







【Pytorch】基于GRU和LSTM的时间序列数据预测实现
1.实现结果:


蓝色曲线为原数据集,包含1000个点(sin函数),训练集占80%。
橙色曲线为网络的预测值,前80%参加了训练,但是20%没有参加训练,看形状,效果还不错。
2.数据集的准备:
下面附上数据集准备的代码:(因为是模块化的编程方式,在代码的第一行我会表注其所在的模块)
首先产生原始的1000个数据点
'''data_preparation模块'''
# 导入需要的库
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
T = 1000
x = torch.arange(1, T + 1, dtype=torch.float32)
y = torch.sin(0.01 * x) + torch.normal(0, 0.1, (T,))#每个y加上一个0到0.1(左闭右开)的噪声
plt.plot(x, y)
plt.show()
输出:

下面这段是产生数据集的最需要注意的地方:
因为是模仿的时间序列的预测,所以必须在数据集上要体现时序的特性,比如我们可以用序列的某八个数字预测该子序列的后一个数字,那么数据集中的第一条数据的特征就为[y0,y1,y2,y3,y4,y5,y6,y7],目标值为[y8],第二条为[y1,y2,y3,y4,y5,y6,y7,y8],目标值为[y9],依次类推,直到目标值为[y999]。(这里是以我们当前的数据集为例,1000个数据点,从0开始,最后为有y999)
当然也可以用某长度为8的子序列预测该子序列的后2位数字,此时这数据集中的第一条数据就应该为[y0,y1,y2,y3,y4,y5,y6,y7],目标值为[y8, y9],第二条就应该为[,y2,y3,y4,y5,y6,y7,y8,y9],目标值为[y10,y11],同样以此类推,直到最后目标值为[y998,y999]。上面的两个例子,第一个例子的数据集总共992条,第二个例子的数据集总共496条,有兴趣的话,自己推算一下,就出来了。
当然可以以任意长的子序列预测子序列之后任意长的序列,但是就是准确度会有影响。本文所提供的代码实现了这一功能,随意定义用于预测的子序列长度lengths,随意定义待续测的序列长度targets。
'''data_preparation模块'''
'''
lengths :决定了用于预测序列的长度
targets :表示待预测的序列长度
例如lengths = 8, targets = 1,则表示用8个数预测一个数
'''
lengths = 8
targets = 1
def data_prediction_to_f_and_t(data, num_features, num_targets):
'''
这段函数为拆分数据的关键,num_features为用于预测的子序列的长度,num_targets表示待预测序列的长度
'''
features, target = [], []
for i in range(((len(data)-num_features-num_targets)//num_targets) + 1):
f = data[i*num_targets:i*num_targets+num_features]
t = data[i*num_targets+num_features:i*num_targets+num_features+num_targets]
features.append(list(f))
target.append(list(t))
return np.array(features), np.array(target)
# 第一步生成数据集
dataset_features, dataset_target = data_prediction_to_f_and_t(y, lengths, targets)# 调用上述定义的函数
print(dataset_features.shape)
print(dataset_target.shape)
>>>(992, 8)
(992, 1)# 与我们上面描述的相同,shape大小正确
如果觉得看不清,我们可以再尝试一下这个函数:
'''不属于任何模块,测试用'''
data = torch.arange(0, T, dtype=torch.float32)# data为0,1,2,...,999
dataset_features, dataset_target = data_prediction_to_f_and_t(data, lengths, targets)# lengths=8, targets=1
print(dataset_features)
print(dataset_target)
输出:
特征:
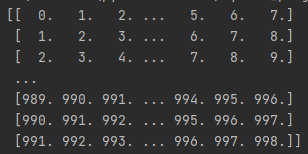
标签:
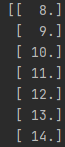
…
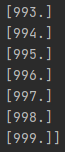
与我们上述的论述相同,如果有兴趣可以修改lengths与targets的值的大小看效果。
下面继续首先进行数据集的拆分,我们同样定义了函数,然后再调用:
'''data_preparation模块'''
def dataset_split_4sets(data_features, data_target, ratio=0.8):
'''
功能:训练集与测试集的特征与target分离
ratio:表示训练集所占的百分比
'''
split_index = int(ratio*len(data_features))
train_features = data_features[:split_index]
train_target = data_target[:split_index]
test_features = data_features[split_index:]
test_target = data_target[split_index:]
return train_features, train_target, test_features, test_target
# 第二步,将数据集进行拆分,分成训练集和测试集
trian_features, train_target, test_features, test_target = dataset_split_4sets(dataset_features, dataset_target)
接着,将数据集写成Dataset的子类,至于为什么要写成Dataset的子类,是因为后我们最终要将数据封装进Dataloader里,可以方便做mini-batch与shuffle操作,这是为了方便Pytorch框架下训练模型所使用的Dataloder类。关于这里不清楚得同学可以csdn一下。
'''data_preparation模块'''
class dataset_to_Dataset(Dataset):
'''
将传入的数据集,转成Dataset类,方面后续转入Dataloader类
注意定义时传入的data_features,data_target必须为numpy数组
'''
def __init__(self, data_features, data_target):
self.len = len(data_features)
self.features = torch.from_numpy(data_features)
self.target = torch.from_numpy(data_target)
def __getitem__(self, index):
return self.features[index], self.target[index]
def __len__(self):
return self.len
# 第三步,将刚才的数据集转换成Dataset类
train_set = dataset_to_Dataset(data_features=trian_features, data_target=train_target)
最后将上述进行整理,下面是完整的data_prediction模块:(能写成函数的尽量写成函数方法,方便调用,和复用)
'''data_preparation完整模块'''
# 用户:Ejemplarr
# 编写时间:2022/3/24 22:11
from torch.utils.data import Dataset, DataLoader
import numpy as np
import torch
import matplotlib.pyplot as plt
'''
lengths :决定了用于预测序列的长度
targets :表示待预测的序列长度
例如lengths = 8, targets = 1,则表示用8个数预测一个数
'''
lengths = 8
targets = 1
def data_start():
T = 1000
x = torch.arange(1, T + 1, dtype=torch.float32)
y = torch.sin(0.01 * x) + torch.normal(0, 0.1, (T,)) # 每个y加上一个0到0.2(左闭右开)的噪声
return x, y
def data_prediction_to_f_and_t(data, num_features, num_targets):
'''
准备数据集的函数
'''
features, target = [], []
for i in range(((len(data)-num_features-num_targets)//num_targets) + 1):
f = data[i*num_targets:i*num_targets+num_features]
t = data[i*num_targets+num_features:i*num_targets+num_features+num_targets]
features.append(list(f))
target.append(list(t))
return np.array(features), np.array(target)
class dataset_to_Dataset(Dataset):
'''
将传入的数据集,转成Dataset类,方面后续转入Dataloader类
注意定义时传入的data_features,data_target必须为numpy数组
'''
def __init__(self, data_features, data_target):
self.len = len(data_features)
self.features = torch.from_numpy(data_features)
self.target = torch.from_numpy(data_target)
def __getitem__(self, index):
return self.features[index], self.target[index]
def __len__(self):
return self.len
def dataset_split_4sets(data_features, data_target, ratio=0.8):
'''
功能:训练集与测试集的特征与target分离
ratio:表示训练集所占的百分比
'''
split_index = int(ratio*len(data_features))
train_features = data_features[:split_index]
train_target = data_target[:split_index]
test_features = data_features[split_index:]
test_target = data_target[split_index:]
return train_features, train_target, test_features, test_target
3.GRU和LSTM网络框架的编写:
'''GRU完整模块'''
# 用户:Ejemplarr
# 编写时间:2022/3/24 22:09
import torch
import torch.nn as nn
from data_preparation import targets
'''
GRU:
对于每个网络框架具体的学习最好参考官网进行学习:
https://pytorch.org/docs/master/generated/torch.nn.GRU.html#torch.nn.GRU
因为官网对于一个网络的输入和输出的数据的shape讲的特别清楚,对于我来说,看完相关基本原理之后,直接就是打开官网
仔细阅读一下整个网络的各种数据的shape,以及各种参数的实际意义,最后就是借助简单的数据集跑一个demo。这仅仅是我
个人的习惯,仅供参考。
关于GRU的原理,可以参考某站的李沐老师的动手学习深度学习系列。
'''
'''
定义Parameters,从官网上可以看见除了我们下面定义的这两个参数,其他参数都有默认值,如果实现最简单的GRU网络,自己定义一下
前面两个参数就行了,后面的例如dropout是防止过拟合的,bidirectional是控制是否实现双向的,等等,但是这边我们还需要设置
batch_first = True,因为一般我们的数据格式都是batch_size在前
'''
INPUT_SIZE = 1# The number of expected features in the input x,就是我们表示子序列中一个数的描述的特征数量,只有一个就填1,一个数字就是1
HIDDEN_SIZE = 64# The number of features in the hidden state h,隐藏状态的特征数
# h0 = torch.zeros([])# h0的shape与hn的shape一样为(D * num_layers, batch_size, hidden_size)
# 其中的D = 2 if bidirectional=True otherwise 1,num_layers为GRU的层数
# 如果这边不对h0进行定义,则网络中的forward中h0可以直接用None替代,默认全零。
# 定义我们的类
class GRU(nn.Module):
def __init__(self):
super(GRU, self).__init__()
self.gru = nn.GRU(
input_size=INPUT_SIZE,# 传入我们上面定义的参数
hidden_size=HIDDEN_SIZE,# 传入我们上面定义的参数
batch_first=True,# 为什么设置为True上面解释过了
)
self.mlp = nn.Sequential(
nn.Linear(HIDDEN_SIZE, 32), # 加入线性层的原因是,GRU的输出,参考官网为(batch_size, seq_len, hidden_size)
nn.LeakyReLU(), # 这边的多层全连接,根据自己的输出自己定义就好,
nn.Linear(32, 16), # 我们需要将其最后打成(batch_size, output_size)比如单值预测,这个output_size就是1,
nn.LeakyReLU(), # 这边我们等于targets
nn.Linear(16, targets) # 这边输出的(batch_size, targets)且这个targets是上面一个模块已经定义好了
)
def forward(self, input):
output, h_n = self.gru(input, None)# output:(batch_size, seq_len, hidden_size),h0可以直接None
# print(output.shape)
output = output[:, -1, :]# output:(batch_size, hidden_size)
output = self.mlp(output)# 进过一个多层感知机,也就是全连接层,output:(batch_size, output_size)
return output
'''LSTM完整模块'''
# 用户:Ejemplarr
# 编写时间:2022/3/24 22:09
import torch
import torch.nn as nn
from data_preparation import targets
INPUT_SIZE = 1# The number of expected features in the input x
HIDDEN_SIZE = 64# The number of features in the hidden state h
'''
GRU与LSTM的在代码上的差别,就是将nn.GRU换成nn.LSTM而已
'''
class LSTM(nn.Module):
def __init__(self):
super(LSTM, self).__init__()
self.gru = nn.LSTM(
input_size=INPUT_SIZE,# 传入我们上面定义的参数
hidden_size=HIDDEN_SIZE,# 传入我们上面定义的参数
batch_first=True,# 为什么设置为True上面解释过了
)
self.mlp = nn.Sequential(
nn.Linear(HIDDEN_SIZE, 32), # 加入线性层的原因是,GRU的输出,参考官网为(batch_size, seq_len, hidden_size)
nn.LeakyReLU(), # 这边的多层全连接,根据自己的输出自己定义就好,
nn.Linear(32, 16), # 我们需要将其最后打成(batch_size, output_size)比如单值预测,这个output_size就是1,
nn.LeakyReLU(), # 这边我们等于targets
nn.Linear(16, targets) # 这边输出的(batch_size, targets)且这个targets是上面一个模块已经定义好了
)
def forward(self, input):
output, h_n = self.gru(input, None)# output:(batch_size, seq_len, hidden_size),h0可以直接None
# print(output.shape)
output = output[:, -1, :]# output:(batch_size, hidden_size)
output = self.mlp(output)# 进过一个多层感知机,也就是全连接层,output:(batch_size, output_size)
return output
4.定义训练函数:
'''train完整模块'''
# 用户:Ejemplarr
# 编写时间:2022/3/24 22:10
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from GRU import GRU
from LSTM import LSTM
from data_preparation import data_start,data_prediction_to_f_and_t,dataset_to_Dataset,dataset_split_4sets,lengths,targets
'''
数据的导入
可调优数据的定义
网络实例化
优化器的定义
数据搬移至gpu
损失函数的定义
开始训练
'''
# 可调参数的定义
BATCH_SIZE = 16
EPOCH = 100
LEARN_RATE = 1e-3
# 数据的导入
x, y = data_start()
dataset_features, dataset_target = data_prediction_to_f_and_t(y, lengths, targets)
trian_features, train_target, test_features, test_target = dataset_split_4sets(dataset_features, dataset_target)
train_set = dataset_to_Dataset(data_features=trian_features, data_target=train_target)
train_set_iter = DataLoader(dataset=train_set,# 将数据封装进Dataloader类
batch_size=BATCH_SIZE,
shuffle=True, # 打乱batch与batch之间的顺序
drop_last=True)# drop_last = True表示最后不够一个batch就舍弃那些多余的数据
# gpu的定义
device = ('cuda'if torch.cuda.is_available else 'cpu')
# 网络的实例化
net_gru = GRU().to(device)
net_lstm = LSTM().to(device)
# 优化器的定义
optim_gru = optim.Adam(params=net_gru.parameters(), lr=LEARN_RATE)
optim_lstm = optim.Adam(params=net_lstm.parameters(),lr=LEARN_RATE)
# 损失函数的定义
loss_fuc = nn.MSELoss()
# 训练函数的定义
def train_for_gru(data, device, loss_fuc, net, optim, Epoch):
for epoch in range(Epoch):
loss_print = []
for batch_idx, (x, y) in enumerate(data):
x = x.reshape([BATCH_SIZE, lengths, 1])
x = x.to(device)
# print(y.shape)
y = y.reshape((len(y),targets))
y = y.to(device)
# print(y.shape)
y_pred = net(x)
loss = loss_fuc(y, y_pred)
loss_print.append(loss.item())
# 三大步
# 梯度值更为0
optim.zero_grad()
# loss反向传播
loss.backward()
# 优化器更新
optim.step()
print('GRU:loss:',sum(loss_print)/len(data))
def train_for_lstm(data, device, loss_fuc, net, optim, Epoch):
for epoch in range(Epoch):
loss_print = []
for batch_idx, (x, y) in enumerate(data):
x = x.reshape([BATCH_SIZE, lengths, 1])
x = x.to(device)
# print(y.shape)
y = y.reshape((len(y),targets))
y = y.to(device)
# print(y.shape)
y_pred = net(x)
loss = loss_fuc(y, y_pred)
loss_print.append(loss.item())
# 三大步
# 网络的梯度值更为0
optim.zero_grad()
# loss反向传播
loss.backward()
# 优化器更新
optim.step()
print('LSTM:loss:',sum(loss_print)/len(data))
def main():
start = time.perf_counter()
train_for_gru(train_set_iter, device, loss_fuc, net_gru, optim_gru, EPOCH)
train_for_lstm(train_set_iter, device, loss_fuc, net_lstm, optim_lstm, EPOCH)
end = time.perf_counter()
print('训练时间为:{:.2f}s'.format(end-start))
#保存模型
torch.save(net_gru.state_dict(), 'gru.pt')
torch.save(net_lstm.state_dict(), 'lstm.pt')
if __name__ == '__main__':
main()
5.定义测试函数:
'''test完整模块'''
# 用户:Ejemplarr
# 编写时间:2022/3/24 22:10
from train import device
from data_preparation import lengths, targets
from train import x, y, dataset_features # 为了保持原始数据相同
from GRU import GRU
from LSTM import LSTM
import torch
import matplotlib.pyplot as plt
# 导入保存好的网络
net_gru = GRU().to(device)
net_gru.load_state_dict(torch.load('gru.pt'))
net_lstm = LSTM().to(device)
net_lstm.load_state_dict(torch.load('lstm.pt'))
# 定义测试函数
def test_for_gru(dataset_features):
dataset_features = dataset_features.reshape([len(dataset_features), lengths, 1])
y_pred = net_gru(torch.from_numpy(dataset_features).to(device))
y_pred = y_pred_to_numpy(y_pred)
y_pred = y_pred.reshape(y_pred.size,1)
plt.plot(x, y)
plt.plot(x[lengths:y_pred.size+lengths], y_pred)
plt.legend(('data', 'data_pred:{}'.format(targets)), loc='upper right')
plt.title('GRU')
plt.show()
def test_for_lstm(dataset_features):
dataset_features = dataset_features.reshape([len(dataset_features), lengths, 1])
y_pred = net_lstm(torch.from_numpy(dataset_features).to(device))
y_pred = y_pred_to_numpy(y_pred)
y_pred = y_pred.reshape(y_pred.size,1)
plt.plot(x, y)
plt.plot(x[lengths:y_pred.size+lengths], y_pred)
plt.legend(('data', 'data_pred:{}'.format(targets)), loc='upper right')
plt.title('LSTM')
plt.show()
def y_pred_to_numpy(y_pred):
'''
:param y_pred: 网络的输出
:return: 一个numpy数组
'''
y_pred = y_pred.detach().cpu().numpy()
return y_pred
if __name__ == '__main__':
test_for_gru(dataset_features)
test_for_lstm(dataset_features)
6.总结:
使用方法,分别创建五个py文件,将上述五个完整模块分别复制到各个py文件,运行顺序为data_preparation.py----->GRU.py----->LSTM.py----->train.py----->test.py
想要获取完整的代码点击这里:源代码
使用了GRU,LSTM对创建的数据集进行了预测,结果效果不错。
感谢阅读,欢迎交流!!!
















 122
122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









