






 本文介绍了如何使用R语言中的prcomp函数实现PCA,通过iris数据集展示了从数据准备、预处理到结果可视化的过程,强调了PCA在数据降维和结构探索中的重要性。
本文介绍了如何使用R语言中的prcomp函数实现PCA,通过iris数据集展示了从数据准备、预处理到结果可视化的过程,强调了PCA在数据降维和结构探索中的重要性。
主成分分析(PCA)是一种广泛使用的数据降维技术,它可以帮助我们识别数据中最重要的特征并简化复杂度,同时尽量保留原始数据的关键信息。在这篇文章中,我们将通过一个具体的例子,使用R语言实现PCA,展示其在实际数据集上的应用。
背景和理论基础
PCA通过线性变换将原始数据转换到新的坐标系统中,新坐标(即主成分)的选择是基于数据的方差最大化。换句话说,第一个主成分具有最大的方差,每个随后的主成分都在与前面主成分正交的意义上具有最大的方差。
R语言实现步骤
在R中实施PCA相对直接,因为stats包中已经包含了执行PCA的函数prcomp()。以下是使用R语言进行PCA的详细步骤:
1. 准备工作和数据加载
我们将使用R内置的数据集iris来展示如何进行PCA。iris数据集包含了150个样本的4个特征,这些特征是花瓣和萼片的长度和宽度,以及每个样本的种类标签。
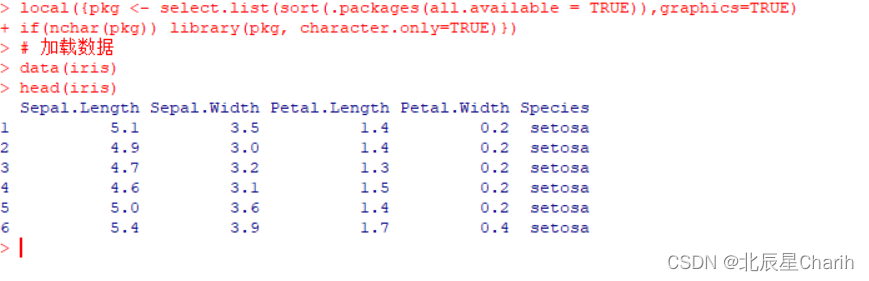
# 加载数据
data(iris)
head(iris)
2. 数据预处理
虽然iris数据集已经很干净,但通常我们需要进行数据标准化,以确保每个特征在PCA中的贡献是平等的。
# 仅提取数值数据用于PCA
iris.pca <- prcomp(iris[,1:4], scale. = TRUE)

这里,prcomp函数用于执行PCA,scale.参数设置为TRUE以进行数据标准化。
3. 查看PCA结果
执行PCA后,我们可以查看各主成分的方差解释率,这有助于我们了解每个主成分保留了多少信息。
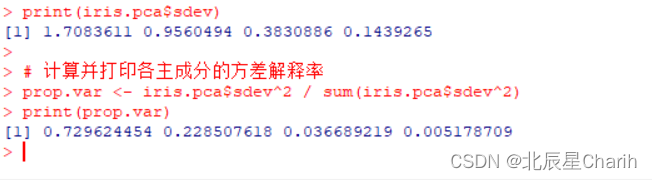
# 查看主成分的标准偏差(即特征值的平方根)
print(iris.pca$sdev)
# 计算并打印各主成分的方差解释率
prop.var <- iris.pca$sdev^2 / sum(iris.pca$sdev^2)
print(prop.var)
4. 可视化PCA结果
我们可以将PCA的结果可视化,以直观地展示数据点在主成分空间中的分布。
# 绘制前两个主成分
plot(iris.pca$x[,1:2], col=iris$Species, pch=19, xlab="PC1", ylab="PC2")
legend("topright", legend=levels(iris$Species), col=1:3, pch=19)
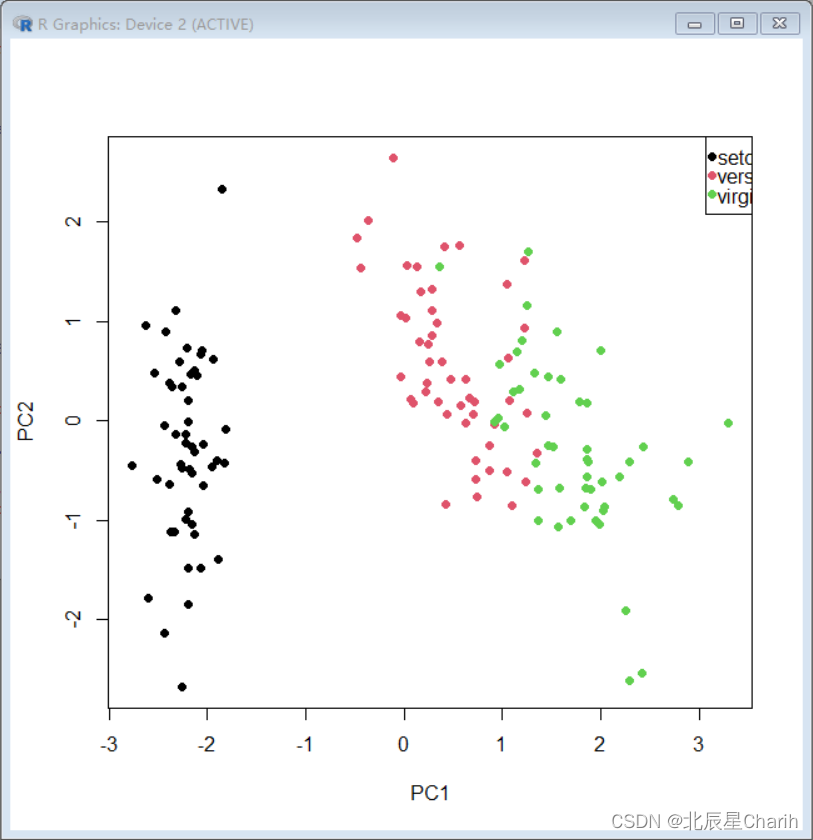
这段代码将数据点根据它们的种类在由第一和第二主成分构成的平面上进行了绘制。
总结
使用R语言进行PCA是一个直观且有效的方法来降低数据维度并探索数据结构。通过上述步骤,我们可以不仅看到数据在主成分上的投影,而且可以量化每个主成分的重要性。PCA在许多领域都有广泛的应用,包括基因组学、金融和市场研究等,它是任何数据科学家工具箱中的重要工具之一。
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











