







文章目录
常见加密算法总结-base系列部分
附上链接
参考学长的:https://the_itach1.gitee.io/2021/01/18/%E4%B8%80%E4%BA%9B%E5%B8%B8%E7%94%A8%E7%AE%97%E6%B3%95/
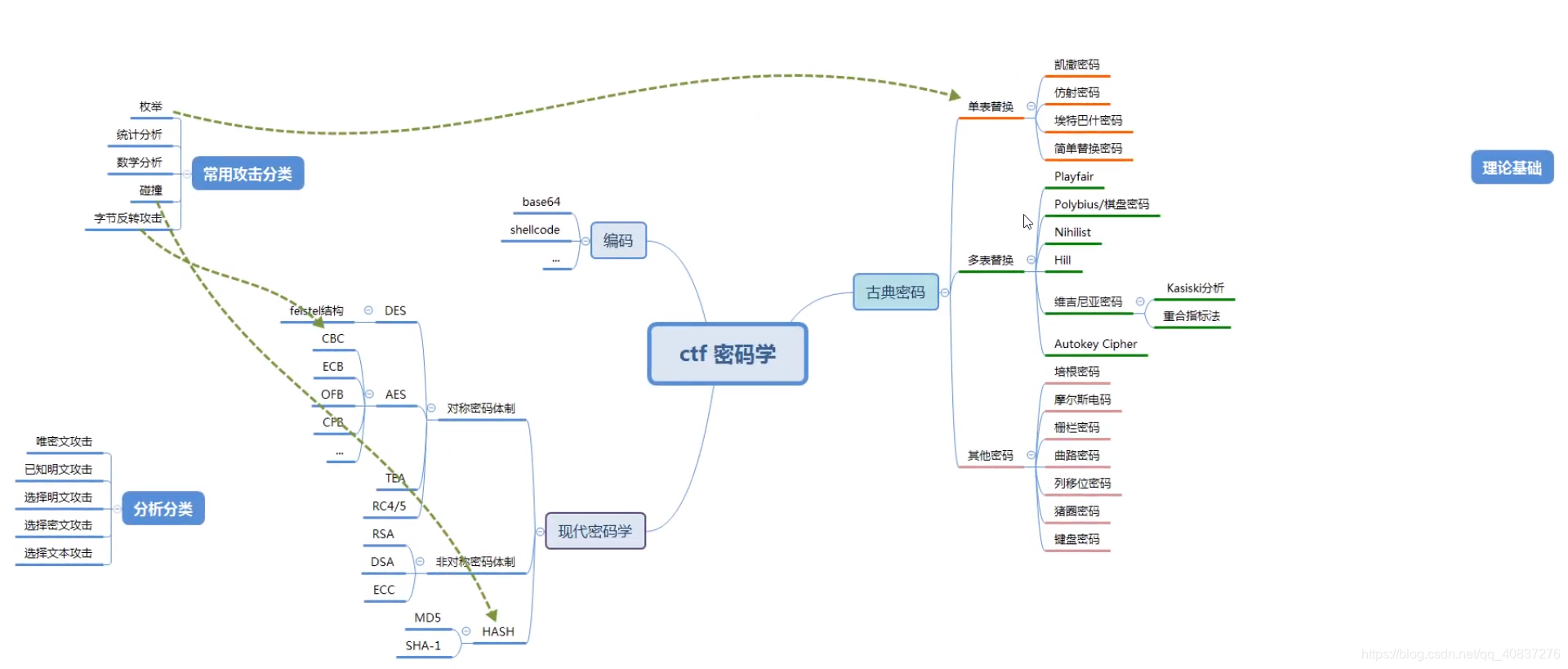
自己的总结
base系列编码
base64
介绍
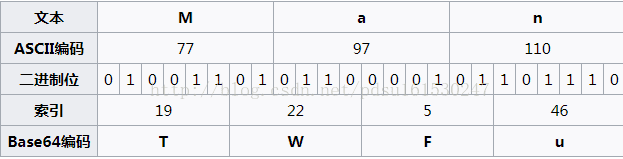
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,base64就是一种基于64个可打印字符来表示二进制数据的表示方法。由于2的6次方等于64,所以每6个比特为一个单元,对应某个可打印字符。三个字节有24个比特,对应4个base64单元,即3个字节可表示4个可打印字符。它可用来作为电子邮件的传输编码。
字典

加密
原理图
加密代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/* run this program using the console pauser or add your own getch, system("pause") or input loop */
int main(int argc, char *argv[]) {
char str1[200] = {0};
gets(str1);
unsigned char *str2;
int len1;
int len2;
int i,j;
unsigned char *table="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwzyz0123456789+/";
len1=strlen(str1);
//确定加密后的字符个数
if(len1%3!=0)
{
len2=(len1/3+1)*4;
}
else
{
len2=(len1/3)*4;
}
str2=malloc(sizeof(unsigned char)*len2+1);
str2[len2]='\0';
//下面的循环加密是以24位为一个周期进行的(3*8 == 4*6 的道理,具体看可看原理图)
for(i=0,j=0;i<len1;i+=3,j+=4)
{
str2[j]=table[str1[i]>>2];
//将待加密的第一个字符(binary)右移2位(保留其前六位对应一个base64编码字符)
str2[j+1]=table[(((str1[i]&3)<<4)|(str1[i+1]>>4))];
//将待加密的第二个字符保留其二进制的后两位(&3),再左移4位,由此得到的六位对应一个base64编码字符
str2[j+2]=table[((str1[i+1]&15)<<2)|(str1[i+2]>>6)];
//此时第二个待加密的字符还剩下四个二进制位没有参与编码,所以&15保留第二个待加密字符的后4位,再左移两位使其变成六位中的高四位,再和第三个待加密字符右移六位后剩下的前两位合并,对应一个base64编码字符
str2[j+3]=table[str1[i+2]&63];
//保留最后一个待加密字符的后6位对应一个base64编码字符
}
printf("length:%d\n",len2); //加密后长度
switch(len1%3)
{
case 1:
str2[len2-2]='=';
str2[len2-1]='=';
break;
case 2:
str2[len2-1]='=';
break;
}
for(i=0;i<len2;i++)
{
printf("%c",str2[i]);
}
return 0;
}
关键代码是这部分,要牢记他的样子以便于后面可以识别出来,或者是魔改版本的。
for(i=0,j=0;i<len1;i+=3,j+=4)
{
str2[j]=table[str1[i]>>2];
//将待加密的第一个字符(binary)右移2位(保留其前六位对应一个base64编码字符)
str2[j+1]=table[(((str1[i]&3)<<4)|(str1[i+1]>>4))];
//将待加密的第二个字符保留其二进制的后两位(&3),再左移4位,由此得到的六位对应一个base64编码字符
str2[j+2]=table[((str1[i+1]&15)<<2)|(str1[i+2]>>6)];
//此时第二个待加密的字符还剩下四个二进制位没有参与编码,所以&15保留第二个待加密字符的后4位,再左移两位使其变成六位中的高四位,再和第三个待加密字符右移六位后剩下的前两位合并,对应一个base64编码字符
str2[j+3]=table[str1[i+2]&63];
//保留最后一个待加密字符的后6位对应一个base64编码字符
}
解密
索引表
int main(void)
{
int i;
int table[]={0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,62,0,0,0,
63,52,53,54,55,56,57,58,
59,60,61,0,0,0,0,0,0,0,0,
1,2,3,4,5,6,7,8,9,10,11,12,
13,14,15,16,17,18,19,20,21,
22,23,24,25,0,0,0,0,0,0,26,
27,28,29,30,31,32,33,34,35,
36,37,38,39,40,41,42,43,44,
45,46,47,48,49,50,51
};
char str[]={'A','B','C','D','E','F','G','H',
'I','J','K','L','M','N','O','P','Q','R','S',
'T','U','V','W','X','Y','Z','a','b','c','d','e'
,'f','g','h','i','j','k','l','m','n','o','p','q',
'r','s','t','u','v','w','x','y','z','0','1','2','3','4',
'5','6','7','8','9','+','/'};
for(i=0;i<64;i++)
{
printf("%d ",table[str[i]]);
}
}
解密代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/* run this program using the console pauser or add your own getch, system("pause") or input loop */
int main(int argc, char *argv[]) {
char str1[200];
gets(str1);
unsigned char *str2;
int table[]={0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,62,0,0,0,
63,52,53,54,55,56,57,58,
59,60,61,0,0,0,0,0,0,0,0,
1,2,3,4,5,6,7,8,9,10,11,12,
13,14,15,16,17,18,19,20,21,
22,23,24,25,0,0,0,0,0,0,26,
27,28,29,30,31,32,33,34,35,
36,37,38,39,40,41,42,43,44,
45,46,47,48,49,50
};
int len1;
int len2;
int i,j;
len1=strlen(str1);
if(strstr(str1,"=="))
{
len2=(len1/4)*3-2;
}
else if(strstr(str1,"="))
{
len2=(len1/4)*3-1;
}
else
{
len2=(len1/4)*3;
}
str2=malloc(sizeof(unsigned char)*len2+1);
str2[len2]='\0';
for(i=0,j=0;i<len1-2;i+=4,j+=3)
{
str2[j]=((table[str1[i]])<<2)|((table[str1[i+1]])>>4);
str2[j+1]=(table[str1[i+1]]<<4)|((table[str1[i+2]])>>2);
str2[j+2]=((table[str1[i+2]])<<6)|(table[str1[i+3]]);
}
printf("%d",len2);
for(i=0;i<len2;i++)
{
printf("%c",str2[i]);
}
return 0;
}
以上即为base64编码。
base32
原文链接:https://blog.csdn.net/securitit/article/details/106934385
介绍
Base32编码使用32个ASCII字符对任何数据进行编码,Base32与Base64的实现原理类似,同样是将原数据二进制形式取指定位数转换为ASCII码。首先获取数据的二进制形式,将其串联起来,每5个比特为一组进行切分,每一组内的5个比特可转换到指定的32个ASCII字符中的一个,将转换后的ASCII字符连接起来,就是编码后的数据。
字典一
2^5+1 = 33 个元素

Base32还提供了另外一种字典定义,即Base32十六进制字母表。Base32十六进制字母表是参照十六进制的计数规则定义,两种字典没有本质的区别,只是字典不同而已。
字典二

加密
原理图

#include<stdio.h>
#include<string.h>
int main(int argc, char *argv[])
{
char date[100]="bacde";
char code[100];
unsigned char table[33]="ABCDEFGHIJKLMNOPQRSTUVWXYZ234567";
int len_date,len_code,i,j,num;
len_date=strlen(date);
printf("length of date=%d\n",len_date);
printf("date: %s\n",date);
if(len_date%5!=0)
{
len_code=(len_date/5+1)*8;
}
else
{
len_code=(len_date/5)*8;
}
for(i=0,j=0;i<len_code;i+=5,j+=8)
{
code[j]=table[date[i]>>3];
code[j+1]=table[((date[i]&7)<<2)|(date[i+1]>>6)];
code[j+2]=table[(date[i+1]>>1)&31];
code[j+3]=table[(date[i+1]&1)<<4|date[i+2]>>4];
code[j+4]=table[(date[i+2]&15)<<1|date[i+3]>>7];
code[j+5]=table[(date[i+3]>>2)&31];
code[j+6]=table[(date[i+3]&3)<<3|date[i+4]>>5];
code[j+7]=table[date[i+4]&31];
}
num=len_date%5;
switch(num)
{
case 1:
for(i=1;i<8-num;i++)
{
code[len_code-i]='=';
}
break;
case 2:
for(i=1;i<7-num;i++)
{
code[len_code-i]='=';
}
break;
case 3:
for(i=1;i<7-num;i++)
{
code[len_code-i]='=';
}
break;
case 4:
code[len_code-1]='=';
break;
}
printf("length of code =%d\n",len_code);
printf("the code:");
for(i=0;i<len_code;i++)
{
printf("%c",code[i]);
}
}
解密
#include<stdio.h>
#include<string.h>
int main(void)
{
char code[100]="MJQXG3LTMZZWCZQ=";
char date[100];
int table[]={0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,
0,0,0,26,27,28,29,30,
31,0,0,0,0,0,0,0,0,0,0,
1,2,3,4,5,6,7,8,9,10,11,12,
13,14,15,16,17,18,19,20,21,
22,23,24,25
};
int len_date,len_code,i,j,num;
len_code=strlen(code);
printf("length of code=%d\n",len_code);
printf("code :\n%s\n",code);
if(strstr(code,"======"))
{
len_date=(len_code/8)*5-4;
}
else if(strstr(code,"===="))
{
len_date=(len_code/8)*5-3;
}
else if(strstr(code,"==="))
{
len_date=(len_code/8)*5-2;
}
else if(strstr(code,"="))
{
len_date=(len_code/8)*5-1;
}
else
{
len_date=(len_code/8)*5;
}
for(i=0,j=0;j<len_date;i+=8,j+=5)
{
date[j]=table[code[i]]<<3|table[code[i+1]]>>2;
date[j+1]=table[code[i+1]]<<6|table[code[i+2]]<<1|table[code[i+3]]>>4;
date[j+2]=table[code[i+3]]<<4|table[code[i+4]]>>1;
date[j+3]=table[code[i+4]]<<7|table[code[i+5]]<<2|table[code[i+6]]>>3;
date[j+4]=table[code[i+6]]<<5|table[code[i+7]];
}
printf("length of date=%d\n",len_date);
printf("date:\n");
for(i=0;i<len_date;i++)
{
printf("%c",date[i]);
}
}
同样要熟悉关键部分代码
for(i=0,j=0;j<len_date;i+=8,j+=5)
{
date[j]=table[code[i]]<<3|table[code[i+1]]>>2;
date[j+1]=table[code[i+1]]<<6|table[code[i+2]]<<1|table[code[i+3]]>>4;
date[j+2]=table[code[i+3]]<<4|table[code[i+4]]>>1;
date[j+3]=table[code[i+4]]<<7|table[code[i+5]]<<2|table[code[i+6]]>>3;
date[j+4]=table[code[i+6]]<<5|table[code[i+7]];
}
base16
介绍
Base16编码就是将ASCII字符集中可打印的字符(数字0-9和字母A-F)对应的二进制字节数据进行编码,编码的方式:
先将数据(根据ASCII编码,UTF-8编码等)转成对应的二进制数,不足8比特位高位补0.然后将所有的二进制全部串起来,4个二进制位为一组,转化成对应十进制数.
再根据十进制数值找到Base16编码表里面对应的字符.Base16是4个比特位表示一个字符,所以原始是1个字节(8个比特位)刚好可以分成两组,也就是说原先如果使用ASCII编码后的一个字符,现在转化成两个字符. 数据量是原先的2倍.
编码表

加密
原理图

代码
#include<stdio.h>
#include<string.h>
int main(void)
{
char date[100]="bacde";
char code[100];
unsigned char table[17]="0123456789ABCDEF";
int len_date,len_code,i,j,num;
len_date=strlen(date);
printf("length of date :\n%d\n",len_date);
printf("date:\n%s\n",date);
len_code=len_date*2;
for(i=0,j=0;i<len_date;i++,j+=2)
{
code[j]=table[date[i]>>4];
code[j+1]=table[date[i]&15];
}
printf("length of code:\n%d\n",len_code);
printf("code: \n");
for(i=0;i<len_code;i++)
{
printf("%c",code[i]);
}
}
base58
编码
via: https://blog.csdn.net/qq_40890756/article/details/89159641
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char *en_base58(unsigned char *input) // 编码
{
static char *nb58 = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz";
size_t len = strlen(input);
size_t rlen = (len / 2 + 1) * 3;
unsigned char *ret = malloc(rlen + len);
unsigned char *src = ret + rlen;
unsigned char *rptr = ret + rlen;
unsigned char *ptr, *e = src + len - 1;
size_t i;
memcpy(src, input, len);
while(src <= e)
{
if(*src)
{
unsigned char rest = 0;
ptr = src;
while(ptr <= e)
{
unsigned int c = rest * 256;
rest = (c + *ptr) % 58;
*ptr = (c + *ptr) / 58;
ptr++;
}
--rptr;
*rptr = nb58[rest];
}
else
{
src++;
}
}
for(i = 0; i < ret + rlen - rptr; i++)
ret[i] = rptr[i];
ret[i] = 0;
return ret;
}
char *de_base58(unsigned char *src) // 解码
{
static char b58n[] =
{
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, -1, -1, -1, -1, -1, -1,
-1, 9, 10, 11, 12, 13, 14, 15, 16, -1, 17, 18, 19, 20, 21, -1,
22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, -1, -1, -1, -1, -1,
-1, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, -1, 44, 45, 46,
47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
};
size_t len = strlen(src);
size_t rlen = (len / 4 + 1) * 3;
unsigned char *ret = malloc(rlen);
unsigned char *rptr = ret + rlen;
size_t i;
unsigned char *ptr;
for(i = 0; i < len; i++)
{
char rest = b58n[src[i]];
if(rest < 0)
{
free(ret);
return NULL;
}
for(ptr = ret + rlen - 1; ptr >= rptr; ptr--)
{
unsigned int c = rest + *ptr * 58;
*ptr = c % 256;
rest = c / 256;
}
if(rest > 0)
{
rptr--;
if(rptr < ret)
{
free(ret);
return NULL;
}
*rptr = rest;
}
}
for(i = 0; i < ret + rlen - rptr; i++)
ret[i] = rptr[i];
ret[i] = 0;
return ret;
}
int main()
{
puts(en_base58("12345678"));
puts(de_base58("9EGJCxbxRGT"));
getchar();
return 0;
}















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











