






LoRA微调三步骤是:
Step-1:观察&测试原模型(如MT5)的input和output格式。
Step-2:准备Training data,建立自己的Dataset类别,并拿原模型实际训练。
Step-3:将LoRA外挂到MT5-Small,并进行协同训练及测试。
在本篇文章中,将以MT5-small预训练大模型为例,并以Python源码(Source Code)来说明之。
简介LoRA
当今大家非常关心于LLM大模型的巨大参数量,带来的很高的训练成本,因而限制了诸多下游任务的应用。换句话说,由于大语言模型(LLM)的参数量巨大,许多大公司都需要训练数月,因此许多专家们提出了各种资源消耗较小的训练方法,而其中最常用的就是:LoRA。
由于LoRA的模型参数非常轻量,对于下游任务而言,每一个下游任务只需要独立维护自身的LoRA参数即可。因之,可以节省*.ckpt和*.onnx的储存空间。同时,在训练时可以冻结原模型(如MT5)的既有参数,只需要更新较轻量的LoRA参数即可。可大幅提升模型的训练效能。
使用LoRA时,我们并不需要对原有大模型进行训练及调整参数,只需要训练橙色区域中的A和B两部分的参数即可。
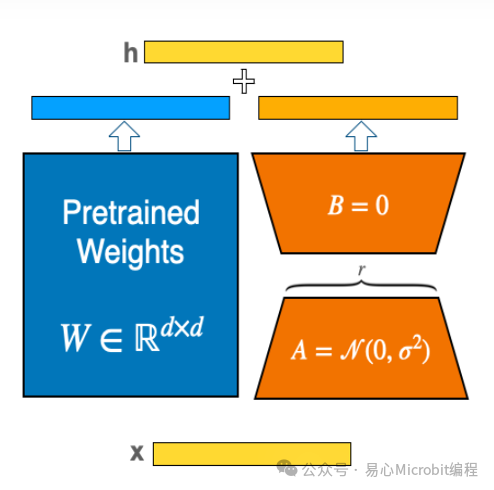
一般而言,LoRA 可以应用于神经网络中权重矩阵的任何子集,以减少可训练参数的数量。然而,在 Transformer 模型中,为了简单性和参数效率,LoRA 通常仅应用于注意力(Attention)区块。
简介MT5
每个Transformer模型都基于庞大的语料库,进行很长时间的模型预训练。这个预训练阶段,让模型对任何上下文中的任何单词都能掌握其涵义。T5的核心主张是:将所有 NLP 任务都转化成 Text-to-Text (文本到文本)任务。如下图:
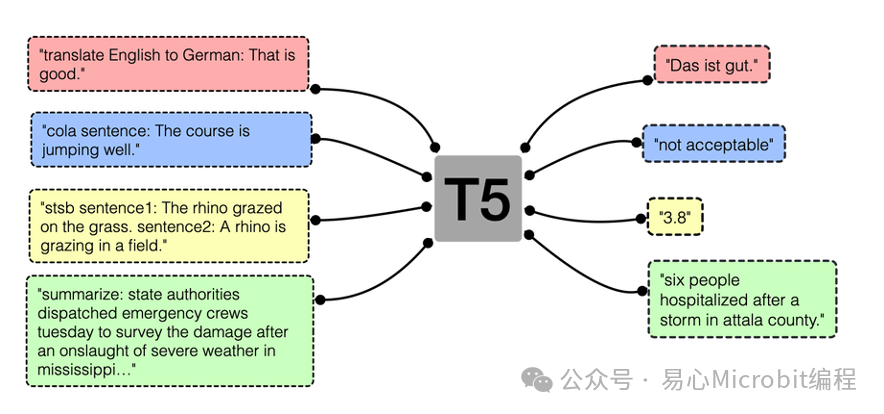
这T5是“ Transfer Text-to-Text Transformer ” 名称的缩写,在 2019 年底提出。T5 使用基本的编码器-译码器Transformer 架构。MT5是T5 的多语言延伸。MT5的5种不同大小的变体:小模型、基础模型、大模型、XL和XXL模型。例如,在这本篇文章的范例里,所使用的是小模型的MT5,称为:“ mt5-small ”。
范例说明
Step-1:观察&测试原模型(如mt5)的input和output格式
以一个范例程序,来演示这个步骤。程序代码:
# mt5_lora_001_test.py
#了解原模型(mt5)的input和output格式
import numpy as np
import torch
import torch.nn as nn
from transformers import MT5Tokenizer, MT5ForConditionalGeneration
model_name = “google/mt5-small”
#======== 载入预训练tokenizer ========================
tokenizer = MT5Tokenizer.from_pretrained(model_name)
#======== 加载mt5_small pre-trained模型 ==============
mt5_model = MT5ForConditionalGeneration.from_pretrained(model_name)
#--------- 测试input ------------------------------
#有一位农夫只是天天挑水浇花,对花很有爱心,舍不得摘花去卖,
#因而他成为大富翁。
text = "There was a farmer who only liked to " \
+ "carry water to water the flowers every day. " \
+ "He loved flowers very much and was reluctant " \
+ “to pick flowers to sell, so he became a rich man.”
#======= 对pre-trained model进行测试=================
#解析词汇
text_features = tokenizer( text, max_length=16,
padding=‘max_length’,
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors=‘pt’
)
bids = text_features[‘input_ids’]
batt = text_features[‘attention_mask’]
outputs = mt5_model.generate(input_ids=bids, attention_mask=batt,
max\_length=513, num\_beams=4,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
print(‘\n======== model outputs ========’)
print(outputs)
gid = outputs[0]
print(‘\n======== decoder result ========’)
res = tokenizer.decode(gid)
print(res)
#-----------------
#END
首先,执行到指令:

就会加载预训练模型:”google/mt5-small”。接着,下列指令是准备一个输入的文句(Text):

接着,下列指令解析输入的文句:

就得到该文句的特征,即text_features。接着,指令:

就将text_features输入给mt5-small模型,而输出outputs。最后,由decoder输出结果:

这个范例程序的用意是:检查是否能顺利下载原模型(即”google/mt5-small”),并观察输入文句的格式。
Step-2:准备Training data,建立自己的Dataset类别,并拿原模型实际训练
上一步骤已经顺利下载原模型(即”google/mt5-small”),并能云行起来。那么,就可以准备Training data来训练它。我们就以一个范例程序,来演示这个步骤:
# mt5_lora_002_train.py
# 准备Training data,建立自己的Dataset类别
# 并拿原模型实际训练
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from transformers import MT5Tokenizer
from transformers import MT5Config, MT5ForConditionalGeneration
model_name = “google/mt5-small”
#======== 载入预训练tokenizer ========================
tokenizer = MT5Tokenizer.from_pretrained(model_name)
mt5_model = MT5ForConditionalGeneration.from_pretrained(model_name)
#======== 准备source文本============================
#在机器翻译任务中,需要将来源文本转换为模型可以处理的格式。
#使用MT5Tokenizer可以将文本转换为token-ids,
#然后将它们输入到模型中。
#--------- 第1笔---------------------------------
#有一位农夫只是天天挑水浇花,对花很有爱心,舍不得摘花去卖,
#因而他成为大富翁。
text_1 = "There was a farmer who only liked to " \
\+ "carry water to water the flowers every day. " \\
+ "He loved flowers very much and was reluctant " \
+ “to pick flowers to sell, so he became a rich man.”
#--------- 第2笔---------------------------------
#有一位森林管理者只是叫啄木鸟好好关注它爱吃的虫儿,因而森林里
#的树木都没虫害,因而很健康。
text_2 = "There was a forest manager who just asked the " \
+ "woodpecker bird to pay attention to the insects it " \
+ "loved to eat, so the trees in the forest were " \
+ “insect-free and very healthy.”
#--------- 第3笔---------------------------------
#一个人想去南极找企鹅,它眼睛关注着北极星,双手努力划船,
#逐渐就见到南极许多企鹅了。
text_3 = "A man wanted to go to Antarctica to find " \
+ "penguins. He focused his eyes on the North " \
+ "Star and rowed hard with both hands, and gradually " \
+ “he saw many penguins in Antarctica.”
text_list = [text_1, text_2, text_3]
#======== 准备target文本============================
#爱心致富,符合鸟性,把握方向
summary_list = [“Love makes you rich, such as loving flowers.”,
“In line with bird nature, humans get healthy trees.”,
“Gaze at the North Star and reach the Antarctic to see penguins.”]
#======== 建立DS&DL ================================
class myDataset(Dataset):
def __init__( self ):
self.text_max_len = 16
self.summary_max_len = 8
def __len__(self):
return 3
def __getitem__(self, idx):
text = text_list[idx]
text_features = tokenizer(
text,
max_length=self.text_max_len,
padding=‘max_length’,
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors=‘pt’
)
summ = summary_list[idx]
summary_features = tokenizer(
summ,
max_length=self.summary_max_len,
padding=‘max_length’,
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors=‘pt’
)
#return text_features, summary_features
labels = summary_features[‘input_ids’]
labels[labels == tokenizer.pad_token_id] = -100
return dict(
input_ids=text_features[‘input_ids’].flatten(),
attention_mask=text_features[‘attention_mask’].flatten(),
labels=labels.flatten(),
decoder_attention_mask=summary_features[‘attention_mask’].flatten()
)
ds = myDataset()
dl = DataLoader(ds, shuffle=True, batch_size=3)
#======== 展开训练====================================
optimizer = torch.optim.Adam(mt5_model.parameters(), lr=0.0004)
mt5_model.train()
epochs = 10
print(‘\n开始训练…’)
for ep in range(epochs):
#print(ep)
for batch in dl:
inputs = {k: v for k, v in batch.items()}
outputs = mt5_model(**inputs)
logits = outputs.logits
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
pass
if(ep%2==0):
print(f’ep: {ep + 1} – loss: {loss}')
#------------------------------------------
print(‘\nok’)
#END
首先,准备3个source文本,以及3个target文本。来作为Training dataset。然后展开训练,输出如下:

这个范例程序的用意是:检验Training data格式的正确性,是否能顺利输入给原模型(即”google/mt5-small”),并观察optimizer设定,以及loss的计算。并观察loss的下降情形。
Step-3:将LoRA外挂到MT5-Small,并进行协同训练及测试
以一个范例程序,来演示这个步骤:
# mt5_lora_003_lora.py
# 挂上LoRA,并进行训练及测试
import numpy as np
import torch
import torch.nn as nn
from functools import partial
from torch.utils.data import Dataset, DataLoader
from transformers import MT5Tokenizer
from transformers import MT5Config, MT5ForConditionalGeneration
import min_lora_model as Min_LoRA
import min_lora_utils as Min_LoRA_Util
model_name = “google/mt5-small”
#======== 载入预训练tokenizer ========================
tokenizer = MT5Tokenizer.from_pretrained(model_name)
mt5_model = MT5ForConditionalGeneration.from_pretrained(model_name)
#--------添加LoRA ------------
my_lora_config = {
nn.Linear: {
“weight”: partial(Min_LoRA.LoRAParametrization.from_linear, rank=16),
}, }
#---- 把LoRA参数添加到原模型------
# Step 1: Add LoRA to the unet model
Min_LoRA.add_lora(mt5_model, lora_config=my_lora_config)
#---------------------------------------------------------------
parameters = [
{“params”: list(Min_LoRA_Util.get_lora_params(mt5_model))}, ]
#只更新、优化LoRA的Weights
optimizer = torch.optim.Adam(parameters, lr=0.0004)
#======== 准备source文本============================
#在机器翻译任务中,需要将来源文本转换为模型可以处理的格式。
#使用MT5Tokenizer可以将文本转换为token-ids,
#然后将它们输入到模型中。
#--------- 第1笔---------------------------------
#有一位农夫只是天天挑水浇花,对花很有爱心,舍不得摘花去卖,
#因而他成为大富翁。
text_1 = "There was a farmer who only liked to " \
+ "carry water to water the flowers every day. " \
+ "He loved flowers very much and was reluctant " \
+ “to pick flowers to sell, so he became a rich man.”
#--------- 第2笔---------------------------------
#有一位森林管理者只是叫啄木鸟好好关注它爱吃的虫儿,因而森林里
#的树木都没虫害,因而很健康。
text_2 = "There was a forest manager who just asked the " \
+ "woodpecker bird to pay attention to the insects it " \
+ "loved to eat, so the trees in the forest were " \
+ “insect-free and very healthy.”
#--------- 第3笔---------------------------------
#一个人想去南极找企鹅,它眼睛关注着北极星,双手努力划船,
#逐渐就见到南极许多企鹅了。
text_3 = "A man wanted to go to Antarctica to find " \
+ "penguins. He focused his eyes on the North " \
+ "Star and rowed hard with both hands, and gradually " \
+ “he saw many penguins in Antarctica.”
text_list = [text_1, text_2, text_3]
#======== 准备target文本============================
#爱心致富,符合鸟性,把握方向
summary_list = [“Love makes you rich, such as loving flowers.”,
“In line with bird nature, humans get healthy trees.”,
“Gaze at the North Star and reach the Antarctic to see penguins.”]
#======== 建立DS&DL ================================
class myDataset(Dataset):
def __init__( self ):
self.text_max_len = 16
self.summary_max_len = 8
def __len__(self):
return 3
def __getitem__(self, idx):
text = text_list[idx]
text_features = tokenizer(
text,
max_length=self.text_max_len,
padding=‘max_length’,
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors=‘pt’
)
summ = summary_list[idx]
summary_features = tokenizer(
summ,
max_length=self.summary_max_len,
padding=‘max_length’,
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors=‘pt’
)
labels = summary_features[‘input_ids’]
labels[labels == tokenizer.pad_token_id] = -100
return dict(
input_ids=text_features[‘input_ids’].flatten(),
attention_mask=text_features[‘attention_mask’].flatten(),
labels=labels.flatten(),
decoder_attention_mask=summary_features[‘attention_mask’].flatten()
)
ds = myDataset()
dl = DataLoader(ds, shuffle=True, batch_size=3)
#======== 展开MT5 + LoRA 协同训练=====================
print(‘\n展开MT5 + LoRA 协同训练…’)
mt5_model.train()
epochs = 50
for ep in range(epochs):
for batch in dl:
inputs = {k: v for k, v in batch.items()}
outputs = mt5_model(**inputs)
logits = outputs.logits
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
pass
if(ep%5==0):
print(f’ep: {ep + 1} – loss: {loss}')
#------------------------------------------
base_path = ‘c:/ox/’
FILE = base_path + ‘MT5_LORA_003_30.ckpt’
torch.save(mt5_model.state_dict(), FILE)
print("\n— Saved to " + FILE)
#-------------- 进行检测 -------------------
text = text_list[0]
text_features = tokenizer(
text,
max_length=16,
padding=‘max_length’,
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors=‘pt’
)
outputs = mt5_model.generate(
input_ids=text_features[‘input_ids’],
attention_mask=text_features[‘attention_mask’],
max_length=513,
num_beams=4,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
print(‘\n======== model outputs ========’)
print(outputs)
gid = outputs[0]
print(‘\n======== decoder result ========’)
res = tokenizer.decode(gid)
print(res)
#--------------------------------------------
#END
首先,执行到指令:

就把LoRA参数外挂到MT5模型上,继续执行到指令:

设定:optimizer只会更新LoRA的参数,亦即,冻结原模型的参数。然后,展开协同训练,输出:

观察loss的下降情形。最后,输入测试文本,输出测试结果:

这样就完成了:LoRA外挂到MT5。然后,就可以使用实际大量的Training dataset,继续迈向美好的微调之路。
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

















 1740
1740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











