






T5全称是Text-to-Text Transfer Transformer,是一种模型架构或者说是一种解决NLP任务的一种范式。
把所有任务,如分类、相似度计算、文本生成都用一个Text-to-text(文本到文本)的框架里进行解决。
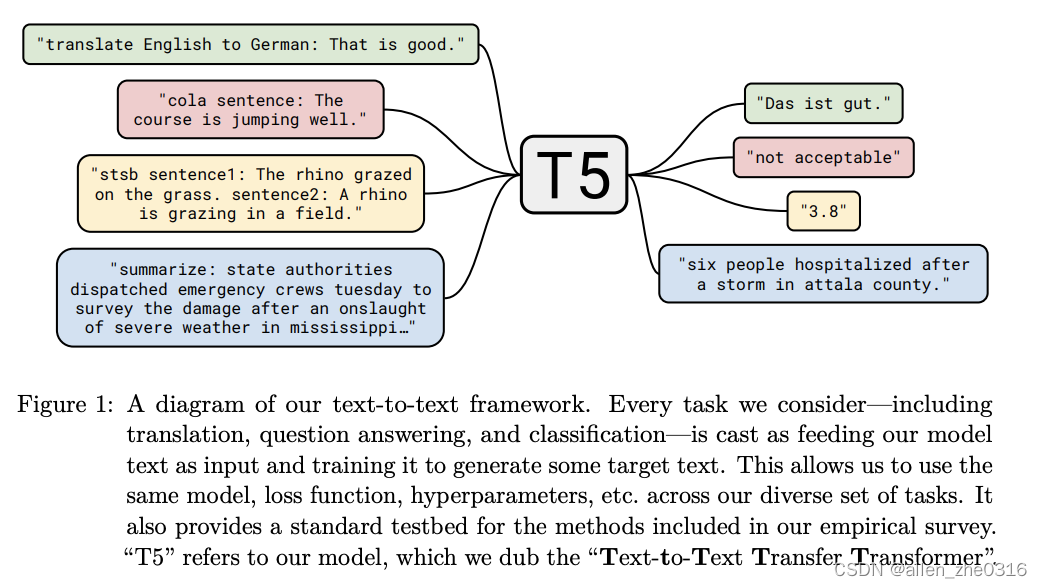
模型结构
先说模型结构:encoder-decoder架构,编码层和解码层都是12层,一共有220M个参数,大概是bert-base 的两倍
与之对应的是其他两种,共三种模型结构。
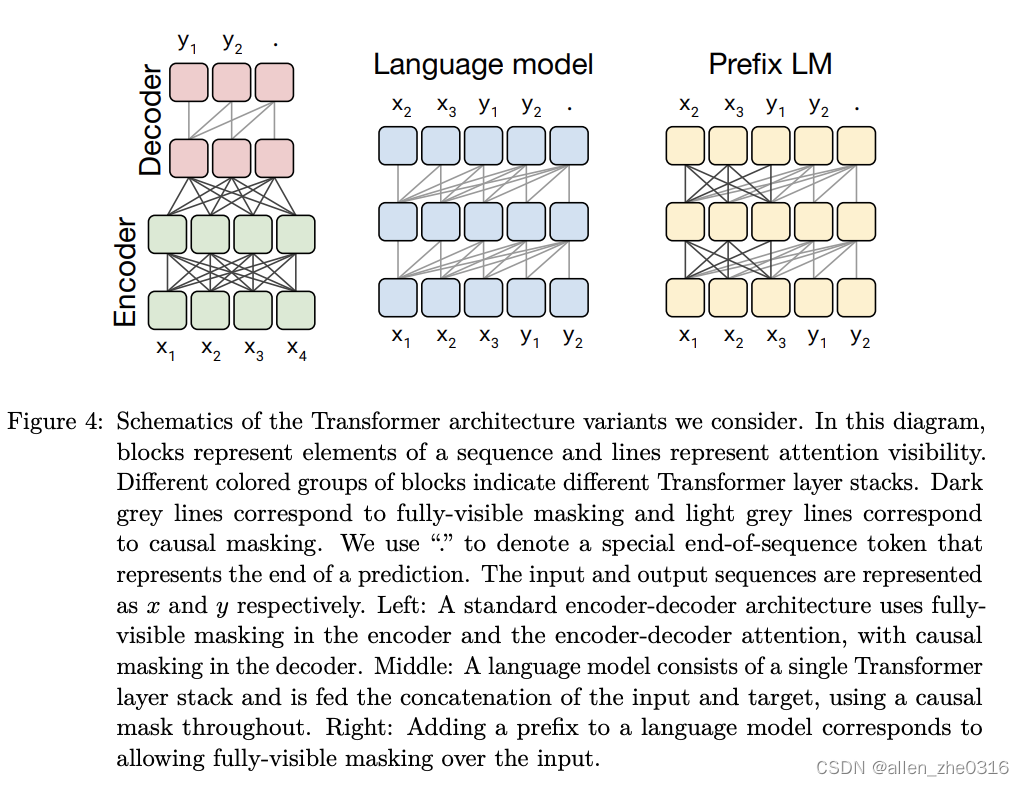
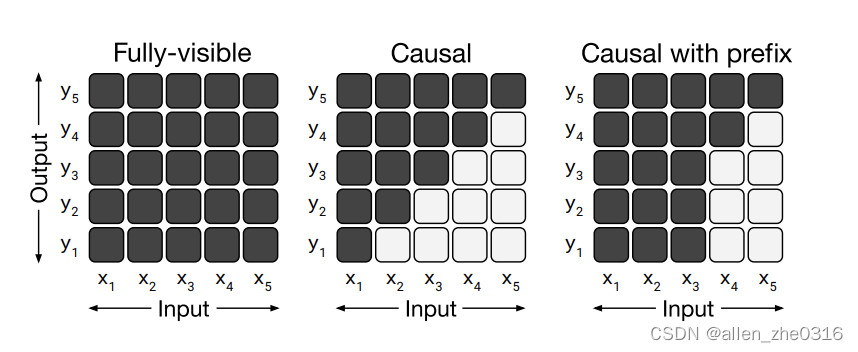
对应下来就是三种mask方式:
encode-decode就是mask方式1和2。language model就是方式2。prefix lm就是方式3。
预训练方法
-
语言模型式,就是 GPT-2 那种方式,从左到右预测;
-
BERT-style 式,就是像 BERT 一样将一部分给破坏掉,然后还原出来;
-
Deshuffling (顺序还原)式,就是将文本打乱,然后还原出来。
t5模型通过实验对比,发现text to text场景下的预训练更适合bert-style。这里的bert-style就是masked掉一个词,然后经过trans的encoder部分和decoder部分算分数,求loss。这样更适合我们text to text 的范式,生成式的预测。
T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=1024, bias=False)
(k): Linear(in_features=1024, out_features=1024, bias=False)
(v): Linear(in_features=1024, out_features=1024, bias=False)
(o): Linear(in_features=1024, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=1024, out_features=1024, bias=False)
(k): Linear(in_features=1024, out_features=1024, bias=False)
(v): Linear(in_features=1024, out_features=1024, bias=False)
(o): Linear(in_features=1024, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseReluDense(
(wi): Linear(in_features=1024, out_features=4096, bias=False)
(wo): Linear(in_features=4096, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(relu_act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)可以发现代码实现里是不存在multi masked attention的,个人觉得原因是:encoder出来的embedding 包含了masked的embedding,那如果把这部分embedding代入到masked attention的计算中,肯定是不合理的。















 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









