






前置知识补充
norm
在机器学习中,norm常用来表达两个向量之间的距离关系,也称做p-norm,其定义如下:
当p取1时,称为L1-norm;当p取2时,称为L2-norm。
为了方便计算,对于一个向量X,他的L2-norm可以直接表示成:
符号表


新符号的解释:
d(x,y):即两个向量之间的距离,这里采用的计算方法是L2-norm
方法假设(Assumption)

作者假设如果用户a在第t-1个物品和第t个物品之间做出了某种动作,那么认为式(1)的右边项为左边项的最近邻居
预测公式(Predition Rule)
对于S序列中的物品t,第t-1个物品转移至第t个物品的可能性如下:

该方法的核心思想是距离近的两个物品相关性就更高,所以预测公式中,r的大小与距离成负相关。
式(2)中的两个embedding向量V需要在unit ball里面,所以要进行归一化处理。
而对于不在S序列中的物品j,第t-1个物品转移至物品j的可能性如下:

而在测试阶段,和 Fusing Similarity Models with Markov Chains方法一样,即测试时相当于预测第个物品,所以计算距离时embedding的下标应该取
,如下所示。

目标函数(Objective Function)

更新公式(Update Rule)
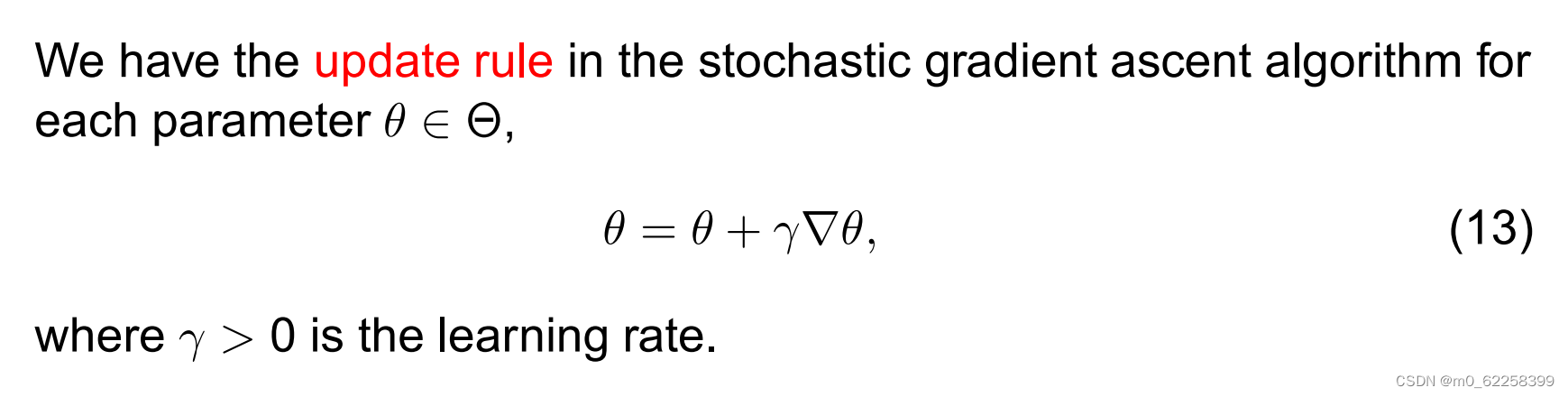
测试时的一个小技巧

由于我们预测公式中有用到bias,所以我们可以将bias做处理后补充在V的末尾,将V增广成d+1维。同样的,我们将近邻的最末尾添加一位0增广成d+1维。
这样一来bias的信息就被加入到V中,方便计算。














 4356
4356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









