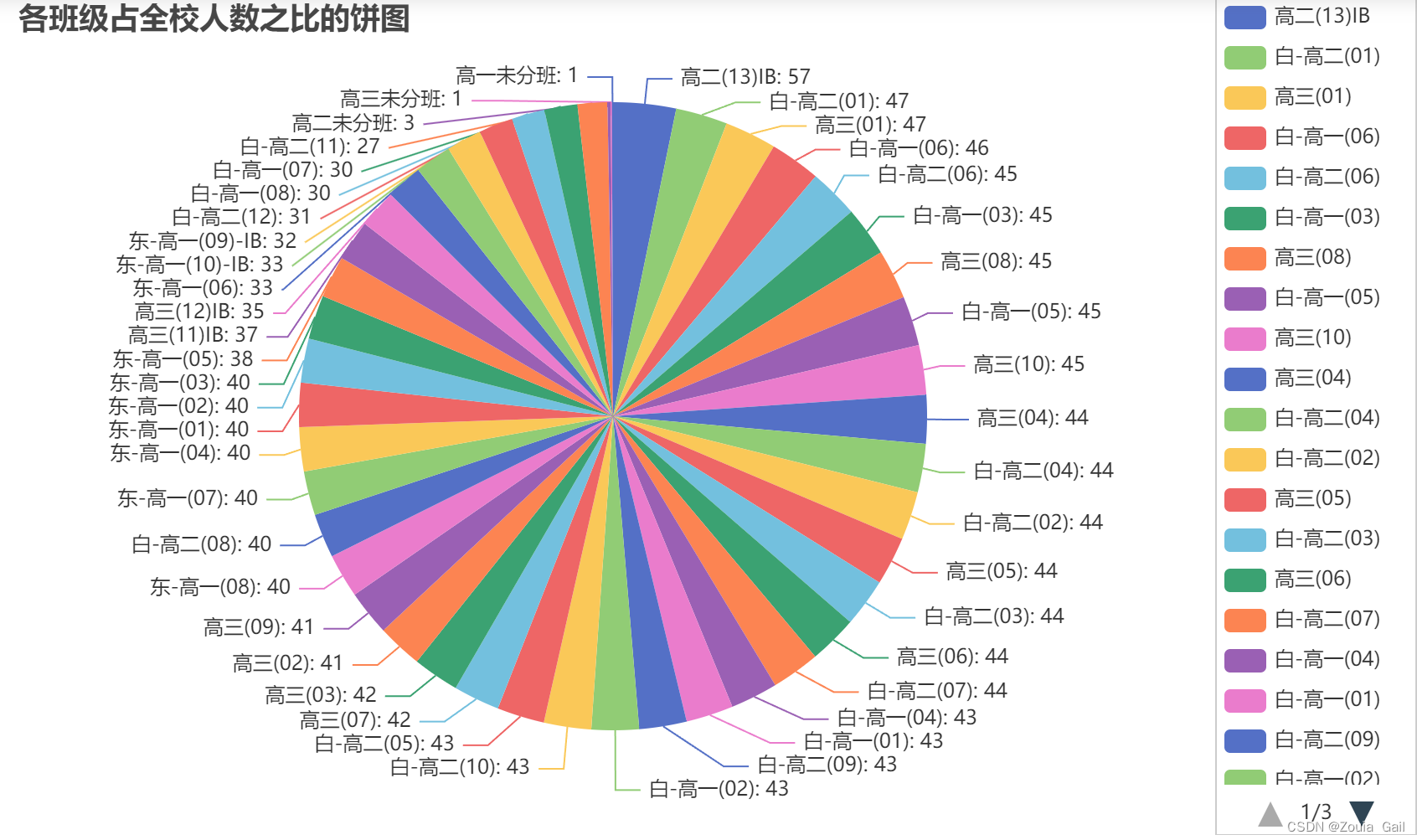
2)住宿生统计分析
通过旭日图和圆环图可以看到,高一住校生占比最大,为63%,高二住校生占比第二,为33%,高三住校生相对较少,仅占年级人数的17%。结合各年级人数分析得到的扩招结论,推测出高一扩招的学生大部分为住校生。
data = [
opts.SunburstItem(
name="高一",
children=[
opts.SunburstItem(name="是", value=442),
opts.SunburstItem(name="否", value=260)
]
),
opts.SunburstItem(
name="高二",
children=[
opts.SunburstItem(name="是", value=374),
opts.SunburstItem(name="否", value=181)
]
),
opts.SunburstItem(
name="高三",
children=[
opts.SunburstItem(name="是", value=85),
opts.SunburstItem(name="否", value=423)
]
)]
c = (
Sunburst(init_opts=opts.InitOpts(page_title="住宿生分布旭日图"))
.add(
"人数",
data,
radius=["20%", "85%"],label_opts=opts.LabelOpts(is_show=False, position="center")
)
.set_global_opts(title_opts=opts.TitleOpts(title="住宿生分布旭日图", pos_left="center"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()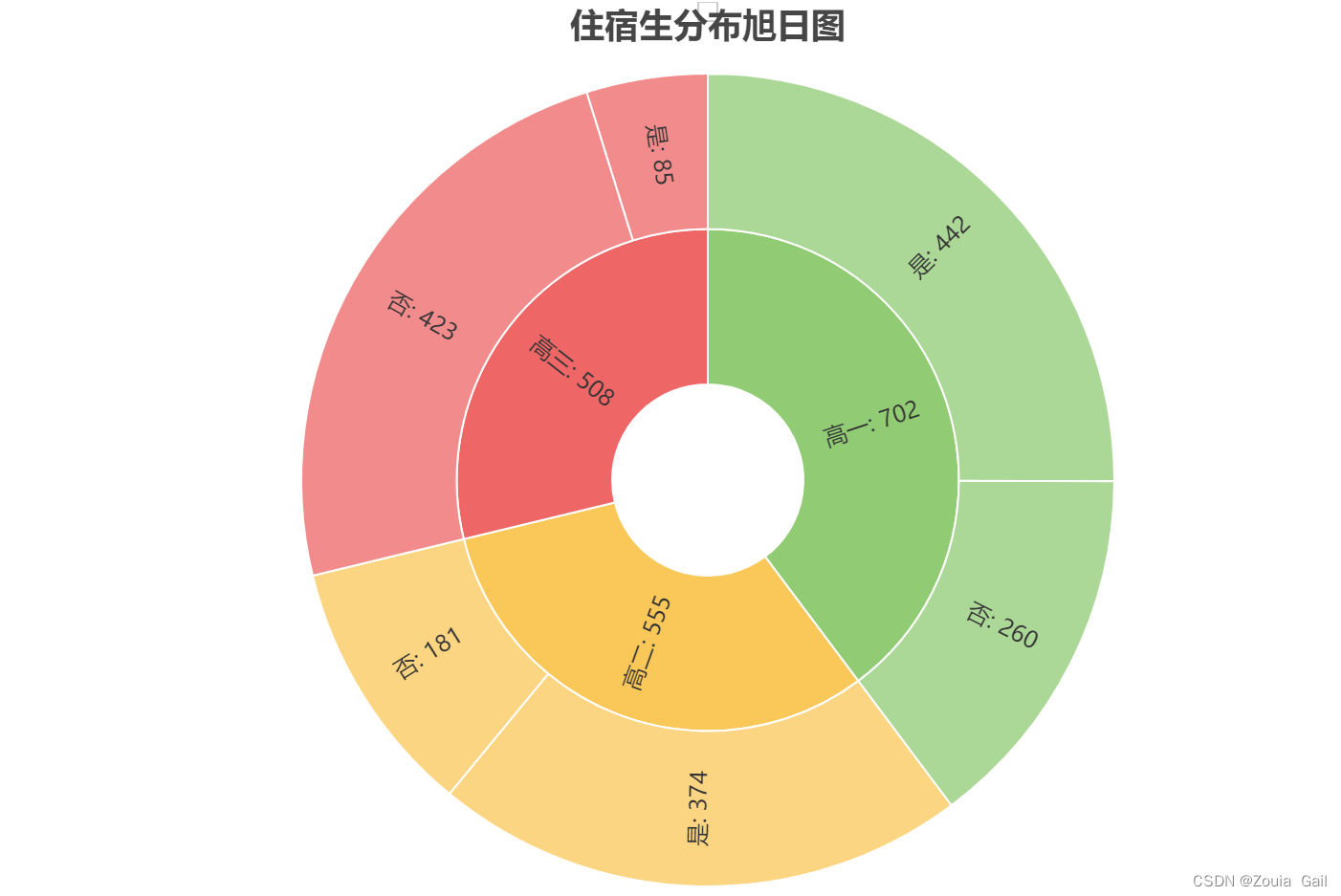
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.commons.utils import JsCode
c = (
Pie()
.add(
"",
[list(z) for z in zip(["高三走读", "高三住校"], [423.83,85.17])],
center=["20%", "70%"],
radius=[60, 40],
)
.add(
"",
[list(z) for z in zip(["高二走读", "高二住校"], [181.33, 260.37])],
center=["50%", "70%"],
radius=[60, 40],
)
.add(
"",
[list(z) for z in zip(["高一走读", "高一住校"], [260.37, 442.63])],
center=["78%", "70%"],
radius=[60, 40],
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: ({c}%)"), pos_left="40%")
.set_global_opts(
title_opts=opts.TitleOpts(title="住校情况组合圆环图"),
legend_opts=opts.LegendOpts(
type_="scroll", pos_top="20%", pos_left="80%", orient="vertical"
),
)
)
c.render_notebook()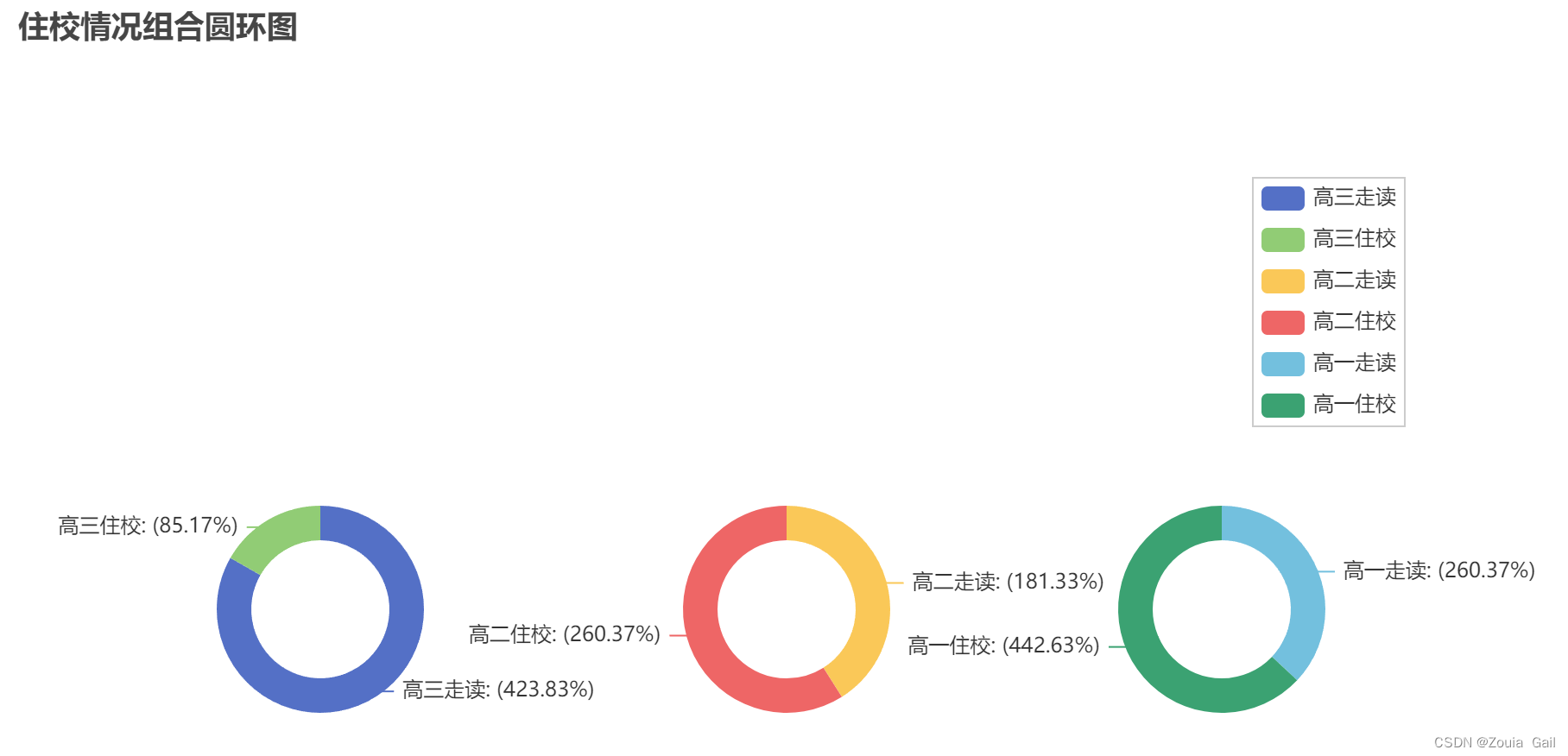 3)学生政治面貌分布
3)学生政治面貌分布
通过政治面貌分布可以看到,大约90%的学生都是共青团员,还未 入团的少先队员占8%,还有极少部分的党员和民主党派占2%。
c = (
Pie(init_opts=opts.InitOpts(width="800px", height="500px")) # 图形的大小设置
.add(
series_name="学校人数分布",
data_pair=[list(z) for z in zip(df_student['bf_policy'].value_counts().index.tolist(),df_student['bf_policy'].value_counts().values.tolist())],
radius=["30%", "50%"], # 饼图内圈和外圈的大小比例
center=["50%", "60%"], # 饼图的位置:左边距和上边距
label_opts=opts.LabelOpts(is_show=True), # 显示数据和百分比
)
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", orient="vertical")) # 图例在左边和垂直显示
.set_series_opts(label_opts=opts.LabelOpts(position="outside",formatter="{b}:{c}({d}%)"),
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
)
)
c.render_notebook()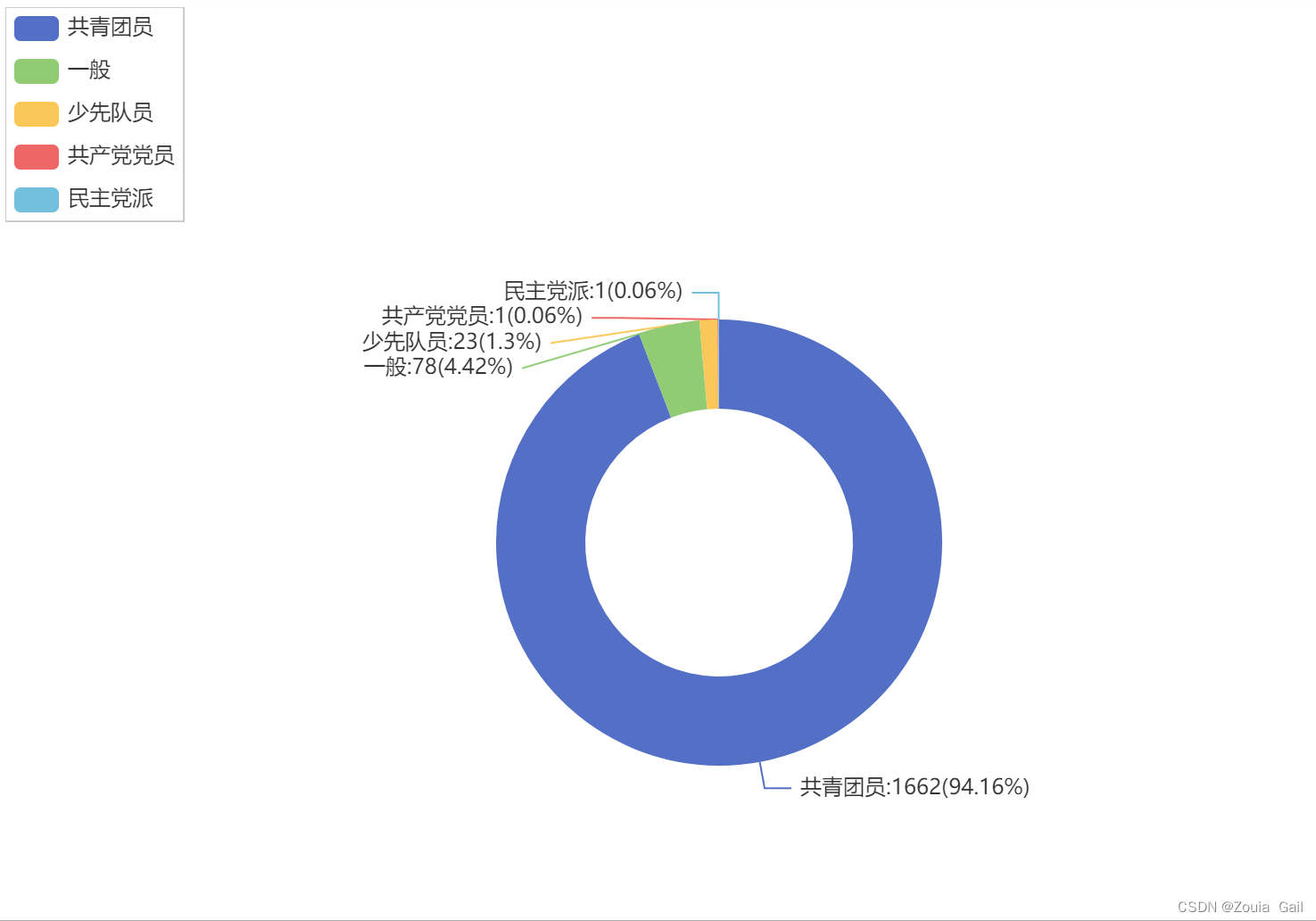
4)学生家庭类型分布
通过学生家庭类型分布图可以看到所有学生家庭类型都是城镇,没有来自农村家庭的学生。
c = (
Pie(init_opts=opts.InitOpts(width="800px", height="500px")) # 图形的大小设置
.add(
series_name="学校人数分布",
data_pair=[list(z) for z in zip(['城市','农村'],[1765,0])],
radius=["30%", "50%"], # 饼图内圈和外圈的大小比例
center=["50%", "60%"], # 饼图的位置:左边距和上边距
label_opts=opts.LabelOpts(is_show=True), # 显示数据和百分比
)
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", orient="vertical")) # 图例在左边和垂直显示
.set_series_opts(label_opts=opts.LabelOpts(position="outside",formatter="{b}:{c}({d}%)"),
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
)
)
c.render_notebook()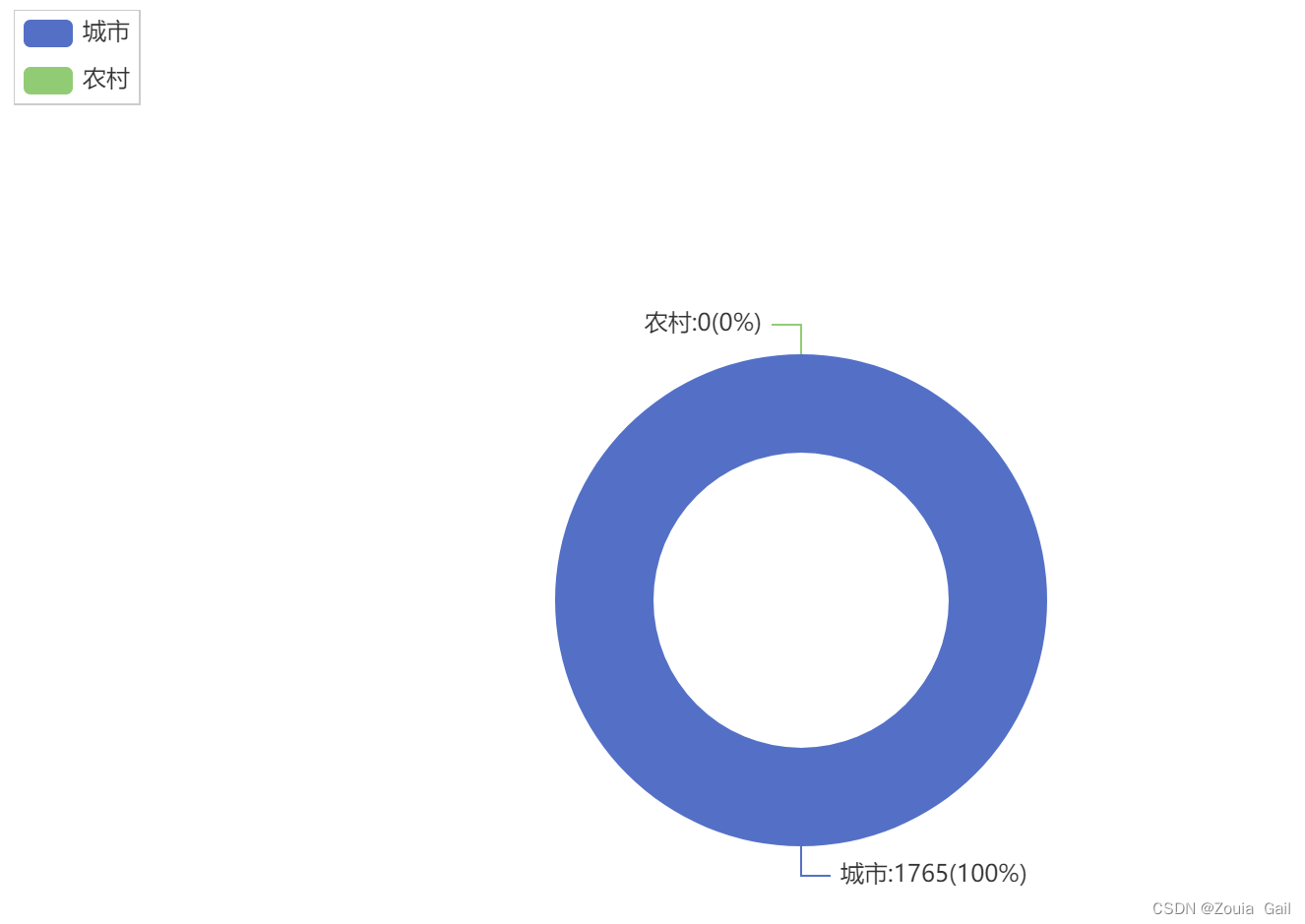
from pyecharts import options as opts
from pyecharts.charts import Liquid
from pyecharts.globals import SymbolType
c = (
Liquid()
.add("lq", [1,0 ], is_outline_show=False, shape=SymbolType.RECT)
.set_global_opts(title_opts=opts.TitleOpts(title="学生家庭类型分布水滴图"))
)
c.render_notebook()
 3.2食堂人流可视化分析
3.2食堂人流可视化分析
通过对食堂打卡记录数据分析绘制带时间滑杆的时间序列图,可以通过滑动时间轴来找到需要观察的时间点,从而观察 到每天食堂的高峰期,制定计划来进行食堂分流。通过图可以看到,每天食堂人流量在6:30——7:00是早饭高峰期,12:00左右是午饭高峰期,其次上午的大课间食堂也有两个小高峰,说明学生会在这两个时间段去食堂购买小吃。
3.3学业成绩分析
1)全校考试成绩分布
通过箱线图对各科成绩分布进行可视化分析。1。体育、美术、音乐、信息技术、通用技术等的箱线图长度较短,说明这几个科目的成绩稳定均匀,与之有关的影响较少,在于学生的个人选择及天赋,可不必投入较多资源。2.该学校的数学、英语、语文平均成绩明显较其他科目成绩好,说明该校的主要的教师资源,人力资源主要集中在三大学科上。


















 226
226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











