







目录
K-Means聚类的步骤
k-means步骤:
随机设置K个空间内的点作为初始的聚类中心;
对于其他每个点分别计算到K个中心的距离,每个点选择最近的一个聚类中心点作为同一类;
每个点都聚类完毕后,重新计算出每个聚类的新中心点(计算平均值);
如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步
计算题流程:
第1次聚类:
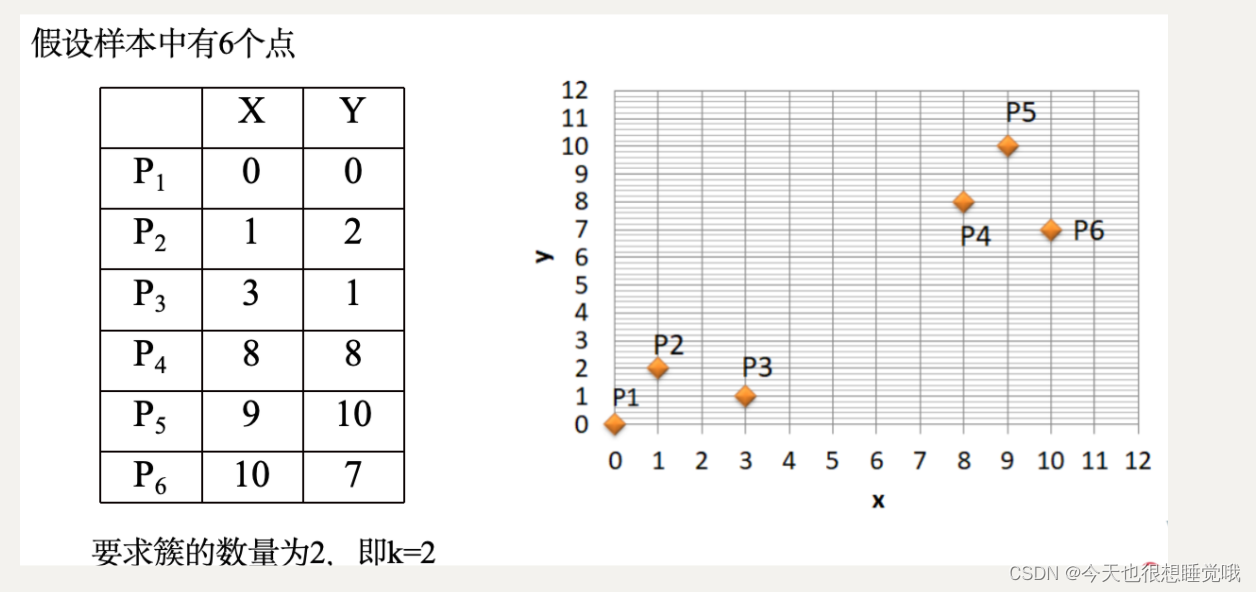
(1)随机选择两个初始聚类中心,假设选P1和P2
(2)计算其它几个点到初始聚类中心的距离;
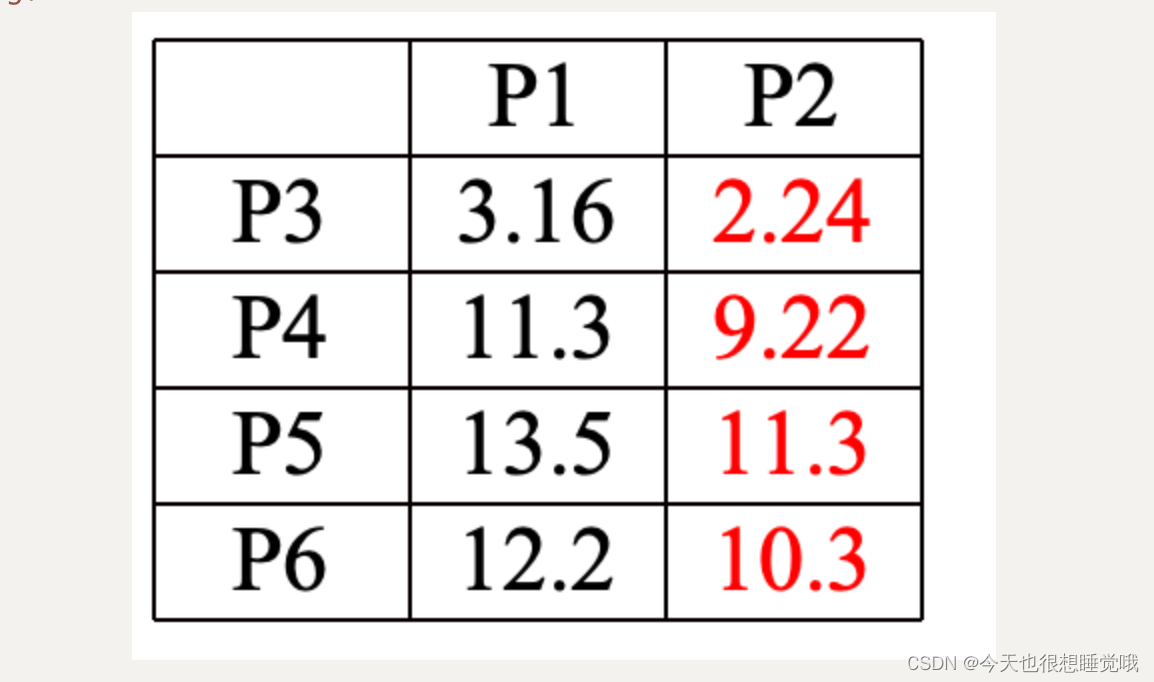
第一次聚类结果:簇A:P1 簇B:P2、P3、P4、P5、P6
第二次聚类:
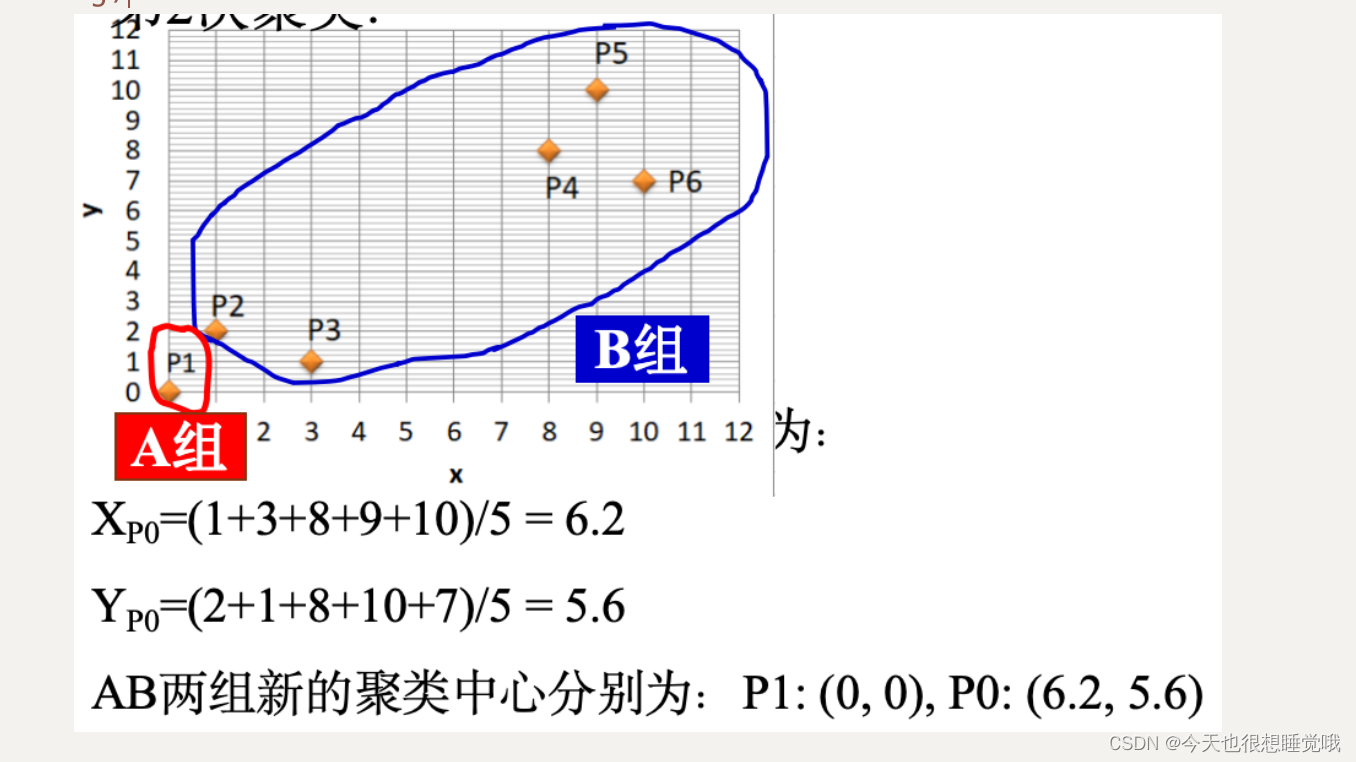
首先计算每一簇聚类后的聚类中心;发现与原中心不一致,重新聚类。
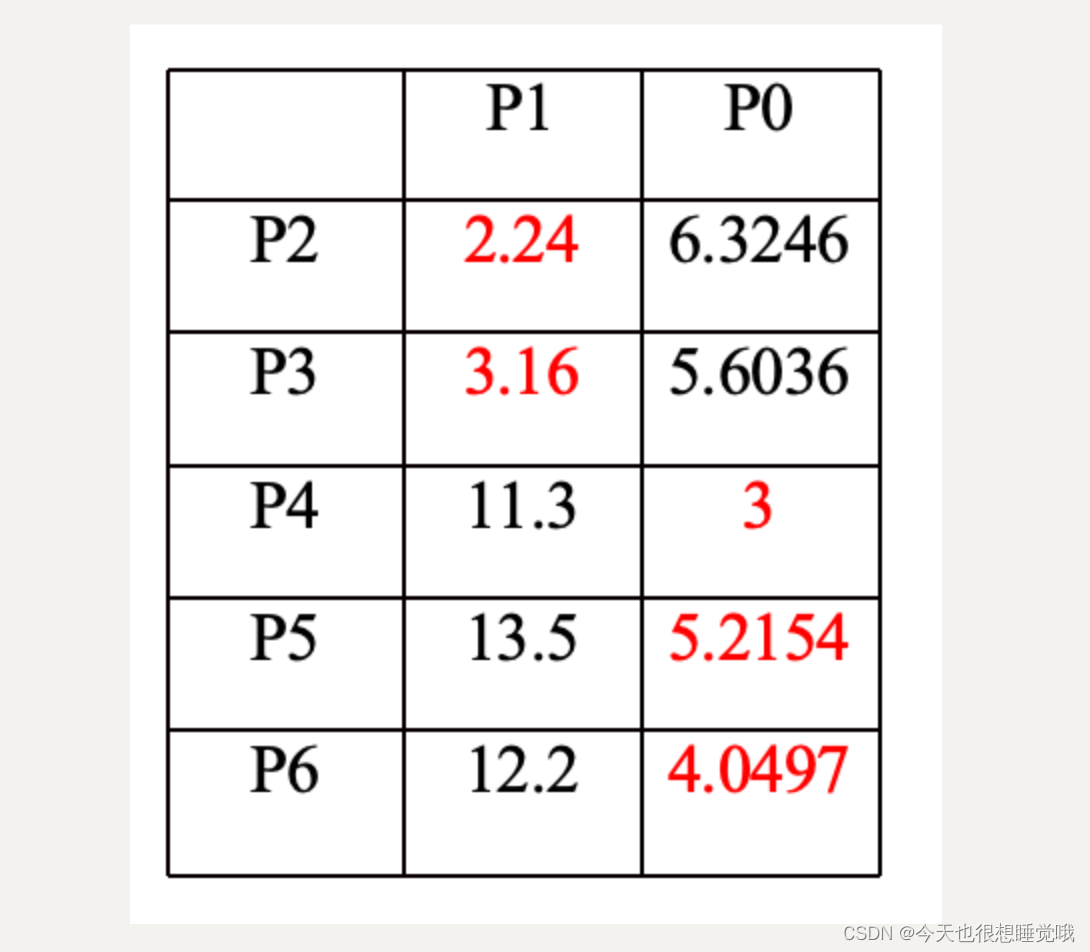
第二次聚类结果:簇A:P1、P2、P3 簇B:P4、P5、P6
计算聚类中心坐标:XPA=(0+1+3)/3 = 1.33 XPB=(8+9+10)/3 = 9
YPA=(0+2+1)/3 = 1 YPB=(8+10+7)/3 = 8.33
AB两组新的聚类中心分别为:PA: (1.33, 1), PB: (9, 8.33)
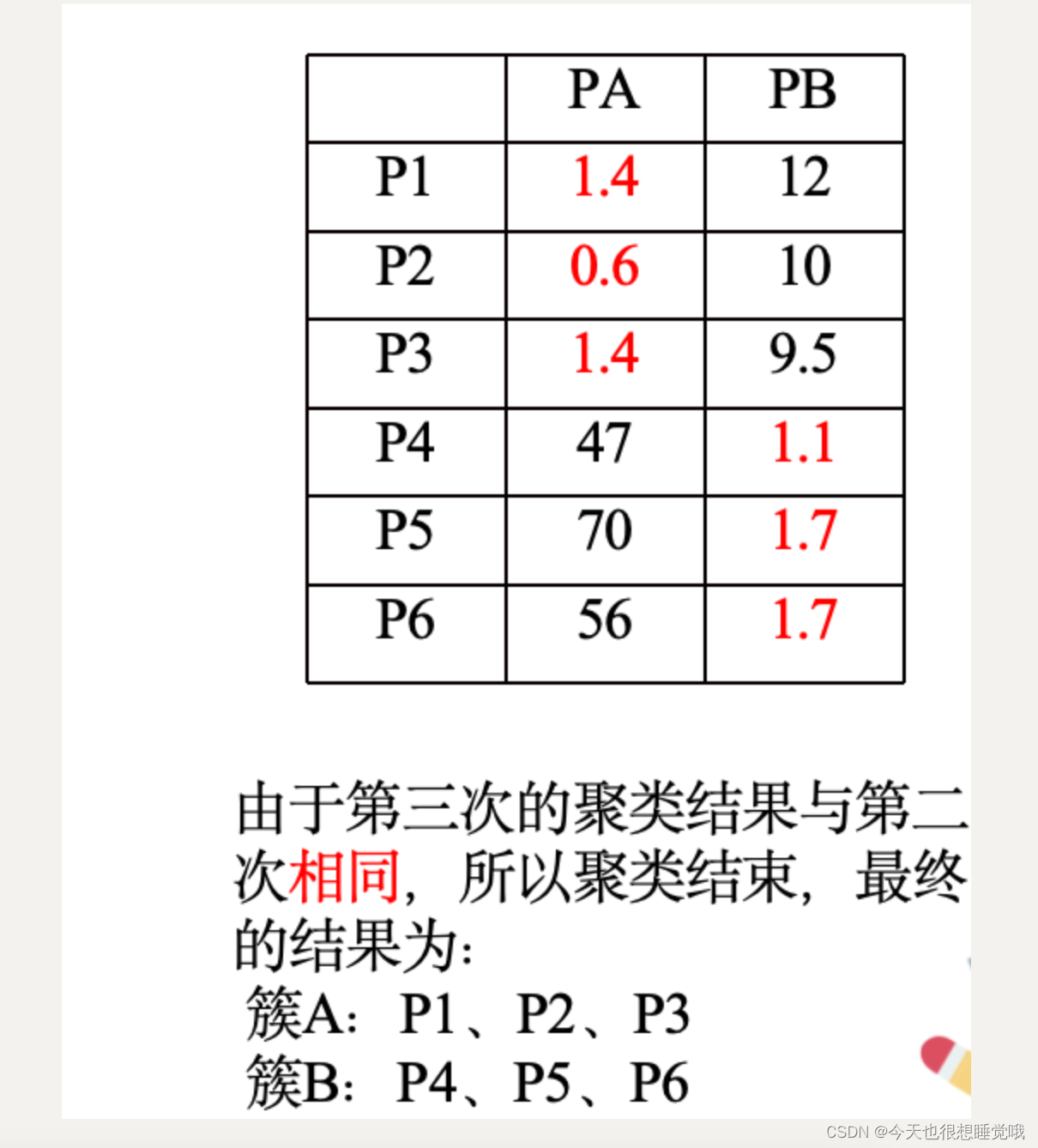
例题:

K-means性能评估指标:轮廓系数
计算公式:
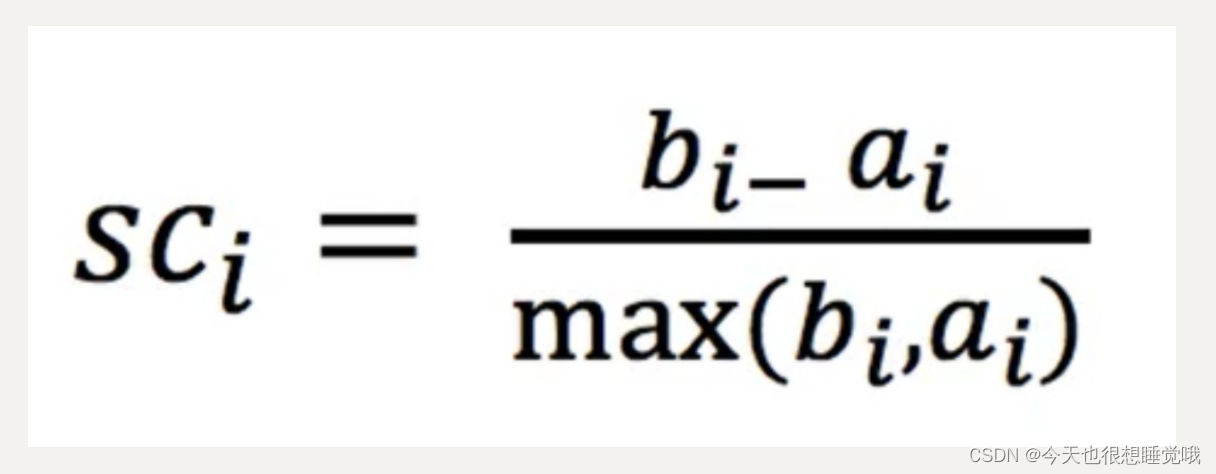
bi为i到其他簇的所有样本的最小平均值;ai为i到本身簇的距离平均值。
越接近1越好,越接近-1越不好
轮廓系数手算流程:假设:簇A:P1、P2、P3 簇B:P4、P5、P6
1)分别计算p1与p2和p3的距离,并计算平均值: a(p1)=(2.24+3.16)/2=2.7
(2)分别计算p1与p4、p5、p6之间的距离,并计算平均值: b(p1)=(11.31+13.45+12.20)/3=12.32
(3)计算p1的轮廓系数: s(p1)=(12.32-2.7)/12.32=0.78
(4)同理,计算p2,p3的轮廓系数分别为: s(p2)=(10.28-2.24)/10.28=0.78 s(p3)=(9.55-2.7)/9.55=0.71
(5)计算簇A中的轮廓系数的平均值: s=(0.78+0.78+0.71)/3=0.76















 3281
3281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









