






什么是网络爬虫?
简单来说,网络爬虫就是一段程序,它模拟人类访问互联网的形式,不停地从网络上抓取我们需要的数据。我们可以定制各种各样的爬虫,来满足不同的需求,如果法律允许,你可以采集在网页上看到的、任何你想要获得的数据。
网络爬虫是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。**网络搜索引擎等站点通过爬虫软件更新自身的网站内容或其对其他网站的索引。**网络爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引供用户搜索。
网络爬虫的作用
在大数据时代,信息的采集是一项重要的工作,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。 此时,我们可以使用网络爬虫对数据信息进行自动采集,比如应用于搜索引擎中对站点进行爬取收录,应用于数据分析与挖掘中对数据进行采集,应用于金融分析中对金融数据进行采集,除此之外,还可以将网络爬虫应用于舆情监测与分析、目标客户数据的收集等各个领域。
学习爬虫前的准备工作
1.选择一门爬虫语言,我选择python
2.开发平台和环境(linux和windows)
爬虫的过程
当人类去访问一个网页时,是如何进行的?
①打开浏览器,输入要访问的网址,发起请求。
②等待服务器返回数据,通过浏览器加载网页。
③从网页中找到自己需要的数据(文本、图片、文件等等)。
④保存自己需要的数据。
对于爬虫,也是类似的。它模仿人类请求网页的过程,但是又稍有不同。
首先,对应于上面的①和②步骤,我们要利用python实现请求一个网页的功能。
其次,对应于上面的③步骤,我们要利用python实现解析请求到的网页的功能。
最后,对于上面的④步骤,我们要利用python实现保存数据的功能。
如何用python请求一个网页
作为一门拥有丰富类库的编程语言,利用python请求网页完全不在话下。这里推荐一个非常好用的第三方类库requests。
如何安装reuquests?
打开命令提示符,输入下面代码
pip install requests
注意:要在python安装路径下进行安装,否则可能会报错
如何查看是否安装成功?
直接导入该模块,如果没有报错,则安装成功

进入实操:
import requests
resp=requests.get('https://www.baidu.com') #请求百度首页
print(resp) #打印请求结果的状态码
print(resp.content) #打印请求到的网页源码
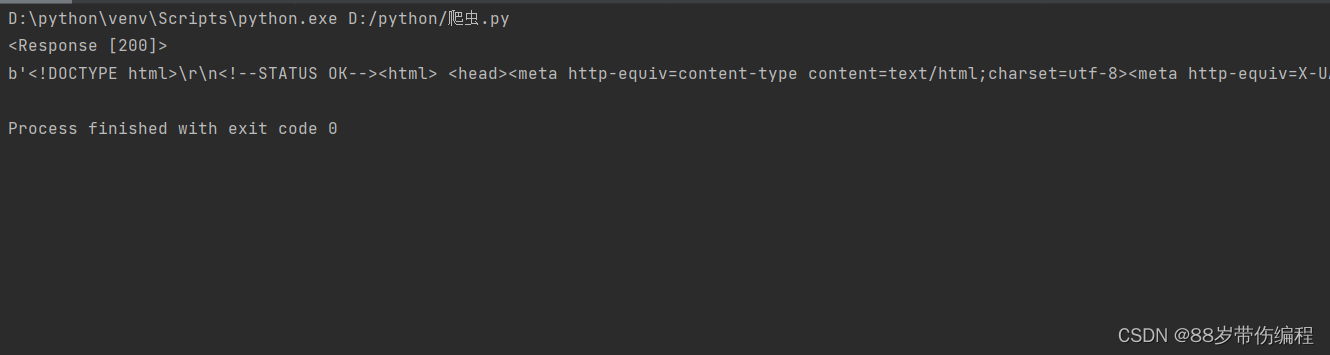
第1行:引入requests包。
第2行:使用requests类库,以get的方式请求网址链接:https://www.baidu.com,并将服务器返回的结果封装成一个对象,用变量resp来接收它。
第3行:一般可以根据状态码来判断是否请求成功,正常的状态码是200,异常状态码就很多了,比如404(找不到网页)、301(重定向)等。
第4行:打印网页的源码。注意,只是源码。不像是浏览器,在获取到源码之后,还会进一步地取请求源码中引用的图片等信息,如果有JS,浏览器还会执行JS,对页面显示的内容进行修改。使用requests进行请求,我们能够直接获取到的,只有最初始的网页源码。也正是因为这样,不加载图片、不执行JS等等,爬虫请求的速度会非常快。
解析网页源码
网页源码我们拿到了,接下来就是要解析了。python解析网页源码有很多种方法,比如BeautifulSoup、正则、pyquery、xpath等
安装BeautifulSoup

安装Ixml
1.首先在Windows下,尝试使用pip安装。 执行命令:pip install lxml 足够幸运的话,一次就会安装成功。
如果,上面那步没有正确,安装失败则只能采用wheel方式安装了。
首先查看pyhton适合的安装版本
如果你的电脑是64位的则输入命令:
import pip._internal
print(pip._internal.pep425tags.get_supported())
如果你的电脑是32位的则输入命令:
import pip
print(pip.pep425tags.get_supported())
然后去下图中的网址,下载对应的lxml
正则:
这个不用安装,标准库里带的就有。
正则的优点:①速度快 ②能够提取有些解析器提取不到的数据
正则的缺点:①不够直观,很难从面向对象的角度来考虑数据的提取 ②你得会写正则表达式
安装pyquery
这个解析器的语法和jQuery很相似,
输入下面代码
pip3 install pyquery
实操:
#coding=utf-8
import requests
from bs4 import BeautifulSoup
resp=requests.get('https://www.baidu.com') #请求百度首页
print(resp) #打印请求结果的状态码
print(resp.content) #打印请求到的网页源码
bsobj=BeautifulSoup(resp.content,'lxml') #将网页源码构造成BeautifulSoup对象,方便操作
a_list=bsobj.find_all('a') #获取网页中的所有a标签对象
for a in a_list:
print(a.get('href')) #打印a标签对象的href属性,即这个对象指向的链接地址
第3行,引入我们解析时要使用的类库,beautifulsoup4。
第9行,将网页的源码转化成了BeautifulSoup的对象,这样我们可以向操作DOM模型类似地去操作它。
第10行,从这个BeautifulSoup对象中,获取所有的a标签对象(大家应该知道a标签对象是什么吧,网页中的链接绝大多数都是a对象实现的),将他们组成一个列表,也就是a_list。
第11、12行,遍历这个列表,对于列表中的每一个a标签对象,获取它的属性href的值(href属性记录一个a标签指向的链接地址)。获取一个标签对象的属性,可以使用get(‘xx’)方法,比如a_tag是一个a标签对象,获取它的href的值,就是a_tag.get(‘href’),获取它的class信息可以用a_tag.get(‘class’),这将返回一个修饰该标签的class列表。
运行一下,可以看到,打印出了很多链接。

简单的保存数据
实操:
#coding=utf-8
import requests
from bs4 import BeautifulSoup
resp=requests.get('https://www.baidu.com') #请求百度首页
print(resp) #打印请求结果的状态码
print(resp.content) #打印请求到的网页源码
bsobj=BeautifulSoup(resp.content,'lxml') #将网页源码构造成BeautifulSoup对象,方便操作
a_list=bsobj.find_all('a') #获取网页中的所有a标签对象
text='' # 创建一个空字符串
for a in a_list:
href=a.get('href') #获取a标签对象的href属性,即这个对象指向的链接地址
text+=href+'\n' #加入到字符串中,并换行
with open('url.txt','w') as f: #在当前路径下,以写的方式打开一个名为'url.txt',如果不存在则创建
f.write(text) #将text里的数据写入到文本中
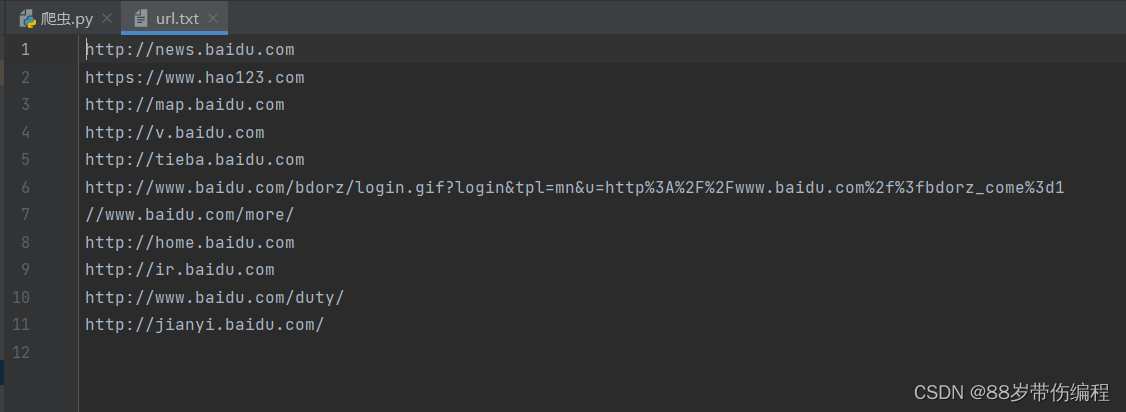
使用with…as…来打开文件,在操作完成后,会自动关闭文件,不用担心忘记关闭文件了
学习来源于https://blog.csdn.net/aaronjny/article/details/77885007















 2349
2349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









