






文章目录
使用之前先安装requests网络库,如果使用的是Anaconda3则可以在anaconda Prompt中输入
pip3 install requests
如果使用的是PyCharm,则创建项目后点击File👉Settings👉interpreter,然后搜索requests安装即可
基本使用方法
1.GET请求以及输出相关信息
下面使用gett方法访问淘宝首页(https;//www.taobao.com),并获取get方法返回值类型、状态码、响应体、Cookie等信息。
import requests
#访问淘宝首页
res=requests.get("https://taobao.com")
#输出get方法返回值类型
print(type(res))
#输出状态码
print(res.status_code)
#输出响应体类型
print(type(res.text))
#输出Cookie
print(res.cookies)
#输出响应体
print(res.text)
运行结果
<class ‘requests.models.Response’>
200
<class ‘str’>
<RequestsCookieJar[]>

可以知道,get方法返回的是requests.models.Response类型的对象,状态码为200表示响应正常。requests除了get方法还有以下常见的6种方法。
| 方法 | 街上说明 |
|---|---|
| requests.request() | 构造一个请求,支撑一下各方法的基础方法 |
| requests.head() | 获取HTML网页头的信息方法,对应HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求方法,对应HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应HTTP的RUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML页面提交删除请求,对应HTTP的DELETE |
2.添加HTTP请求头
有很多网站,在访问其Web资源时必须要设置一些HTTP请求头,比如User-agent、Host等,否则无法访问其资源,这是可以利用get方法中的headers参数,该参数是一个字典类型的值,即含有 ‘键’:‘值’,如果要设置中文的Cookie则需要quote和unquote函数进行编码和解码。下面使用get方法访问https://www.httpbin.org/get,并设置User-agent和一个自定义请求头name,并且该值为中文。
import requests
from urllib.parse import quote,unquote
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
'name':quote('丑八怪')}
#发送请求
res=requests.get("https://www.httpbin.org/get",headers=headers)
#输出响应体
print(res.text)
#输出请求头name的值
print('Name:',unquote(res.json()['headers']['Name']))
运行结果
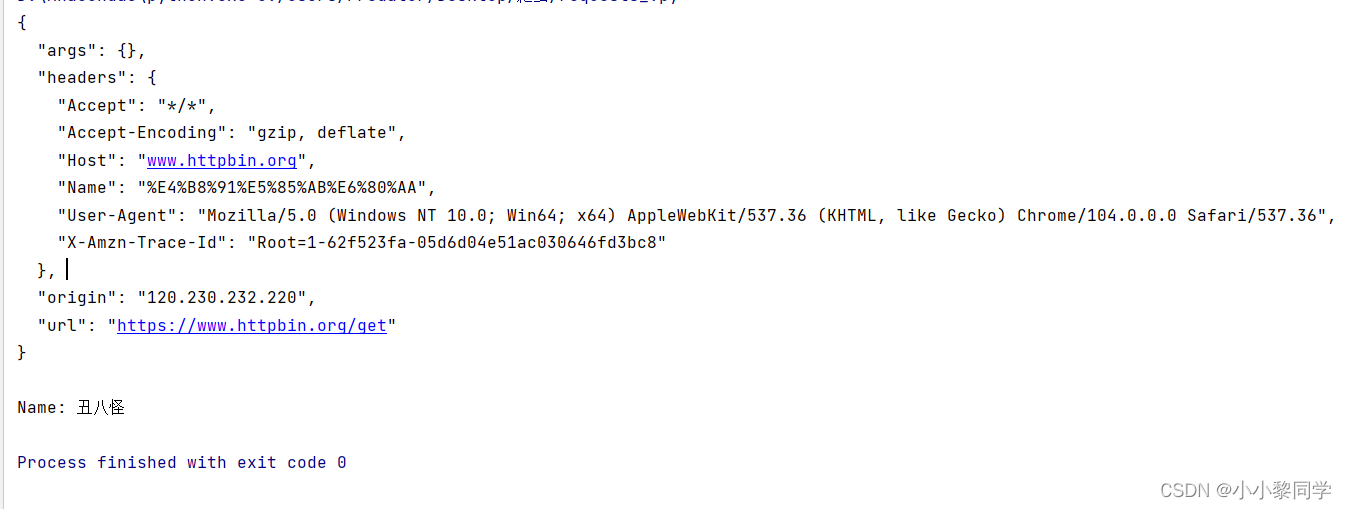
自定义的一个请求头中的quote函数把’丑八怪‘编码成%XX格式,然后利用unquote解码。
3.抓取二进制数据
get方法指定的URL不仅可以是网页还可以是任何二进制文件,比如png图像、pdf文档等。
import requests
#发送请求
res=requests.get("https://ssr1.scrape.center/static/img/logo.png")
#输出响应体,不过是乱码
print(res.text)
#输出bytes形式数据
print(res.content)
运行结果部分截图
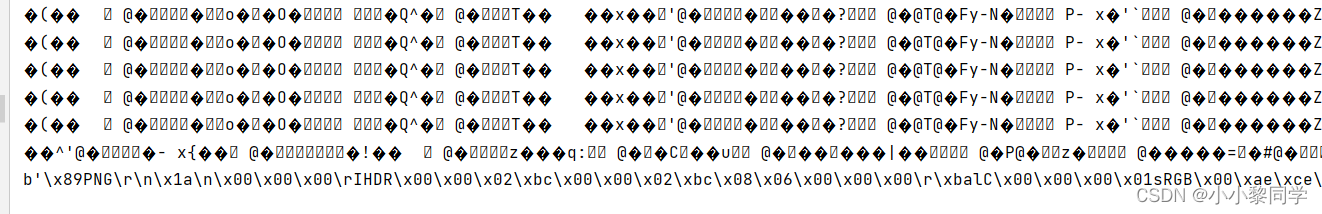
可以看到res的text属性出现了乱码,content属性获得bytes形式的数据,运行结果的b表示bytes。
- 保存到本地文件
with open('logo.png','wb') as f:
f.write(res.content)
4.POST请求
发送post请求时必须指定data参数,该值的格式为字典类型。
import requests
data={
'name':'Bill',
'coutry':'中国',
'age':20
}
#向服务器发送post请求,发送的数据必须放在字典中,通过data参数进行传递
res=requests.post("https://httpbin.org/post",data=data)
#输出响应体,不过是乱码
print(res.text)
#处理成json格式
print(res.json())
运行结果部分截图

5.响应数据
发送请求后得到一个Response对象,可以使用对象的相关属性和方法获取更多的响应信息,如状态码、响应头、Cookie以及判定状态码。
import requests
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'}
#向简书发送请求
res=requests.post("https://www.jianshu.com",headers=headers)
#输出状态码
print(type(res.status_code),res.status_code)
#输出响应头
print(type(res.headers),res.headers)
#输出cookie
print(type(res.cookies),res.cookies)
#输出请求的url
print(type(res.url),res.url)
#输出请求历史
print(type(res.history),res.history)
运行结果截图

resquests提供了一个code对象,可以直接查询状态码对应的一个标识
if not res.status_code==requests.codes.ok:
print("failed")
else:
print("ok")
常见的高级用法
1.处理Cookie
在访问一些网站通常需要登陆才能正常显示其内容,一般的做法是先在网页登录,然后拿到Cookie复制在程序上,把Cookie在发送给服务端就相当于已登录。cookies属性可以得都服务端发过来的Cookie,有两种方法可以设置Cookie。
- headers参数
- cookies参数
get方法和post方法都有这两个参数,如果使用cookies参数则需创建RequestsCookieJar对象,并用set方法设置每一个Cookie。接下来通过以上两种参数向简书服务端发送Cookie
headers参数
import requests
#获取简书首页内容,定义了Host、User-Agent和Cookie请求字段
headers={'Host': 'www.jianshu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
'cookies':'acw_tc=0bcd4c4e16604479636496068e015c33e6dce6bdc3c96aa8ffeafaf9f4f3a0;path=/;HttpOnly;Max-Age=1800'}
res=requests.get("https://www.jianshu.com",headers=headers)
#输出状态码
print(res.text)
cookies参数
import requests
#获取简书首页内容,定义了Host、User-Agent
headers={'Host': 'www.jianshu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
}
cookies='acw_tc=0bcd4c4e16604479636496068e015c33e6dce6bdc3c96aa8ffeafaf9f4f3a0;Max-Age=1800'
jar=requests.cookies.RequestsCookieJar()
#向简书发送请求,通过cookies参数传递Cookie给服务端
for cookie in cookies.split(";"):
key,value=cookie.split('=',1)
jar.set(key,value)
res=requests.get("https://www.jianshu.com",cookies=jar,headers=headers)
#输出状态码
print(res.text)
2.使用同一个会话(Session)
通过Session对象可以对客户端和用户端进行联系,每次发送请求,会传递一个ID,通过ID就能找到对应的Session对象。通俗的理解Session即“会话”,两个人在聊天时通常知道之前聊了什么。接下来通过set方法创建一个名为name的Cookie,其值为li,从结果知道不在同一个会话中第二次发送请求时无法得到第一次发送的Cookie。
import requests
requests.get('http://httpbin.org/cookies/set/name/li')
res1=requests.get('http://httpbin.org/cookies')
print(res1.text)
运行结果截图

接下来使用Session对象重复上面过程,可以发现使用Session对象第2次请求可以获得第1次请求的Cookie。
import requests
session=requests.session()
session.get('http://httpbin.org/cookies/set/name/li')
res1=session.get('http://httpbin.org/cookies')
print(res1.text)
运行结果截图

3.使用代理
如果需要爬取很多数据这时可以考虑使用代理,他的原理就是使用第三方机器发送请求,对于服务器而言就是不同的客户端发送,在requests中只需指定proxies参数即可,该参数为字典类型,需要注意的是使用http还是https协议。
import requests
proxie={
'https':'https://218.31.7.68:3761'#代理来自站大爷网站
}
res1=requests.get('https://www.baidu.com',proxies=proxie)
print(res1.text)















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











