






机器学习 | 决策树和信息增益
决策树
①决策树基于特征的信息增益ID3或者信息增益比C4.5,逐个特征进行处理,更加接近人的决策方式
②产生的模型具有可解释性
③拟合出来的函数其实是分区间的阶梯函数。
④决策树可以表示输入属性的任何函数,但对同样一个训练数据集,决策树不唯一
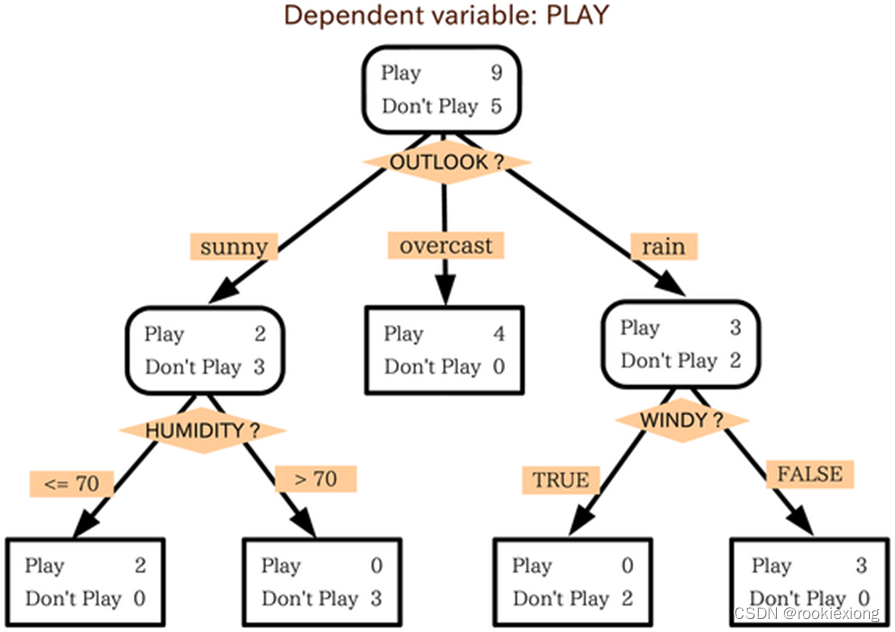
决策树的TOP-DOWN构造算法
- 𝐴←下一个结点node的最好属性
- 把𝐴作为决策属性赋给结点node
- 对𝐴的每一个取值,创建一个新的儿子结点node
- 把相应的训练样本分到叶结点
- 如果训练样本被很好的分类,则停止,否则在新的叶结点上重复上述过程
很好的分类: 一个节点上所有样本为一个类别(分类) or 一个节点上具有相似的属性值(回归)
待测条件的确定:
- 依赖于属性类型(名词性\离散、有序的、连续)
- 依赖于切分的分支个数(两路切分 or 多路切分)
但二值决策需要考虑可能的切分并选择最好的,计算量较大
决策树的优点
- 构建过程计算资源开销小
- 分类未知样本速度极快
- 对于小规模的树比较容易解释
- 在许多小的简单数据集合上性能与其它方法相近
决策树的缺点
- 只考虑对训练数据的拟合
- 欠拟合——模型对数据的复杂性或特征之间的关系进行了过于简单的建模,导致模型在训练数据上表现不佳
- 过拟合——导致决策树比必要的更复杂,训练误差不再能够很好地估计树在以前未见过的记录上的表现
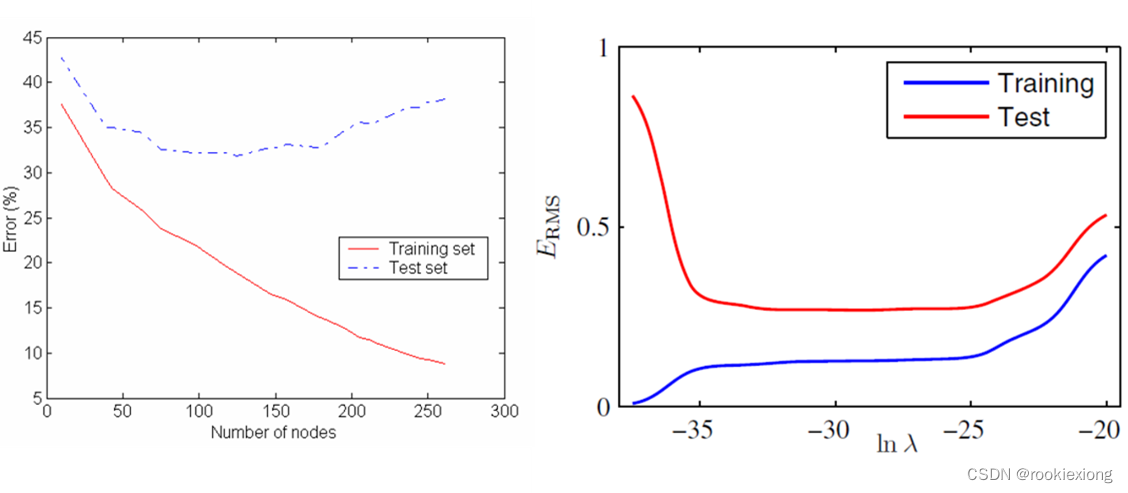
决策树的剪枝
早停法(预剪枝),在原来的停止条件基础上增加更多的限制性条件
- 如果实例数量小于用户指定的阈值,则停止——避免在数据样本太少的情况下创建过于复杂的树结构,从而降低了模型的泛化能力
- 如果实例的类分布独立于可用实例特征(例如,使用𝝌^𝟐检验),则停止——特征与类别之间没有显著的关联
- 如果扩展当前节点没有改善不纯度(例如,基尼或信息增益),则停止——防止不必要的树生长
后剪枝,完整地生长决策树,而后以自底向上的方式修剪决策树的节点
损失函数: 平衡正确率和模型复杂度(正则的思想):𝐶𝑜𝑠𝑡(𝑀𝑜𝑑𝑒𝑙, 𝐷𝑎𝑡𝑎)=𝐶𝑜𝑠𝑡(𝐷𝑎𝑡𝑎|𝑀𝑜𝑑𝑒𝑙)+ 𝐶𝑜𝑠𝑡(𝑀𝑜𝑑𝑒𝑙)
决策树的剪枝往往通过极小化决策树整体的损失函数(loss function)来实现。设树𝑇的叶结点个数为|𝑇| ,𝑡是树𝑇的叶结点,该叶结点有
N
t
N_t
Nt个样本点,其中𝑘类的样本点有
N
t
k
N_{tk}
Ntk个,𝑘=1,2,…,𝐾,
H
t
(
T
)
H_t(T)
Ht(T)为叶结点𝑡上的熵。
剪枝算法:
- 计算每个节点的熵
- 递归的从树的叶节点向上回缩
- 如果损失函数减小,则将父节点变为新的叶节点
- 重复步骤2,直至不能继续为止
信息增益
在一个条件下,信息复杂度(不确定性)减少的程度。和互信息等价
g
(
X
,
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
)
g(X,Y)=H(X)-H(X|Y)
g(X,Y)=H(X)−H(X∣Y)
优点:对于数据集D而言,信息增益依赖于特征,不同特征具有不同的信息增益,信息增益大的特征具有更强的分类能力
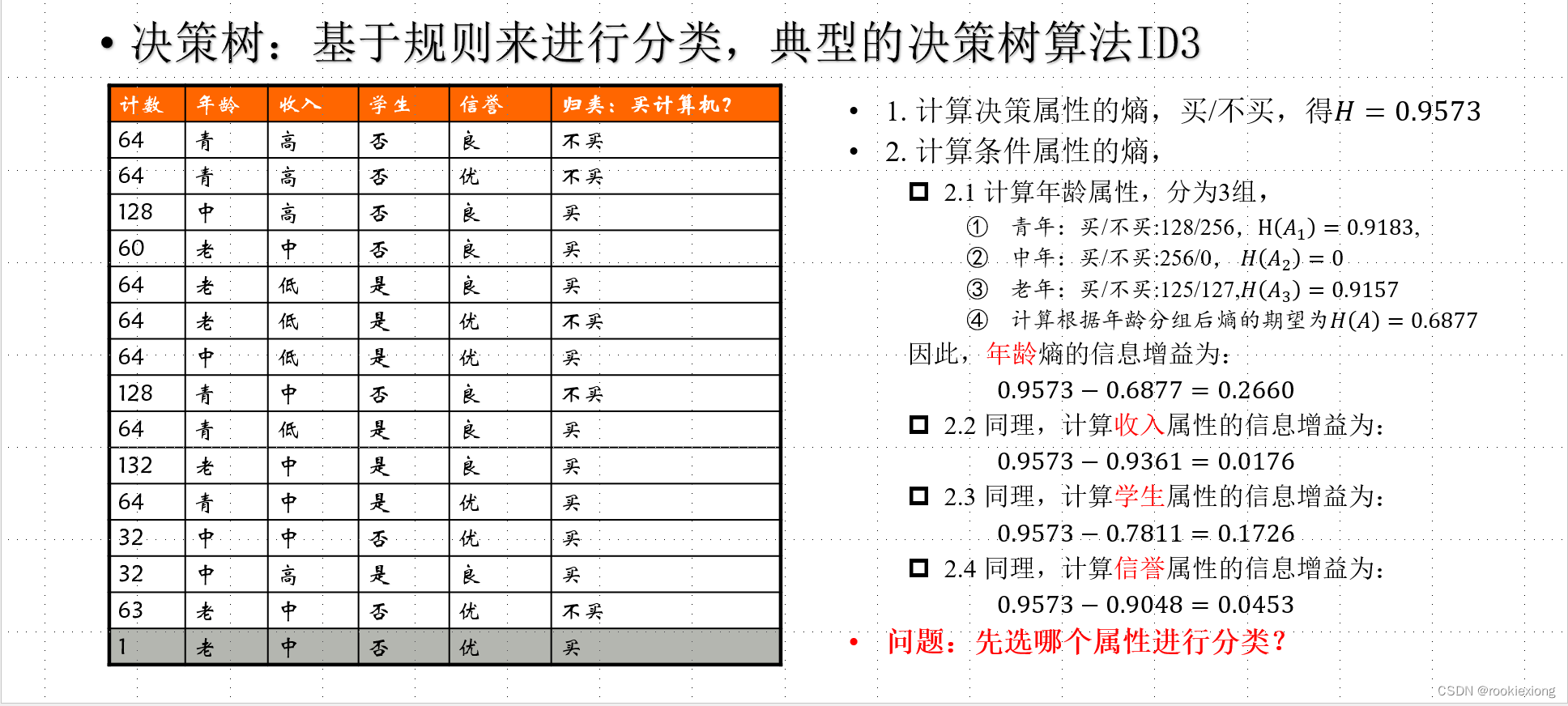














 1986
1986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









