






一、什么是MCP协议
1.MCP概念
MCP(model context protocol):模型上下文协议,它是一种社区共建的AI 开放协议,它标准化了应用向 AI 应用提供上下文的方式。目的是提供一个通用的开放标准,用来连接大语言模型和外部数据、行为。由 Anthropic 在 2024 年 11 月推出。
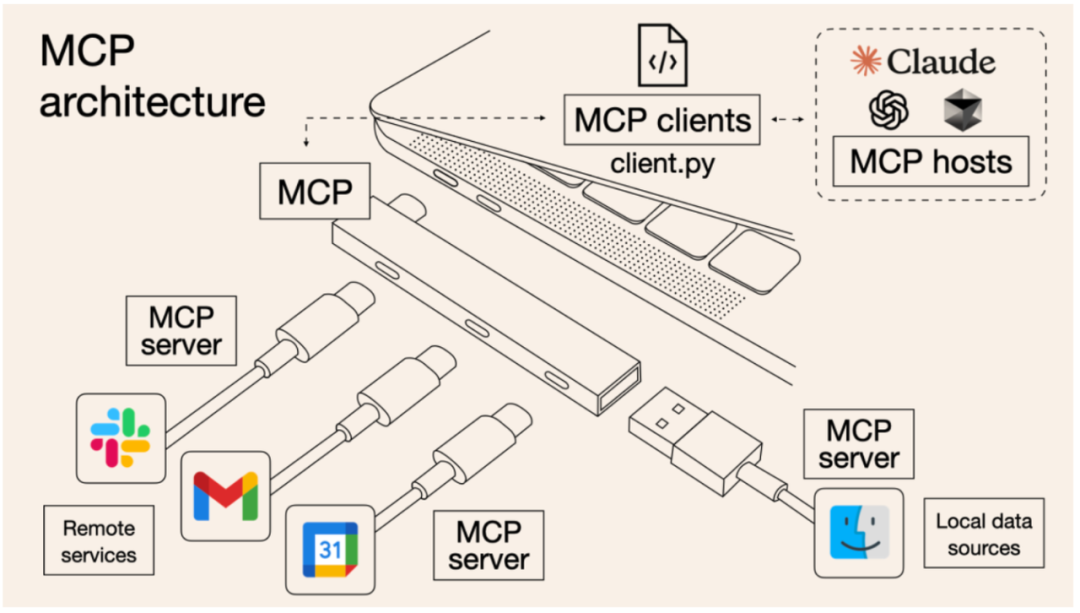
通俗点来说,MCP就是大模型与工具之间交流的一个协议,使用这个协议就可以让大模型去调用某个工具,让大模型具备自己本身不具备的功能,就比如说大模型本身是不能够获取到当前时间的,如果你有一个获取当前时间的工具,然后使用MCP协议,就可以让大模型获取到当前时间,然后进行输出。可以将MCP协议想象为一个Type-C接口,可以连接一个“型号”的工具。
通用架构:
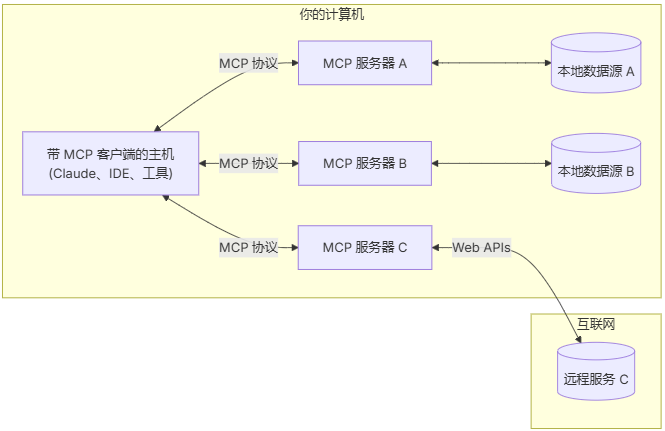
- MCP Hosts: 如 Claude Desktop、IDE 或 AI 工具,希望通过 MCP 访问数据的程序
- MCP Clients: 维护与服务器一对一连接的协议客户端
- MCP Servers: 轻量级程序,通过标准的 Model Context Protocol 提供特定能力
- 本地数据源: MCP 服务器可安全访问的计算机文件、数据库和服务
- 远程服务: MCP 服务器可连接的互联网上的外部系统(如通过 APIs)
2.MCP的使用方式
MCP 简介 - MCP 中文文档![]() https://mcp-docs.cn/introduction
https://mcp-docs.cn/introduction
二、如何构建智能体
1.智能体概念
智能体的发展是近几年以及未来的趋势,许多公司致力于研究出具有全面功能的智能体。智能体(Agent)是指能够感知环境并采取行动以实现特定目标的代理体。 它可以是 软件 、 硬件 或一个 系统,具备自主性、适应性和交互能力。 智能体通过感知环境中的变化(如通过传感器或数据输入),根据自身学习到的知识和算法进行判断和决策,进而执行动作以影响环境或达到预定的目标。
2.openmanus
openmanus是manus出来过后进行复刻的,我也在本地体验了openmanus,其全自动完成任务、中间结果输出、调用各种工具等功能让人眼前一亮,
OpenManus 的一大亮点在于其本地智能体运行能力。你只需通过简单的终端指令输入任务,它便能迅速调用预先配置的语言模型(LLM),为你实现自动化的操作流程。无论是生成一段精妙的代码,还是对复杂的数据进行深度分析,亦或是执行网页交互任务,效果都十分不错。
我个人认为,openmanus应该就是使用了MCP协议。
如果对openmanus感兴趣的同学,可以去试一试:
三、示例
接下来给大家做一个MCP的使用示例:
本次示例是在windows系统下进行演示:
1. 创建文件夹
uv init mcp-client
cd mcp-client2.构建环境
MCP开发要求借助uv进行虚拟环境创建和依赖管理。uv 是一个Python 依赖管理工具,类似于 pip 和 conda,但它更快、更高效,并且可以更好地管理 Python 虚拟环境和依赖项。它的核心目标是替代 pip、venv 和 pip-tools,提供更好的性能和更低的管理开销。
pip install uv3.创建虚拟环境并且激活
uv venv myenv
myenv\Scripts\activate4.安装MCP
uv add mcp5.编写服务端
import json
import httpx
from typing import Any
from mcp.server.fastmcp import FastMCP
from datetime import datetime
import pytz
import os
# 初始化 MCP 服务器
mcp = FastMCP("WeatherServer")
print("服务器开始启动...")
# OpenWeather API 配置
OPENWEATHER_API_BASE = "https://api.openweathermap.org/data/2.5/weather"
API_KEY = "xxxxx"# 请替换为你自己的 OpenWeather API Key
USER_AGENT = "weather-app/1.0"
async def fetch_weather(city: str) -> dict[str, Any] | None:
"""
从 OpenWeather API 获取天气信息。
:param city: 城市名称(需使用英文,如 Beijing)
:return: 天气数据字典;若出错返回包含 error 信息的字典
"""
params = {
"q": city,
"appid": API_KEY,
"units": "metric",
"lang": "zh_cn"
}
headers = {"User-Agent": USER_AGENT}
async with httpx.AsyncClient() as client:
try:
response = await client.get(OPENWEATHER_API_BASE, params=params, headers=headers, timeout=30.0)
response.raise_for_status()
return response.json() # 返回字典类型
except httpx.HTTPStatusError as e:
return {"error": f"HTTP 错误: {e.response.status_code}"}
except Exception as e:
return {"error": f"请求失败: {str(e)}"}
def format_weather(data: dict[str, Any] | str) -> str:
"""
将天气数据格式化为易读文本。
:param data: 天气数据(可以是字典或 JSON 字符串)
:return: 格式化后的天气信息字符串
"""
# 如果传入的是字符串,则先转换为字典
if isinstance(data, str):
try:
data = json.loads(data)
except Exception as e:
return f"无法解析天气数据: {e}"
# 如果数据中包含错误信息,直接返回错误提示
if"error"in data:
return f"⚠️ {data['error']}"
# 提取数据时做容错处理
city = data.get("name", "未知")
country = data.get("sys", {}).get("country", "未知")
temp = data.get("main", {}).get("temp", "N/A")
humidity = data.get("main", {}).get("humidity", "N/A")
wind_speed = data.get("wind", {}).get("speed", "N/A")
# weather 可能为空列表,因此用 [0] 前先提供默认字典
weather_list = data.get("weather", [{}])
description = weather_list[0].get("description", "未知")
return (
f"🌍 {city}, {country}\n"
f"🌡 温度: {temp}°C\n"
f"💧 湿度: {humidity}%\n"
f"🌬 风速: {wind_speed} m/s\n"
f"🌤 天气: {description}\n"
)
@mcp.tool()
async def query_weather(city: str) -> str:
"""
输入指定城市的英文名称,返回今日天气查询结果。
:param city: 城市名称(需使用英文)
:return: 格式化后的天气信息
"""
data = await fetch_weather(city)
return format_weather(data)
#获取当前时间的工具
@mcp.tool()
async def get_current_time(timezone: str = "Asia/Shanghai") -> str:
"""
获取指定时区的当前时间(默认北京时间),无需任何输入参数。
示例调用场景:
- "现在几点了?"
- "当前北京时间是多少?"
- "告诉我现在的时间"
:return: 格式化后的时间字符串,包含时区信息
"""
try:
tz = pytz.timezone(timezone)
now = datetime.now(tz)
return f"⏰ 当前时间:{now.strftime('%Y-%m-%d %H:%M:%S')} ({tz.zone})"
except pytz.UnknownTimeZoneError:
return f"⚠️ 无效时区:{timezone}"
#在本地创建文件夹的工具
@mcp.tool()
async def create_directory(directory_path: str) -> str:
"""
在D盘创建指定路径的目录(支持多级创建)
示例合法调用:
- "在D盘创建data文件夹"
- "建立D:/project/docs目录"
拒绝场景:
- "在C盘创建temp文件夹" → 禁止非D盘操作
- "清空D盘" → 阻止危险操作
"""
try:
normalized_path = os.path.normpath(directory_path)
# 安全检测
if os.path.isabs(normalized_path):
drive, path_part = os.path.splitdrive(normalized_path)
# Windows系统专属限制
if os.name == 'nt':
if drive.upper() != 'D:':
return "⚠️ 安全限制:只允许在D盘创建目录"
# 路径深度检测(D:/data → depth=1)
path_depth = len([p for p in path_part.split(os.sep) if p])
if path_depth < 1:
return "⚠️ 安全限制:禁止创建根目录"
os.makedirs(normalized_path, exist_ok=True)
return f"✅ 目录创建成功:{normalized_path}"
except PermissionError:
return f"⚠️ 无权限创建目录:{directory_path}"
except Exception as e:
return f"⚠️ 操作失败:{str(e)}"
print("服务器启动成功")
if __name__ == "__main__":
# 以标准 I/O 方式运行 MCP 服务器
mcp.run(transport='stdio')6.编写客户端
import asyncio
import os
import json
from typing import Optional
from contextlib import AsyncExitStack
from openai import OpenAI
from dotenv import load_dotenv
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
import sys
# 加载 .env 文件,确保 API Key 受到保护
load_dotenv()
class MCPClient:
def __init__ (self):
"""初始化 MCP 客户端"""
self.exit_stack = AsyncExitStack()
self.openai_api_key = os.getenv("OPENAI_API_KEY") # 读取 OpenAI API Key
self.base_url = os.getenv("BASE_URL") # 读取 BASE YRL
self.model = os.getenv("MODEL") # 读取 model
if not self.openai_api_key:
raise ValueError("❌ 未找到 OpenAI API Key,请在 .env 文件中设置 OPENAI_API_KEY")
self.client = OpenAI(api_key=self.openai_api_key, base_url=self.base_url) # 创建OpenAI client
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
async def connect_to_server(self, server_script_path: str):
"""连接到 MCP 服务器并列出可用工具"""
is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("服务器脚本必须是 .py 或 .js 文件")
command = "python"if is_python else"node"
server_params = StdioServerParameters(
command=command,
args=[server_script_path],
env=None
)
# 启动 MCP 服务器并建立通信
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# 列出 MCP 服务器上的工具
response = await self.session.list_tools()
tools = response.tools
print("\n已连接到服务器,支持以下工具:", [tool.name for tool in tools])
async def process_query(self, query: str) -> str:
"""
使用大模型处理查询并调用可用的 MCP 工具 (Function Calling)
"""
messages = [{"role": "user", "content": query}]
response = await self.session.list_tools()
available_tools = [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
}
} for tool in response.tools]
# print(available_tools)
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
tools=available_tools
)
# 处理返回的内容
content = response.choices[0]
if content.finish_reason == "tool_calls":
# 如何是需要使用工具,就解析工具
tool_call = content.message.tool_calls[0]
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
# 执行工具
result = await self.session.call_tool(tool_name, tool_args)
print(f"\n\n[Calling tool {tool_name} with args {tool_args}]\n\n")
# 将模型返回的调用哪个工具数据和工具执行完成后的数据都存入messages中
messages.append(content.message.model_dump())
messages.append({
"role": "tool",
"content": result.content[0].text,
"tool_call_id": tool_call.id,
})
# 将上面的结果再返回给大模型用于生产最终的结果
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
)
return response.choices[0].message.content
return content.message.content
async def chat_loop(self):
"""运行交互式聊天循环"""
print("\n🤖 MCP 客户端已启动!输入 'quit' 退出")
while True:
try:
query = input("\n你: ").strip()
if query.lower() == 'quit':
break
response = await self.process_query(query) # 发送用户输入到 OpenAI API
print(f"\n🤖 OpenAI: {response}")
except Exception as e:
print(f"\n⚠️ 发生错误: {str(e)}")
async def cleanup(self):
"""清理资源"""
await self.exit_stack.aclose()
async def main():
if len(sys.argv) < 2:
print("Usage: python client.py <path_to_server_script>")
sys.exit(1)
client = MCPClient()
try:
await client.connect_to_server(sys.argv[1])
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
import sys
asyncio.run(main())7.接入大模型
uv add mcp openai python-dotenv8.编写.env环境文件
BASE_URL=https://api.siliconflow.cn/v1
MODEL=deepseek-ai/DeepSeek-V3
OPENAI_API_KEY="在此处输入你的apikey"9.启动命令
首先需要启动server.py文件
python server.py再启动客户端和服务文件
uv run ./client.py ./server.py四、总结
本次测试的工具有天气咨询、获取当前时间、在本地创建文件夹。测试时,因为Deepseek本身不支持function calling(函数调用),所以使用了硅基流动进行线上调用的方式。另外在测试的时候,构建提示词的时候可以告知大模型使用什么工具,这样的话,准确率会上升一些。

















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









