






比较常见的transformer的绝对位置编码长这样:
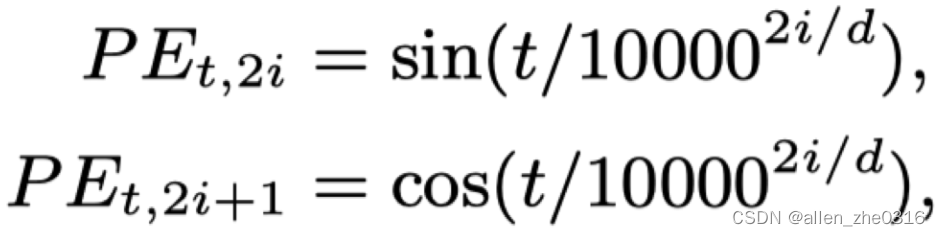
这样的编码包含了token的序列信息和在该序列的位置信息,从而描述了token的位置信息特征。另外,使用sin,cos最重要的一个原因是为了很好的外推相对位置编码,sin(α+β)=sinαcosβ+cosαsinβ 以及 cos(α+β)=cosαcosβ−sinαsinβ
对于处理长序列问题,我们如果能获取到不同token的相对位置信息,那模型的能力将会变得更强。但是以上的绝对位置编码,会造成相对位置的缺失。
在自注意力机制的计算如下:第i个单词和第j个单词的attention score的计算
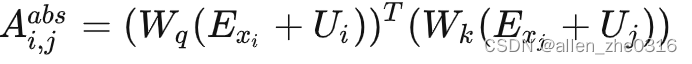 Exi和Exj是xi和xj的词嵌入,Ui和Uj是第i个位置和第j个位置的位置向量。因式分解得到下式:
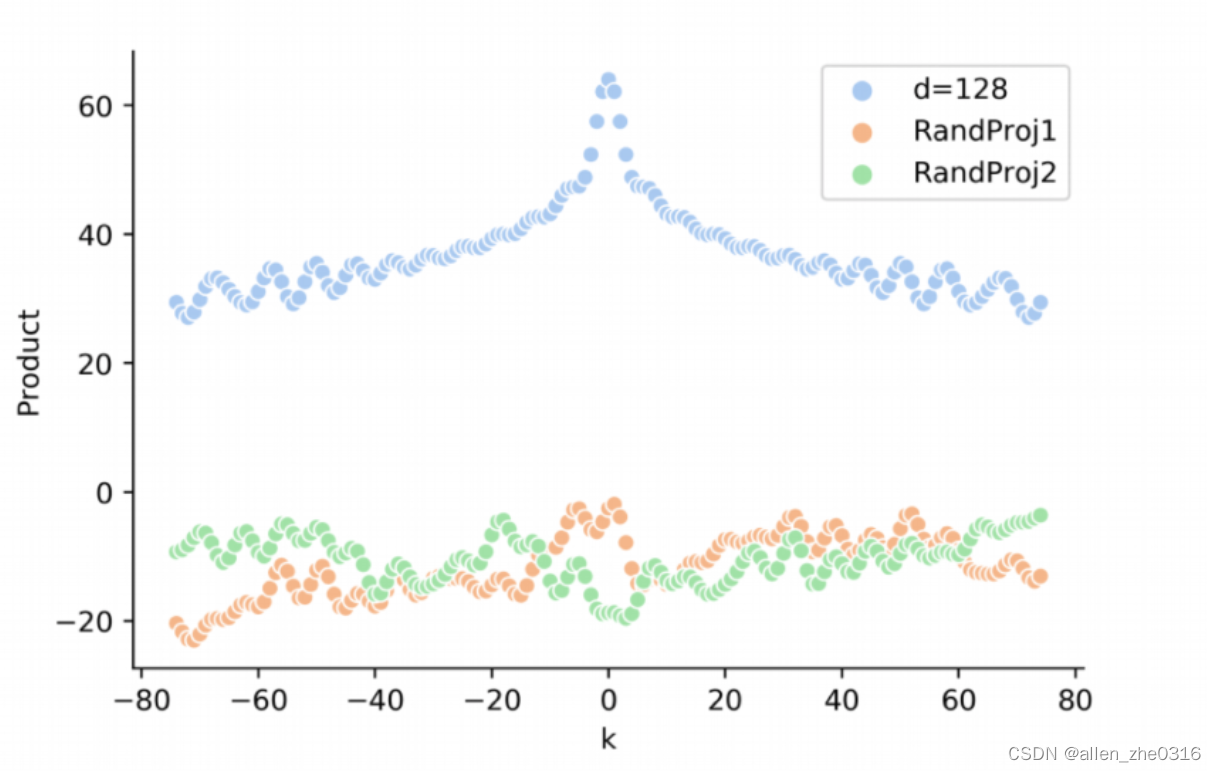
Exi和Exj是xi和xj的词嵌入,Ui和Uj是第i个位置和第j个位置的位置向量。因式分解得到下式: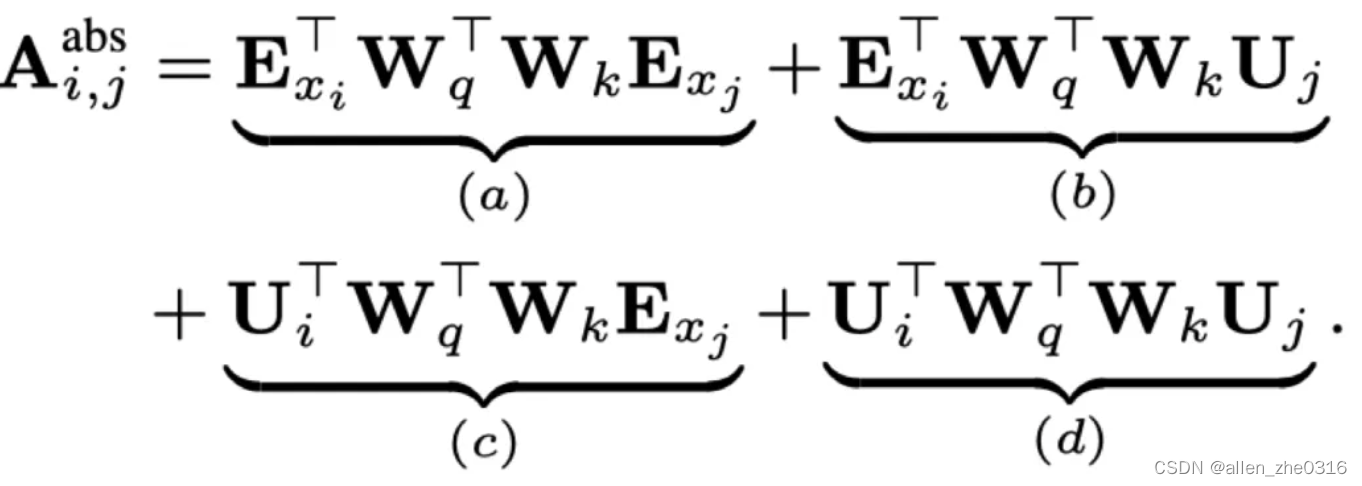 对UiWqWkUj (橙色和绿色) 与 UiUj的分布进行比较,k表示两个token的距离,可以看到加了非线性变换后就不存在相对位置信息了。
对UiWqWkUj (橙色和绿色) 与 UiUj的分布进行比较,k表示两个token的距离,可以看到加了非线性变换后就不存在相对位置信息了。
引入相对位置信息:
绝对位置做法:
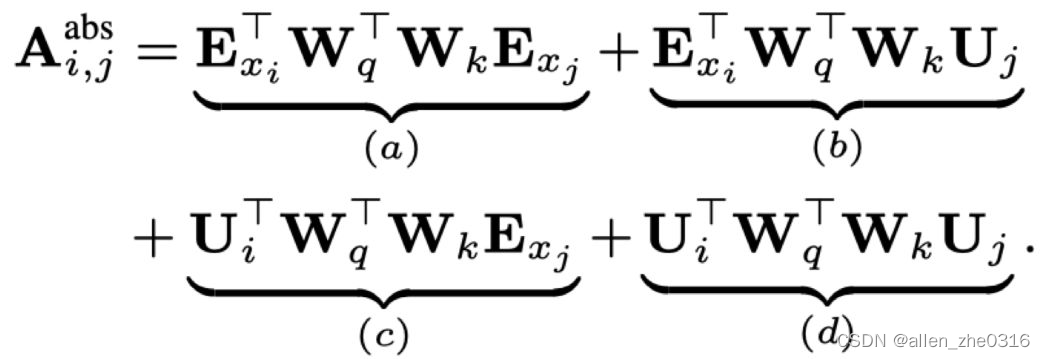 xl-net的做法:设一个基准值Ui,将Uj用Ri-j来表示,Ui本身就用u或v表示。
xl-net的做法:设一个基准值Ui,将Uj用Ri-j来表示,Ui本身就用u或v表示。
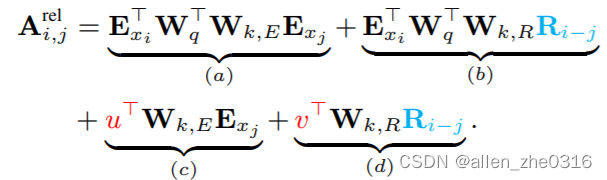 t5的做法:将上面的a,b,c全部取消掉,只保留d的改进版:ExiWqWkExj + βi,j,简单来说就是将相对位置信息放在一个参数里学习。
t5的做法:将上面的a,b,c全部取消掉,只保留d的改进版:ExiWqWkExj + βi,j,简单来说就是将相对位置信息放在一个参数里学习。















 968
968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









