







本次使用python进行断点回归
import pandas as pd
import numpy as np
file_path = 'dataforplot.csv'
data = pd.read_csv(file_path)
# Display the first few rows of the dataframe to understand its structure
data.head()
# 定义分段线性回归函数
def segmented_linear_regression(params, x):
k1, k2, bkpt = params
return np.piecewise(x, [x < bkpt, x >= bkpt], [lambda x: k1 * x, lambda x: k1 * bkpt + k2 * (x - bkpt)])
# 定义误差函数(最小化均方误差)
def error_function(params):
y_pred = segmented_linear_regression(params, x)
return np.sum((y - y_pred) ** 2)from scipy.optimize import minimize
# 初始参数猜测
initial_guess = [1, 1, 0.5]
# 最小化误差函数以找到最佳拟合参数
result = minimize(error_function, initial_guess, method='Nelder-Mead')
# 提取最佳参数
best_params = result.x
# 提取拟合的分割点和系数
best_k1, best_k2, best_bkpt = best_params
# 打印最佳拟合参数
print("最佳分割点:", best_bkpt)
print("第一段线性系数 (k1):", best_k1)
print("第二段线性系数 (k2):", best_k2)
绘制拟合结果
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号
# 生成拟合曲线的 x 值
x_break = np.linspace(min(x), max(x), 100)
# 计算拟合曲线的 y 值
y_pred = segmented_linear_regression(best_params, x_break)
# 创建图形
plt.figure(figsize=(10, 6), dpi=100) # 调整图形大小和 DPI
# 绘制数据点和拟合曲线
plt.scatter(x, y, label='数据点', color='blue')
plt.plot(x_break, y_pred, label='拟合曲线', color='red')
# 添加分割点的垂直线
plt.axvline(x=best_bkpt, color='black', linestyle='--', label='分割点')
# 设置轴标签和标题
plt.xlabel('x')
plt.ylabel('y')
plt.title('分段线性回归')
# 显示图例
plt.legend()
# 添加网格线
plt.grid(True, linestyle='--', alpha=0.6)
# 旋转 x 轴标签
plt.xticks(rotation=45)
# 显示图形
plt.show()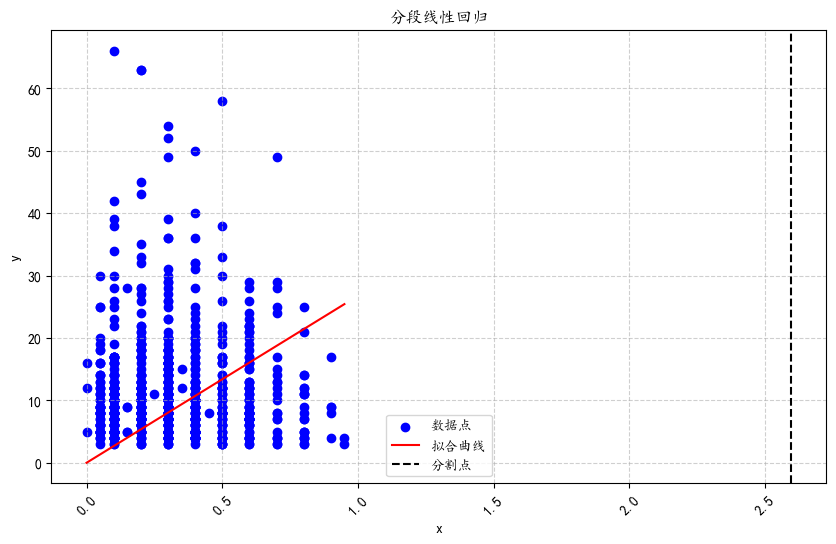
接下来对结果进行优化
# 统计方法识别异常值
# 计算数据的均值和标准差
x_mean, x_std = np.mean(x), np.std(x)
y_mean, y_std = np.mean(y), np.std(y)
# 定义用于判断异常值的阈值
# 在这里,我们使用距离均值2个标准差的范围作为常见的阈值
x_thresholds = (x_mean - 2 * x_std, x_mean + 2 * x_std)
y_thresholds = (y_mean - 2 * y_std, y_mean + 2 * y_std)
# 识别异常值
outliers = ((x < x_thresholds[0]) | (x > x_thresholds[1]) |
(y < y_thresholds[0]) | (y > y_thresholds[1]))
# 总结结果
outliers_indices = np.where(outliers)[0]
num_outliers = np.sum(outliers)
# 创建一个新的数据集,不包含异常值,用于进一步分析
data_cleaned = data[~outliers]
# 报告结果并显示经过清理的数据集
num_outliers, outliers_indices, data_cleaned.head()
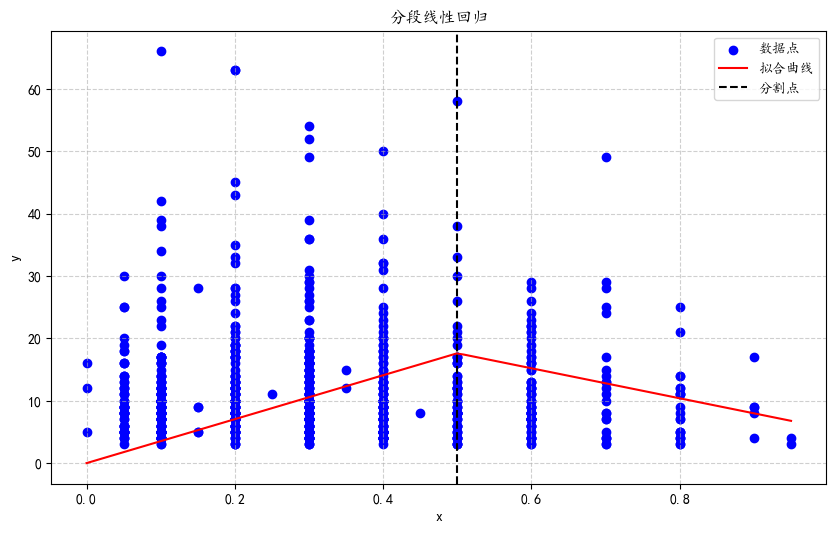
手动分割点看看
# 定义分段线性回归函数,使用硬编码的分割点为0.5
def segmented_linear_regression(params, x):
k1, k2 = params
# 分割点硬编码为0.5
bkpt = 0.5
# 定义分段线性函数
f1 = lambda x: k1 * x
f2 = lambda x: k1 * bkpt + k2 * (x - bkpt)
# 应用分段线性函数
return np.piecewise(x, [x < bkpt, x >= bkpt], [f1, f2])
# 定义误差函数以进行优化
def error_function(params, x, y):
y_pred = segmented_linear_regression(params, x)
return np.sum((y - y_pred) ** 2)
# 准备优化所需的数据
x_values = data['x'].values.reshape(-1, 1)
y_values = data['y'].values
# 检查x_values的大小是否合适
if np.prod(x_values.shape) > 1e6: # 根据系统的内存容量调整此值
raise MemoryError("输入数据太大,可能会导致内存问题。")
# 初始猜测参数
initial_guess = [1, 1]
# 尝试进行优化以捕获内存错误
try:
# 最小化误差函数以找到最佳拟合参数
result = minimize(error_function, initial_guess, args=(x_values, y_values), method='Nelder-Mead')
# 提取最佳拟合参数
best_params = result.x
best_k1, best_k2 = best_params
# 创建用于绘制拟合曲线的范围
x_range = np.linspace(np.min(x_values), np.max(x_values), 100)
# 绘制数据点和拟合曲线
plt.figure(figsize=(10, 6), dpi=100)
plt.scatter(x_values, y_values, label='数据点', color='blue')
plt.plot(x_range, segmented_linear_regression(best_params, x_range), label='拟合曲线', color='red')
plt.axvline(x=0.5, color='black', linestyle='--', label='分割点')
plt.xlabel('x')
plt.ylabel('y')
plt.title('分段线性回归')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()
except MemoryError as e:
print("发生内存错误: {}".format(e))
创作不易,希望大家多多点赞关注和收藏!谢谢


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









