






Bi-directional Contrastive Distillation for Multi-behavior Recommendation
Abstract
问题:目前存在的大部分模型都基于辅助行为对目标行为有正向作用的假设,这是不对的。
模型:BCD模型。可以从辅助行为中提取知识去帮目标行为,然后再将从目标行为中获取的知识反过来增强辅助行为的建模。这样噪声行为就不会被用于训练。
LightGCN没有考虑多行为问题,所以该论文对每个行为单独建图。
符号定义
定义用户的集合u如下:
U
=
{
u
1
,
u
2
,
.
.
.
,
u
m
}
U=\left\{u_1,u_2,...,u_m\right\}
U={u1,u2,...,um}
定义物品的集合v如下:
V
=
{
v
1
,
v
2
,
.
.
.
,
v
n
}
V=\left\{v_1,v_2,...,v_n\right\}
V={v1,v2,...,vn}
其中m,n分别代表用户和物品的数量。
定义行为的集合b如下:
B
=
{
b
1
,
b
2
,
.
.
.
,
b
k
}
B=\left\{b_1,b_2,...,b_k\right\}
B={b1,b2,...,bk}
其中k代表行为的总数、bk 表示第k个用户行为。
定义 Vu,bk为用户u进行bk行为交互的所有物品的集合。在本论文中,每个用户一共有三种不同的
物品集合,分别为Vu,view,Vu,buy,Vu,cart
Proposed Model
Multi-behavior GCN
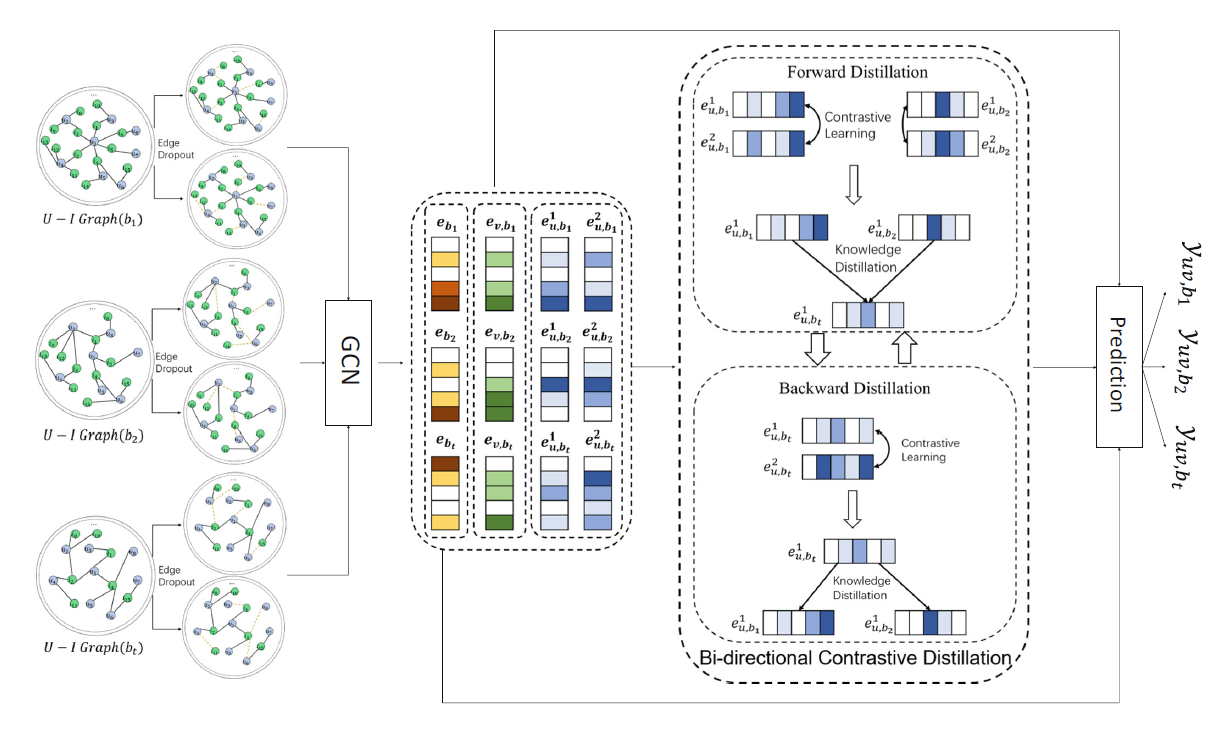
首先利用图结构,通过GCN学习用户和行为的表征。图的节点为用户和物品,边为用户和物品之间的交互关系。明确来说,对于用户u在第l层的embbeding e(l) u,bk 可以通过聚合该用户邻居(第l-1层中交互的物品),更新的公式如下
e
u
,
b
k
l
=
σ
(
∑
v
∈
N
u
1
∣
∣
N
u
∣
∣
N
u
∣
∣
W
(
l
)
ϕ
(
e
v
(
l
−
1
)
⨀
e
b
k
(
l
−
1
)
)
e^{l}_{u,b_k} = \sigma(\sum_{v\in{N_u}}{\frac{1}{\sqrt{||N_u| }\sqrt{|N_u||}}W^{(l)}\phi({e_v^{(l-1)}}\bigodot{e_{b_k}^{(l-1)}}})
eu,bkl=σ(v∈Nu∑∣∣Nu∣∣Nu∣∣1W(l)ϕ(ev(l−1)⨀ebk(l−1))
其中Nu和Nv是用户u和物品v的近邻,W(l)是第l层的权重,
⨀
\bigodot
⨀表示的是元素对应相乘,所以这里的结果规模不变。φ做的是聚合操作(什么操作?)。σ表示激活函数,本论文选用LeakyReLU函数。
1
∣
N
u
∣
∣
N
u
∣
\frac{1}{\sqrt{|N~u~| }\sqrt{|N~u~|}}
∣N u ∣∣N u ∣1 是归一化项,避免embedding的规模在做图卷积时变大(?)。对Nu集合中的所有物品做聚合操作并求和,就提取了邻居的行为和物品表征。
而对于物品v在第l层的embedding e(l) u,bk 也类似,更新公式为:
e
v
,
b
k
l
=
σ
(
∑
u
∈
N
v
1
∣
N
u
∣
∣
N
u
∣
W
(
l
)
ϕ
(
e
u
(
l
−
1
)
⨀
e
b
k
(
l
−
1
)
)
e^{l}_{v,b_k} = \sigma(\sum_{u\in{N_v}}{\frac{1}{\sqrt{|N_u| }\sqrt{|N_u|}}W^{(l)}\phi({e_u^{(l-1)}}\bigodot{e_{b_k}^{(l-1)}}})
ev,bkl=σ(u∈Nv∑∣Nu∣∣Nu∣1W(l)ϕ(eu(l−1)⨀ebk(l−1))
(
论文中没有提到 e v l e^{l}_{v} evl和 e u l e^{l}_{u} eul的更新方法,应该是沿用LightGCN的更新方法:

)
对于行为embeding,更新方式为过一个线性层,公式为:
e
b
k
l
=
W
b
k
(
l
)
e
b
k
(
l
−
1
)
e^l_{b_k} = W^{(l)}_{b_k}e^{(l-1)}_{b_k}
ebkl=Wbk(l)ebk(l−1)
在初始化时,我们用一个id embedding为用户、物品、行为embedding初始化,表示为
e
u
,
b
k
0
e^0_{u,b_k}
eu,bk0
e
v
,
b
k
0
e^0_{v,b_k}
ev,bk0
e
b
k
0
e^0_{b_k}
ebk0 。
Bi-directional Contrastive Distillation
知识补充
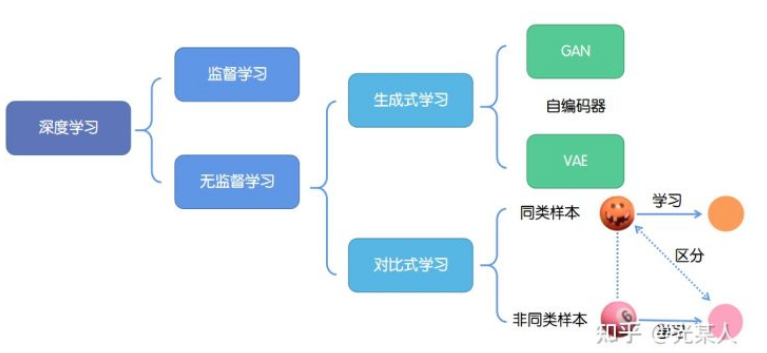
深度学习的成功往往依赖于海量数据的支持,其中对于数据的标记与否,可以分为监督学习和无监督学习。
1. 监督学习:技术相对成熟,但是对海量的数据进行标记需要花费大量的时间和资源。
2. 无监督学习:自主发现数据中潜在的结构,节省时间以及硬件资源。
2.1 主要思路:自主地从大量数据中学习同类数据的相同特性,并将其编码为高级表征,再根据不同任务进行微调即可。
2.2 分类:
2.2.1生成式学习
生成式学习以自编码器(例如GAN,VAE等等)这类方法为代表,由数据生成数据,使之在整体或者高级语义上与训练数据相近。
2.2.2对比式学习
对比式学习着重于学习同类实例之间的共同特征,区分非同类实例之间的不同之处。
与生成式学习比较,对比式学习不需要关注实例上繁琐的细节,只需要在抽象语义级别的特征空间上学会对数据的区分即可,因此模型以及其优化变得更加简单,且泛化能力更强。
对比学习的目标是学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。
模型解析
前一部分模型利用GCN学习了每个用户和物品的表征。接下来通过考虑两种用户不同行为之间的关系来完善这些表征:intra-behavior、inter-behavior。
对于intra-behavior ,设计一种对比学习的策略,增强同种用户不同form之间的相似度(不同form的相似度增大),同时拉大不同用户之间的差距(不同用户的相似度减小)。
因此采用一种edge dropout的方法运用在建立的交互图上,随机的去掉某些边,也就是随机的去掉某些用户和物品的交互关系,下面
为了分类,用符号 b a b_a ba, b t b_t bt, b k b_k bk 来分别表示辅助行为、目标行为和其他行为。对于同种行为,目标函数需要做到的是增大不同form(i.e., e u , b k 1 e^{1}_{u,b_k} eu,bk1 e u , b k 2 e^{2}_{u,b_k} eu,bk2)的相似度,所以将相同用户不同form的相似度作为分子,将不同用户的相同form的相似度作为分母。
对于相同form的情况,以 b a b_a ba为例如下所示( b t b_t bt b k b_k bk同理)。
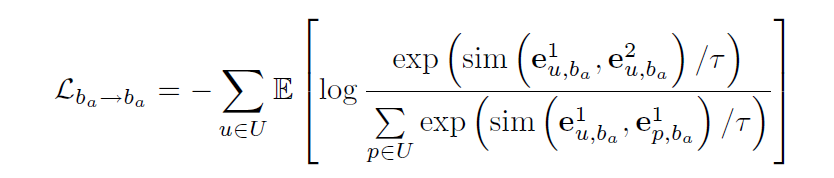
其中 τ \tau τ是温度参数,sim是相似度。
以上就是intra-behavior部分。
对于inter-behavior relation部分,与上述设计策略相似:对于同个用户,最大化辅助行为和目标行为的相似度,同时最大化不同用户直接辅助行为和目标行为的差异(即减小相似度)。具体公式如下:
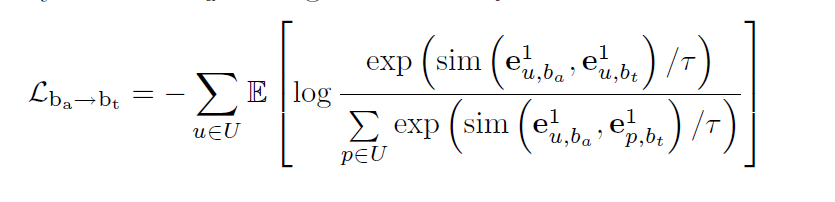
经过上述的two-step操作,也就是forward distillation操作后,能够实现从辅助行为到目标行为的良好迁移。收到NLP中bi-directional sequence learning的启发,作者设计了一个backward distillation部分来实现从目标行为到辅助行为的反馈,具体的实现如下:
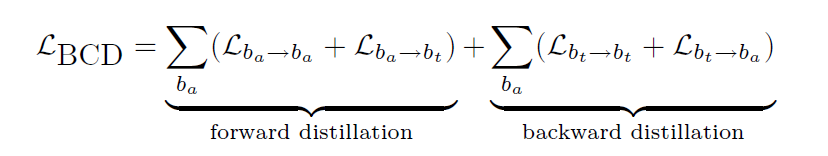
其中累加符号的意思是将所有的辅助行为都做一个双向提取。
Prediction and Learning
首先重构 e v l e^{l}_{v} evl和 e u l e^{l}_{u} eul,公式如下:
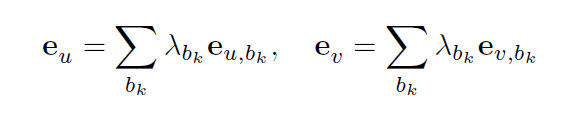
其中 λ b k \lambda_{b_k} λbk代表行为 b k {b_k} bk的权重(超参)。
预测评分就让三个embedding相乘聚合:
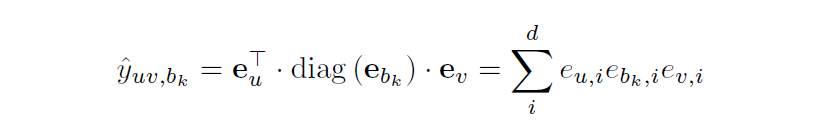
其中diag是将输入向量转换为三角矩阵的函数,d为embedding维度
本文的损失函数参考了论文==Chong Chen, Min Zhang, Weizhi Ma, Yiqun Liu and Shaoping Ma.**Efficient Non-Sampling Factorization Machines for Optimal Context-Aware Recommendation.The Web Conference 2020(WWW 2020)==的高效非采样训练,大致思路如下:
传统的非抽样loss定义如下:
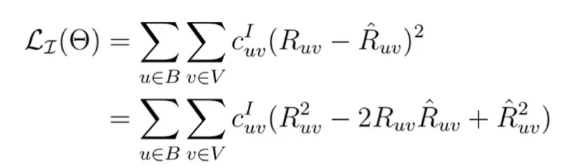
如果一个预测函数可以表示成一个矩阵分解的形式:
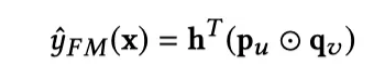
其中 p u {p_u} pu只和用户u的上下文有关, q v {q_v} qv只与物品v的上下文有关,h是一个辅助矩阵。
那么一种高效的非抽样loss就可以写成如下形式:
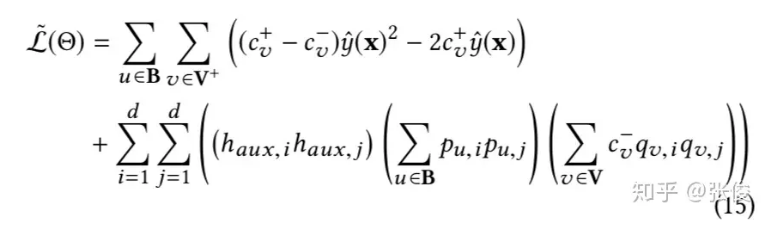
这种形式与传统的非抽样loss等效,但是复杂度会降低一个数量级
本文就采用了这种高效的非抽样loss,具体形式如下:
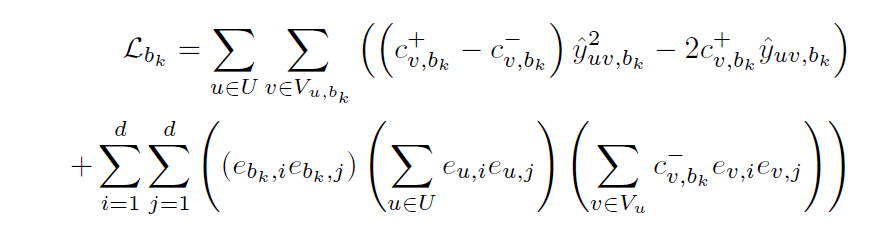
最后总的损失函数如下:
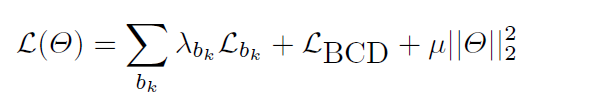
其中 θ \theta θ是模型参数, μ \mu μ为正则化参数。
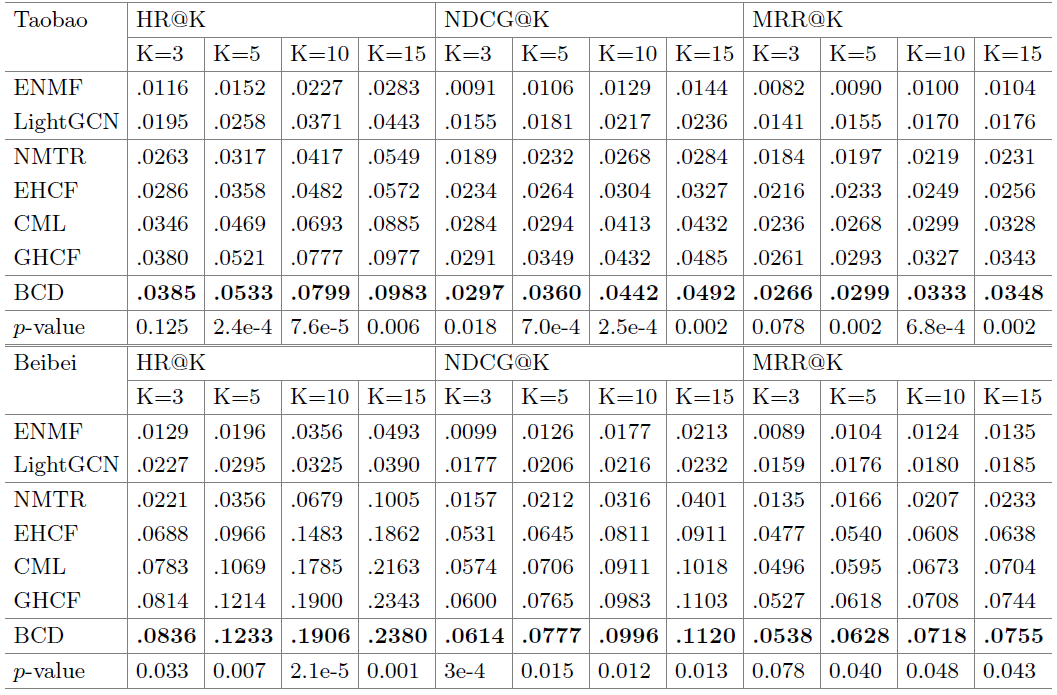
实验结果如下:















 7188
7188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









