







声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类算法的家人,可关注我的VX公众号:python算法小当家,不定期会有很多免费代码分享~
目录
02 注意力机制一:ECA(Efficient Channel Attention)
03 注意力机制二:SE(Squeeze-and-Excitation)
04 注意力机制三:CBAM(Convolutional Block Attention)
05 注意力机制四:HW(Height and Width Attention)
小伙伴们好,今天小当家带来如何添加四种注意力机制到CNN-LSTM中的教程,干货满满!有需要可免费获取!注意力机制是一种让模型在处理数据时能够“关注”到更重要信息的技术,它可以显著提升模型对数据的理解和处理能力。在深度学习模型中,特别是在处理序列数据(如文本、时间序列)或图像数据时,注意力机制发挥着重要作用。话不多说,下面开始我的分享!!!
01 基础模型:CNN-LSTM
CNN-LSTM是一种结合了卷积神经网络(CNN)和长短时记忆网络(LSTM)的混合神经网络架构。这种模型充分利用了CNN在图像和序列数据中提取局部特征的能力,以及LSTM在处理时间序列数据时管理信息的长短期记忆能力。下面是使用PyTorch框架实现的基础CNN-LSTM模型的代码:
class CNNLSTMModel(nn.Module):def __init__(self, window=5, dim=4, lstm_units=16, num_layers=2):super(CNNLSTMModel, self).__init__()self.conv1d = nn.Conv1d(dim, lstm_units, 1)self.act1 = nn.Sigmoid()self.maxPool = nn.MaxPool1d(kernel_size=window)self.drop = nn.Dropout(p=0.01)self.lstm = nn.LSTM(lstm_units, lstm_units, batch_first=True, num_layers=1, bidirectional=True)self.act2 = nn.Tanh()self.cls = nn.Linear(lstm_units * 2, 1)self.act4 = nn.Tanh()def forward(self, x):x = x.transpose(-1, -2) # tf和torch纬度有点不一样x = self.conv1d(x) # in:bs, dim, window out: bs, lstm_units, windowx = self.act1(x)x = self.maxPool(x) # bs, lstm_units, 1x = self.drop(x)x = x.transpose(-1, -2) # bs, 1, lstm_unitsx, (_, _) = self.lstm(x) # bs, 1, 2*lstm_unitsx = self.act2(x)x = x.squeeze(dim=1) # bs, 2*lstm_unitsx = self.cls(x)x = self.act4(x)return x
-
Conv1d 是一维卷积层,用于提取时间序列或者序列化数据的特征。
-
Sigmoid 和 Tanh 是激活函数,用来引入非线性,帮助模型捕捉复杂的特征。
-
MaxPool1d 是池化层,用于降低特征维度,减少计算量和模型复杂度。
-
Dropout 是一种正则化方法,用于减少过拟合。
-
LSTM 层处理序列数据,可以捕捉长期依赖关系。
-
Linear 是全连接层,用于将LSTM层的输出映射到预期的输出大小。
02 注意力机制一:ECA(Efficient Channel Attention)
ECA(Efficient Channel Attention)是一种高效的通道注意力机制,旨在增强网络的特征表示能力,同时避免复杂的计算。ECA的核心思想是通过学习不同通道的重要性来调整通道的响应强度,从而聚焦于更有信息量的特征。在CNN-LSTM模型中引入ECA可以增强模型对特征的表达能力。这里是如何在PyTorch中实现ECA并集成到基本的CNN-LSTM模型中的代码:
class CNNLSTMModel_ECA(nn.Module):def __init__(self, window=5, dim=4, lstm_units=16, num_layers=2):super(CNNLSTMModel_ECA, self).__init__()self.conv1d = nn.Conv1d(dim, lstm_units, 1)self.act1 = nn.Sigmoid()self.maxPool = nn.MaxPool1d(kernel_size=window)self.drop = nn.Dropout(p=0.01)self.lstm = nn.LSTM(lstm_units, lstm_units, batch_first=True, num_layers=1, bidirectional=True)self.act2 = nn.Tanh()self.attn = nn.Linear(lstm_units * 2, lstm_units * 2)self.act3 = nn.Sigmoid()self.cls = nn.Linear(lstm_units * 2, 1)self.act4 = nn.Tanh()def forward(self, x):x = x.transpose(-1, -2) # tf和torch纬度有点不一样x = self.conv1d(x) # in:bs, dim, window out: bs, lstm_units, windowx = self.act1(x)x = self.maxPool(x) # bs, lstm_units, 1x = self.drop(x)x = x.transpose(-1, -2) # bs, 1, lstm_unitsx, (_, _) = self.lstm(x) # bs, 1, 2*lstm_unitsx = self.act2(x)x = x.squeeze(dim=1) # bs, 2*lstm_unitsattn = self.attn(x) # bs, 2*lstm_unitsattn = self.act3(attn)x = x * attnx = self.cls(x)x = self.act4(x)return x
-
self.conv1d: 一维卷积层,用于提取输入特征。
-
self.act1: Sigmoid激活函数,用于引入非线性。
-
self.maxPool: 最大池化层,降低特征的维度,减少后续计算量。
-
self.drop: Dropout层,随机丢弃一部分特征,防止过拟合。
-
self.lstm: 双向LSTM层,能够捕捉序列数据中的长期依赖关系。
-
self.cls: 全连接层,用于将LSTM层的输出映射到预期输出大小。
-
self.act4: 另一个 Tanh 激活函数,用于输出层。
-
self.eca: ECA层,定义如上,用于动态调整各通道的重要性。
03 注意力机制二:SE(Squeeze-and-Excitation)
Squeeze-and-Excitation (SE) 注意力机制是一种通过重新校准网络内部特征通道的重要性来提升网络性能的技术。这种机制通过显式地建模特征通道之间的依赖关系,增强了模型的表征能力。主要关键点在于:
-
Squeeze:全局信息嵌入。SE块首先通过对特征图的空间维度进行全局平均池化来压缩每个通道,从而得到每个通道的全局空间信息。
-
Excitation:通过全连接层学习通道间的非线性依赖关系,然后通过sigmoid激活函数得到每个通道的权重。
class CNNLSTMModel_SE(nn.Module):def __init__(self, window=5, dim=4, lstm_units=16, num_layers=2):super(CNNLSTMModel_SE, self).__init__()self.conv1d = nn.Conv1d(dim, lstm_units, 1)self.act1 = nn.Sigmoid()self.maxPool = nn.MaxPool1d(kernel_size=window)self.drop = nn.Dropout(p=0.01)self.lstm = nn.LSTM(lstm_units, lstm_units, batch_first=True, num_layers=1, bidirectional=True)self.act2 = nn.Tanh()self.cls = nn.Linear(lstm_units * 2, 1)self.act4 = nn.Tanh()self.se_fc = nn.Linear(window, window)def forward(self, x):x = x.transpose(-1, -2) # tf和torch纬度有点不一样x = self.conv1d(x) # in:bs, dim, window out: bs, lstm_units, windowx = self.act1(x)# seavg = x.mean(dim=1) # bs, windowse_attn = self.se_fc(avg).softmax(dim=-1) # bs, windowx = torch.einsum("bnd,bd->bnd", x, se_attn)x = self.maxPool(x) # bs, lstm_units, 1x = self.drop(x)x = x.transpose(-1, -2) # bs, 1, lstm_unitsx, (_, _) = self.lstm(x) # bs, 1, 2*lstm_unitsx = self.act2(x)x = x.squeeze(dim=1) # bs, 2*lstm_unitsx = self.cls(x)x = self.act4(x)return x
在这个模型中,SE块通过一个全局平均池化(Squeeze步骤)和一个全连接层(Excitation步骤)来实现。这个过程首先通过平均池化来聚合整个特征图的空间信息,然后使用一个全连接层来学习每个通道的重要性权重。通过这种方式,模型能够自适应地强调或抑制某些通道的特征,从而提升整体的表征聚焦能力。
04 注意力机制三:CBAM(Convolutional Block Attention)
CBAM(Convolutional Block Attention Module)是一种结构复杂、功能强大的注意力机制,专为卷积神经网络设计。它通过顺序集成空间注意力(spatial attention)和通道注意力(channel attention)两个子模块来增强模型的特征表示能力。
通道注意力(Channel Attention):
-
通道注意力关注“哪些”通道是重要的,它通过全局平均池化和全局最大池化操作获取全局信息,然后通过共享网络权重的全连接层来学习不同通道的重要性权重。
空间注意力(Spatial Attention):
-
空间注意力关注“哪些”空间位置是重要的,这通常是在通道注意力之后实施。它通过先对特征图的通道进行压缩,然后使用一个小的卷积层来学习不同空间位置的重要性。
CBAM的两个子模块依次作用,使网络能够在处理输入特征时更加关注信息丰富的区域,从而提升了特征的表达能力和最终的预测性能。
class CNNLSTMModel_CBAM(nn.Module):def __init__(self, window=5, dim=4, lstm_units=16, num_layers=2):super(CNNLSTMModel_CBAM, self).__init__()self.conv1d = nn.Conv1d(dim, lstm_units, 1)self.act1 = nn.Sigmoid()self.maxPool = nn.MaxPool1d(kernel_size=window)self.drop = nn.Dropout(p=0.01)self.lstm = nn.LSTM(lstm_units, lstm_units, batch_first=True, num_layers=1, bidirectional=True)self.act2 = nn.Tanh()self.cls = nn.Linear(lstm_units * 2, 1)self.act4 = nn.Tanh()self.se_fc = nn.Linear(window, window)self.hw_fc = nn.Linear(lstm_units, lstm_units)def forward(self, x):x = x.transpose(-1, -2) # tf和torch纬度有点不一样x = self.conv1d(x) # in:bs, dim, window out: bs, lstm_units, windowx = self.act1(x)# chanalavg = x.mean(dim=1) # bs, windowse_attn = self.se_fc(avg).softmax(dim=-1) # bs, windowx = torch.einsum("bnd,bd->bnd", x, se_attn)# whavg = x.mean(dim=2) # bs, lstm_unitshw_attn = self.hw_fc(avg).softmax(dim=-1) # bs, lstm_unitsx = torch.einsum("bnd,bn->bnd", x, hw_attn)x = self.maxPool(x) # bs, lstm_units, 1x = self.drop(x)x = x.transpose(-1, -2) # bs, 1, lstm_unitsx, (_, _) = self.lstm(x) # bs, 1, 2*lstm_unitsx = self.act2(x)x = x.squeeze(dim=1) # bs, 2*lstm_unitsx = self.cls(x)x = self.act4(x)return x
在这个模型中,ChannelAttention 和 SpatialAttention 类被用来实现通道和空间注意力机制。通过在卷积层后应用这些注意力模块,模型能够更加有效地识别并关注输入数据中最关键的特征,进而通过LSTM处理这些特征来捕捉时间依赖性,最终通过全连接层输出预测结果。
05 注意力机制四:HW(Height and Width Attention)
HW(Height and Width Attention)是一种专注于处理二维数据(如图像)的注意力机制,其独特之处在于同时关注数据的高度(height)和宽度(width)方向的特征。这种机制通常用于强调或抑制图像或特征图中的某些区域,从而提高模型对关键视觉信息的敏感度。HW注意力机制的独特之处:
-
双维度关注:大多数注意力机制如SE(Squeeze-and-Excitation)关注于通道层面,而HW注意力机制同时在高度和宽度两个维度上操作,使其在处理图像、视频等二维数据时更为有效。
-
灵活性高:HW机制可以根据具体的应用场景独立或联合使用高度和宽度的注意力,提供更多的自定义选项。
-
增强局部特征识别:通过对特定的行和列加权,HW注意力可以帮助模型更好地识别和处理局部特征,这在诸如场景理解和物体识别等任务中尤为重要。
class CNNLSTMModel_HW(nn.Module):def __init__(self, window=5, dim=4, lstm_units=16, num_layers=2):super(CNNLSTMModel_HW, self).__init__()self.conv1d = nn.Conv1d(dim, lstm_units, 1)self.act1 = nn.Sigmoid()self.maxPool = nn.MaxPool1d(kernel_size=window)self.drop = nn.Dropout(p=0.01)self.lstm = nn.LSTM(lstm_units, lstm_units, batch_first=True, num_layers=1, bidirectional=True)self.act2 = nn.Tanh()self.cls = nn.Linear(lstm_units * 2, 1)self.act4 = nn.Tanh()self.hw_fc = nn.Linear(lstm_units, lstm_units)def forward(self, x):x = x.transpose(-1, -2) # tf和torch纬度有点不一样x = self.conv1d(x) # in:bs, dim, window out: bs, lstm_units, windowx = self.act1(x)# whavg = x.mean(dim=2) # bs, lstm_unitshw_attn = self.hw_fc(avg).softmax(dim=-1) # bs, lstm_unitsx = torch.einsum("bnd,bn->bnd", x, hw_attn)x = self.maxPool(x) # bs, lstm_units, 1x = self.drop(x)x = x.transpose(-1, -2) # bs, 1, lstm_unitsx, (_, _) = self.lstm(x) # bs, 1, 2*lstm_unitsx = self.act2(x)x = x.squeeze(dim=1) # bs, 2*lstm_unitsx = self.cls(x)x = self.act4(x)return x
通过集成HW注意力机制,CNN-LSTM模型能够在处理具有空间特征的数据时,更加有效地捕捉和利用重要信息,进而提升模型的整体性能和准确度。
06 实验展示
-
实验所用示例数据及相关设置如下(目标列是close):
-
窗口化:设定一个窗口大小window,定义用于生成样本的时间序列长度。
-
构造序列数据:从归一化后的数据中构造长度为window+1的时间序列样本。这使得每个样本都包含了连续的window天数据以及预测目标值。
-
数据划分:默认情况下,将90%的数据作为训练集,剩余的10%作为测试集。通过is_test参数控制返回的是训练集还是测试集。
-
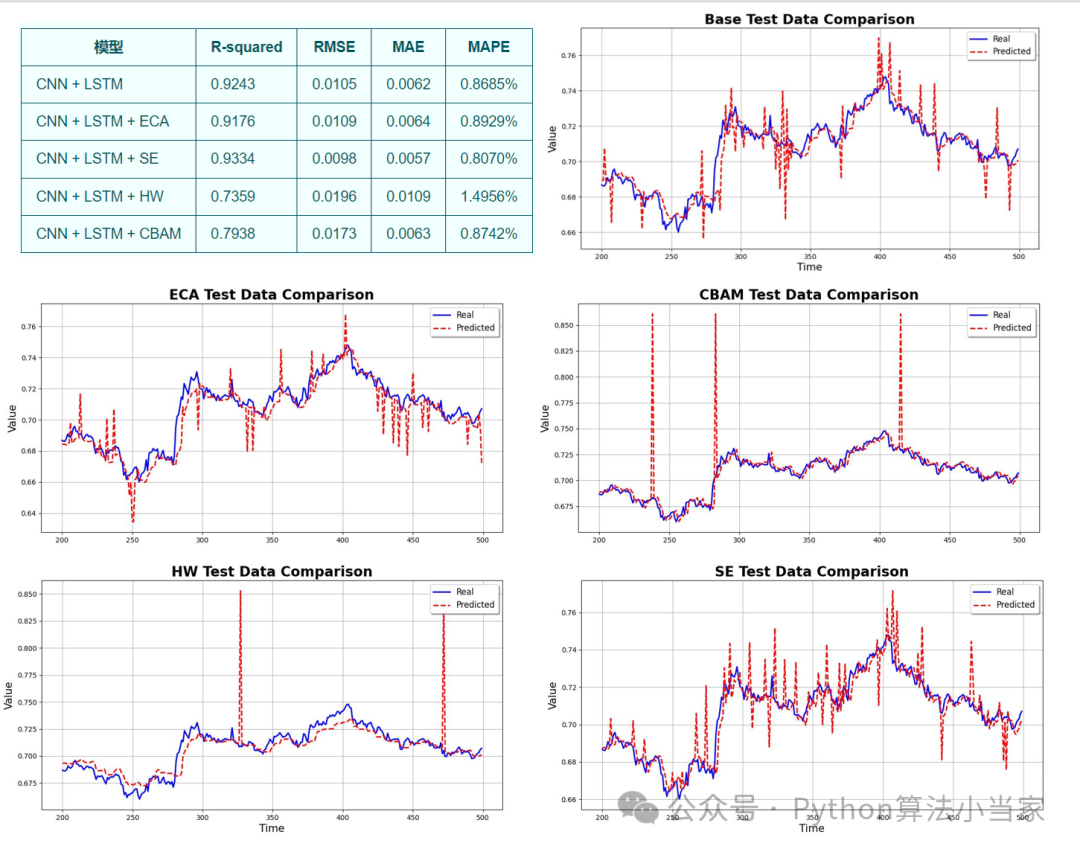
各模型评价指标及可视化如下:
07 代码获取
关注VX公众号python算法小当家,后台回复关键字attention,即可免费获得代码
attention
可后台回复需求定制模型,看到秒回

















 3901
3901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









