










目录
1.6 在源数据中添加一列表示月份:astype(‘datetime[M]’)
2.2 所有用户每月的消费总次数(原始数据中的一行数据表示一次消费记录)
2.4 统计每月的消费人数(可能同一天一个用户会消费多次)nunique()表示统计去重后的个数
3.4 各个用户消费总金额的直方分布图(消费金额在1000之内的分布)
3.5 各个用户消费的总数量的直方分布图(消费商品数量在100次之内的分布)
4.4 分析得出每个用户的总购买量和总消费金额和最近一次消费时间的表格rfm
4.5 这里需要定义一个函数,针对RFM的表现进行8种类型的区分,RFM的标准都选择为其平均值
RFM分析模型
RFM是3个指标的缩写,最近一次消费时间间隔(Recency),消费频率(Frequency),消费金额(Monetary)。通过这3个指标对用户分类。
- 近度(Recency,最近一次消费到当前的时间间隔)
- 频度(Frequency,最近一段时间内的消费次数)
- 额度(Monetory,最近一段时间内的消费金额)
R-Recency(最近一次购买时间间隔),R指用户上一次消费的时间到目前统计时间的间隔,上一次购物时间距今最近的顾客,通常在近期响应营销活动的可能性也最大,对于APP而言,很久没有购物行为可能意味着用户放弃了APP的使用,重新唤起用户也需要更多的成本。
F-Frequency(消费频次),F指用户在某段时间内的购物次数,消费频率越高意味着这部分用户对产品的满意度最高,用户粘性最好,忠诚度也最高。
M-Money(消费金额),M指用户在某段时间内的购物金额,这也是为公司带来价值的最直接体现,而消费金额较高的用户在用户总体中人数较少,却能创造出更多价值,是需要重点争取的对象。
由于不同用户对公司带来的收益差别很大,而且根据二八定律20%的做有价值用户能带来80%的收益,因此需要对用户进行价值评价,找到最有价值的用户群,并针对这部分用户进行差异化的营销。
那RFM分析模型到底是如何计算的呢?以下让我们来用Python实现用户消费行为分析。
import numpy as np
import pandas as pd
import plotly.graph_objects as go
import plotly.express as px
import plotly.io as pio
pio.templates.default = 'plotly_dark'# 读取数据
columns = ['user_id','order_date','order_product','order_amout']
df = pd.read_csv('./CDNOW_master.txt',header=None,sep='\s+',names=columns)
df.head()
第一部分:数据类型处理
1.1 数据字段说明
| user_id | 用户ID |
| order_date | 购买日期 |
| order_products | 购买的产品数量 |
| order_amount | 购买金额 |
1.2 查看数据类型
df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 69659 entries, 0 to 69658 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 user_id 69659 non-null int64 1 order_date 69659 non-null int64 2 order_product 69659 non-null int64 3 order_amout 69659 non-null float64 dtypes: float64(1), int64(3) memory usage: 2.1 MB
1.3 数据中是否存在缺失值
df.issnull().any()user_id False order_date False order_product False order_amout False dtype: bool
1.4 将order_dt转化成时间类型
# 将order_dt转化成时间类型
df['order_date'] = pd.to_datetime(df['order_date'],format='%Y%m%d')1.5 查看数据的统计描述
# 查看数据的统计描述
df.describe() 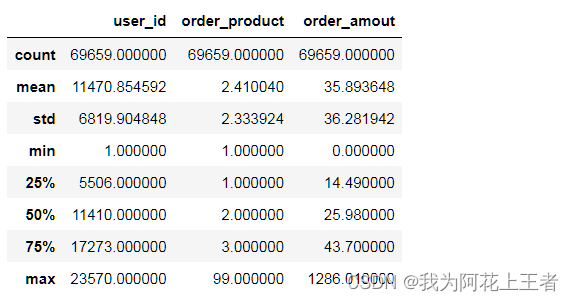
1.6 在源数据中添加一列表示月份:astype(‘datetime[M]’)
df['month'] = df['order_date'].astype('datetime64[M]')
df.head()
第二部分:按月数据分
2.1 用户每月的消费总金额
# 用户每月的消费总金额变化图
month_amount = df.groupby(by='month')['order_amout'].sum().reset_index()
fig = px.line(month_amount,x='month',y='order_amout',title='用户每月的消费总金额')
fig.show()
2.2 所有用户每月的消费总次数(原始数据中的一行数据表示一次消费记录)
# 所有用户每月的消费总次数(原始数据中的一行数据表示一次消费记录)
df['month'].value_counts()1997-03-01 11598 1997-02-01 11272 1997-01-01 8928 1997-04-01 3781 1997-06-01 3054 1997-07-01 2942 1997-05-01 2895 1998-03-01 2793 1997-11-01 2750 1997-10-01 2562 1997-12-01 2504 1997-08-01 2320 1997-09-01 2296 1998-06-01 2043 1998-01-01 2032 1998-02-01 2026 1998-05-01 1985 1998-04-01 1878 Name: month, dtype: int64
2.3 用户每月的产品购买量变化图
# 用户每月的产品购买量变化图
month_product = df.groupby(by='month')['order_product'].sum().reset_index()
fig = px.line(month_product,x='month',y='order_product',title='用户每月的产品购买量变化图')
fig.show()
2.4 统计每月的消费人数(可能同一天一个用户会消费多次)nunique()表示统计去重后的个数
# 统计每月的消费人数(可能同一天一个用户会消费多次)nunique()表示统计去重后的个数
df.groupby(by='month')['user_id'].nunique()month 1997-01-01 7846 1997-02-01 9633 1997-03-01 9524 1997-04-01 2822 1997-05-01 2214 1997-06-01 2339 1997-07-01 2180 1997-08-01 1772 1997-09-01 1739 1997-10-01 1839 1997-11-01 2028 1997-12-01 1864 1998-01-01 1537 1998-02-01 1551 1998-03-01 2060 1998-04-01 1437 1998-05-01 1488 1998-06-01 1506 Name: user_id, dtype: int64
第三部分:用户个体消费数据分析
3.1 用户消费总金额和消费总次数的描述统计
# 用户消费总金额和消费总次数的描述统计
# 每一个用户消费的总金额
df.groupby(by='user_id')['order_amout'].sum()
# 每一个用户消费的总次数
df.groupby(by='user_id').count()['order_product']3.2 用户消费金额和消费次数的散点图
# 用户消费金额和消费次数的散点图
fig = px.scatter(df,x='order_amout',y='order_product',title='用户消费金额和消费次数的散点图')
fig.show()
3.3 每个用户的总消费次数和总消费金额的散点图
# 每个用户的总消费次数和总消费金额的散点图
user_sum = df.groupby(by='user_id')[['order_amout','order_product']].sum().reset_index()
fig = px.scatter(user_sum,x='order_product',y='order_amout',title='每个用户的总消费次数和总消费金额的散点图')
fig.show() 3.4 各个用户消费总金额的直方分布图(消费金额在1000之内的分布)
3.4 各个用户消费总金额的直方分布图(消费金额在1000之内的分布)
# 各个用户消费总金额的直方分布图(消费金额在1000之内的分布)
user_amout = df.groupby(by='user_id').sum().query('order_amout<=1000')['order_amout'].reset_index()
fig = px.histogram(user_amout,x='order_amout',nbins=10,opacity=0.5,
title='各个用户消费总金额的直方分布图(消费金额在1000之内的分布)',text_auto=True)
fig.show()
3.5 各个用户消费的总数量的直方分布图(消费商品数量在100次之内的分布)
# 各个用户消费的总数量的直方分布图(消费商品数量在100次之内的分布)
user_product = df.groupby(by='user_id').sum().query('order_product<=100')['order_product'].reset_index()
fig = px.histogram(user_product,x='order_product',nbins=10,title='各个用户消费的总数量的直方分布图(消费商品数量在100次之内的分布)'
,text_auto=True)
fig.show()
第四部分:用户消费行为分析
4.1 用户第一次消费的月份分布,和人数统计
# 用户第一次消费的月份分布,和人数统计
df_first = df[~df.duplicated('user_id',keep='first')]
df_first.groupby(by='month')['user_id'].count()month 1997-01-01 7846 1997-02-01 8476 1997-03-01 7248 Name: user_id, dtype: int64
4.2 用户最后一次消费的时间分布,和人数统计
# 用户最后一次消费的时间分布,和人数统计
df_last = df[~df.duplicated('user_id',keep='last')]['month'].value_counts().reset_index().sort_values('index')
df_last.rename(columns={'index':'month','month':'count'},inplace=True)
fig = px.line(df_last,x='month',y='count',title='用户最后一次消费的时间和人数分布')
fig.show()
4.3 新老客户的占比,消费一次为新用户,消费多次为老用户
# 新老客户的占比
# agg(['func1','func2']):对分组后的结果进行指定聚合
new_old_user = df.groupby(by='user_id')['order_date'].agg(['min','max'])
# 如果用户的第一次消费时间和最后一次消费的时间一样,则该用户只消费了一次为新用户,否则为老用户,这里可以使用np.where()
new_old_user['new_old'] = np.where(new_old_user['min']==new_old_user['max'],'new','old')
names = new_old_user.new_old.value_counts().index
values = new_old_user.new_old.value_counts().values
fig = px.pie(new_old_user,names=names,values=values,title='新老客户比')
fig.show()
4.4 分析得出每个用户的总购买量和总消费金额和最近一次消费时间的表格rfm
# 分析得出每个用户的总购买量和总消费金额和最近一次消费时间的表格rfm
rfm = df.pivot_table(index = 'user_id',
aggfunc = {'order_date':'max','order_amout':'sum','order_product':'sum'})
# R表示客户最近一次交易时间的间隔
rfm['R'] = -(rfm['order_date']-df['order_date'].max())/np.timedelta64(1,'D')
rfm.head()
# 对列名进行修改操作
rfm.rename(columns={'order_amout':'M','order_product':'F'},inplace=True)
rfm = rfm[['R','F','M']]
rfm.copy().head()
4.5 这里需要定义一个函数,针对RFM的表现进行8种类型的区分,RFM的标准都选择为其平均值
def rfm_func(x):
level=x.apply(lambda x:'1' if x>=0 else '0')
# level 的类型是 series,index 是 R、F、M
#print(type(level))
#print(level.index)
label=level.R + level.F + level.M
d={
# R为1表示比均值大,离最早时间近,F为1表示 消费金额比较多,M为1 表示消费频次比较多,所以是重要价值客户
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要发展客户',
'001':'重要挽留客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般发展客户',
'000':'一般挽留客户',
}
result=d[label]
return result
# 注意这里是要一行行的传递进来,所以 axis=1,传递一行得到一个111,然后匹配返回一个值
rfm['label']=rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
rfm.head()
通过创建RFM模型,可以有针对性的对不同类型用户采用不同的营销策略,进行精细化管理和运营。

总结:
RFM模型是目前衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的近期交易行为,交易频率以及交易金额这三项指标来描述该客户的价值状况,依据这三项指标划分8类客户类型,针对不同类型进行精准营销。














 2076
2076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









