







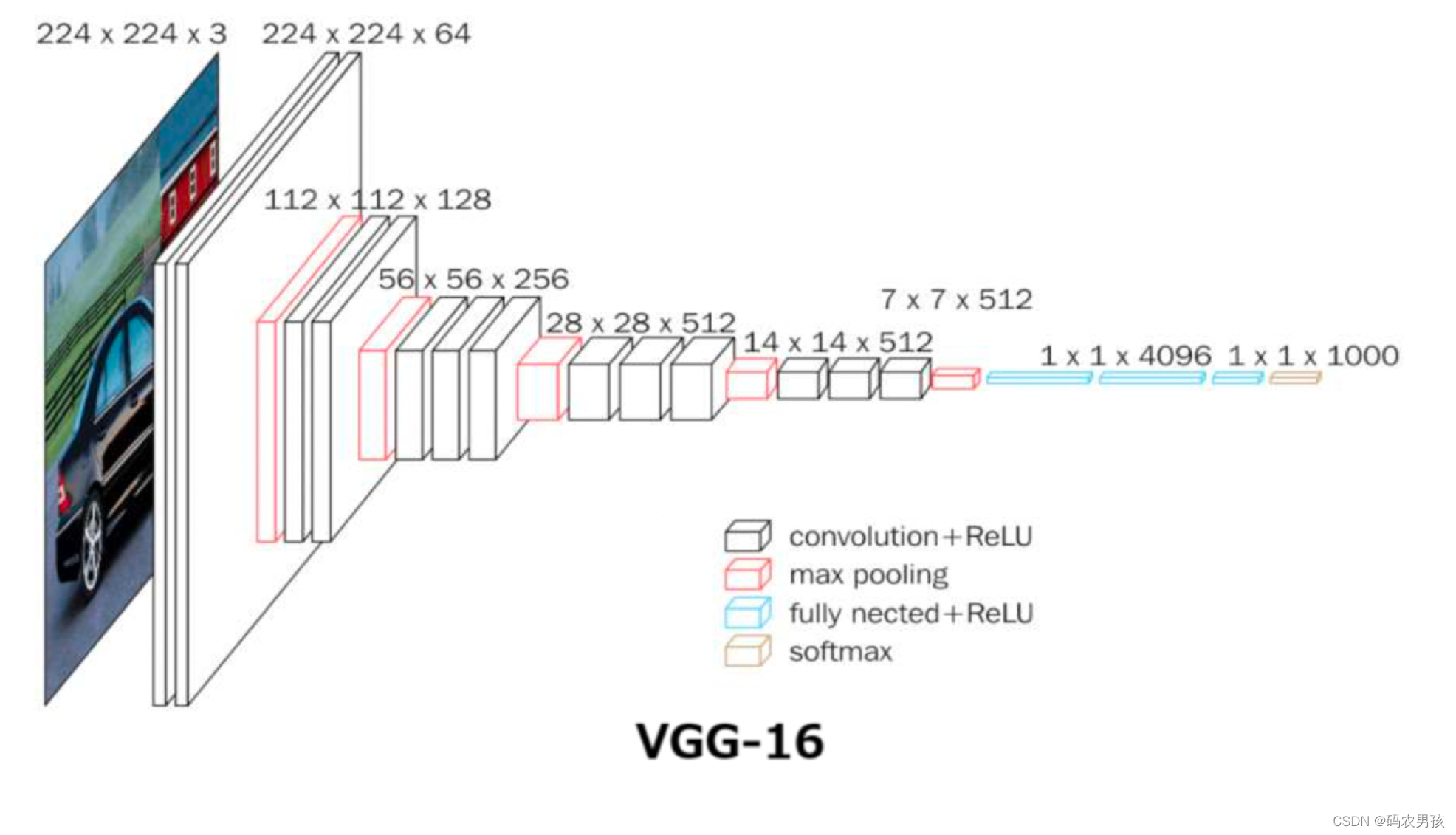
上图为VGG16的网络架构可视化图,白色部分为卷积层,红色部分为池化层
一、预训练权重下载
当然编译器可以自动下载,只要把download设置为True,下载速度因人而异。建议自己下载,然后手动加载权重。下载地址如下:
-
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth' 'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth' 'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth' 'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth' 'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth' 'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth' 'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth' 'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth'
二、PyTorch中VGG结构定义
在实际应用时,我们直接调用封装好的包即可,无需从0开始搭建网络。不过前提还是要明白代码是如何搭建的。
import torch
import torch.nn as nn
# 类定义
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features # 核心:特征提取
self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) # 自适应池化至7*7
self.classifier = nn.Sequential( # 分类器
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











